
Working in Support is not an easy task, each customer has adapted our products to best fit their needs and while this is a great advantage of open source software, it also broadens the spectrum of different configurations.
Over time, the typical support case has evolved. It’s not just a system with some failure or behavior that should be checked like individual system-level configuration, tuning, lifecycle management, master kits, etc. Now, it’s leaning towards the interactions between several systems like clustering, virtualization (Red Hat Virtualization) and finally cloud (OpenShift, OpenStack or combinations).
What does this mean for support? In short: a mess. Let me clarify: when in the past you tried to check for an issue, it was more or less just checking a sosreport containing the system information and the logs, but now with combined systems, working together to offer a solution, it could be a lot of them, for example:
-
Satellite and its capsules
-
Openshift nodes
-
Red Hat Virtualization manager, hypervisors and virtual machines
-
Openstack Controllers, Computes and Instances
-
etc.
And still, we work on a sosreport from each system...
How does support approach a customer case?
First of all, we recommend this Reference Guide for Engaging with Red Hat Support,
which may be seen as ‘obvious’ or ‘common sense’, but still needs to be reminded of from time to time.
Keep in mind that in support, we don’t have crystal balls that tell us magically all we need to know about the environment or the issue. As examples, some of the things we include:
-
Host XXXXX is not working
-
Nothing is working
-
Check host XXXXX
-
And so on.
That Reference Guide provides basics like:
-
What happened and what was observed?
-
When did it happen?
-
What does the whole environment look like? (to have an idea on how the systems interact)
-
How does it impact production? Is it repeating? etc.
Our primary tool to work with for collecting debug information--which is the first step toward problem resolution--is the sosreport.
So…we got sosreports, what’s next?
Sosreport is a compressed file which contains the most common requested information from a system, like:
-
Cpuinfo and other hardware information
-
Kernel cmdline
-
Disk space
-
Packages installed
-
Open ports
-
Etc.
Sosreport is a modular tool that runs lots of plugins that gather specific data. For example, in an OpenStack system, it gathers additional information from OpenStack services logs, or even if the credentials are loaded, it does query the API for more details and then prepares a tarball with all the data it has combined...and here comes the tricky part...
Traditionally as we were working on host-level issues mostly, it was ok to check for issues in individual systems, but when we scale to ‘building-block’ approach where a server or a group of servers are controlling what others do, you might get three3 or four4 sosreports for the “simplest” OpenStack deployment.
Our approach: Citellus
Many times, some issues are already known and it’s quite easy to locate them, but still time-consuming to rule out all the ‘simple’ or known issues (for example, article https://access.redhat.com/solutions/1598733 reports some of the ‘starting point’ documents to read to validate a deployment).
My colleague Robin Černín was working on a weekend shift and found himself to be checking the same files across different sosreports again and again, so he came up with some bash scripts do to the same checks performed manually and run them all together in an automated way. Citellus (named after European Ground squirrel) was created.
This idea was also expanded via some conversations with engineering about how to better handle checking for issues and then the project took shape:
-
Framework based in python (citellus.py) that allowed to do fancy parsing of options, filtering, parallel execution, json export, etc.
-
Plugins written in whatever thing executable (bash, python, ruby--you name it! ) - Citellus will only check the output.
-
Plugins conform to 3 outputs states (OK, SKIPPED, FAILED) and inherit all data required from the environment (CITELLUS_ROOT and CITELLUS_LIVE).
One very useful feature is that Citellus can be executed against live systems, enabling field consultants and engineers to check systems fast without adding extra steps like generating a sosreport. Most of the plugins are prepared to be executed against a sosreport or a live system.
Citellus in action
After this, the actual ‘citellus’ (https://citellus.org) look was shaped looking very similar to its origins, for example, here you can see the results of a citellus sosreport scan and the issues found:
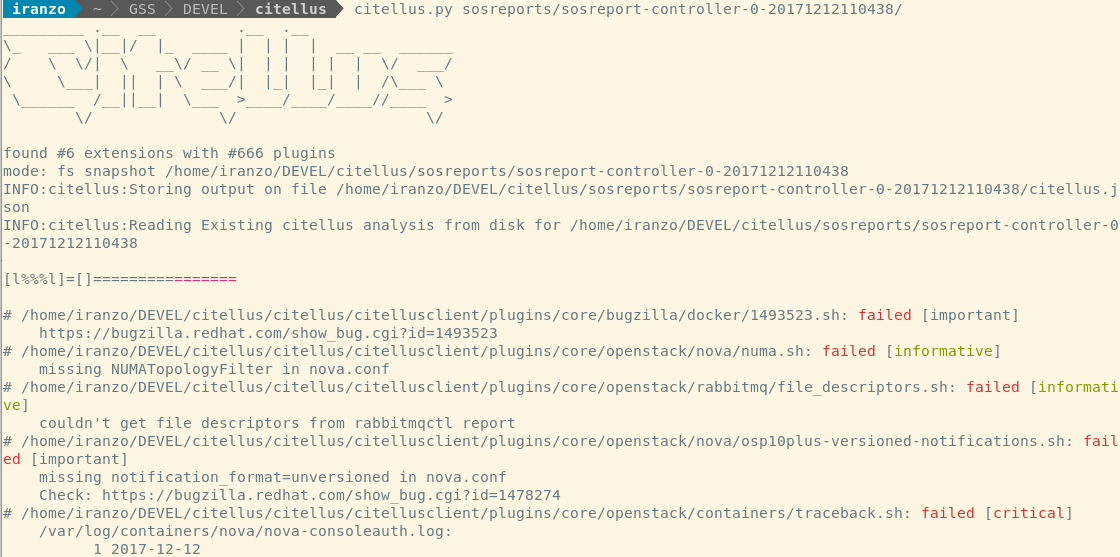
With this approach, it started to be very easy to add new tests quickly, and also empowered anyone, even with basic shell scripting skills to write new ones.
Also, a web interface was created (Thanks to our colleague David Vallee Delisle):
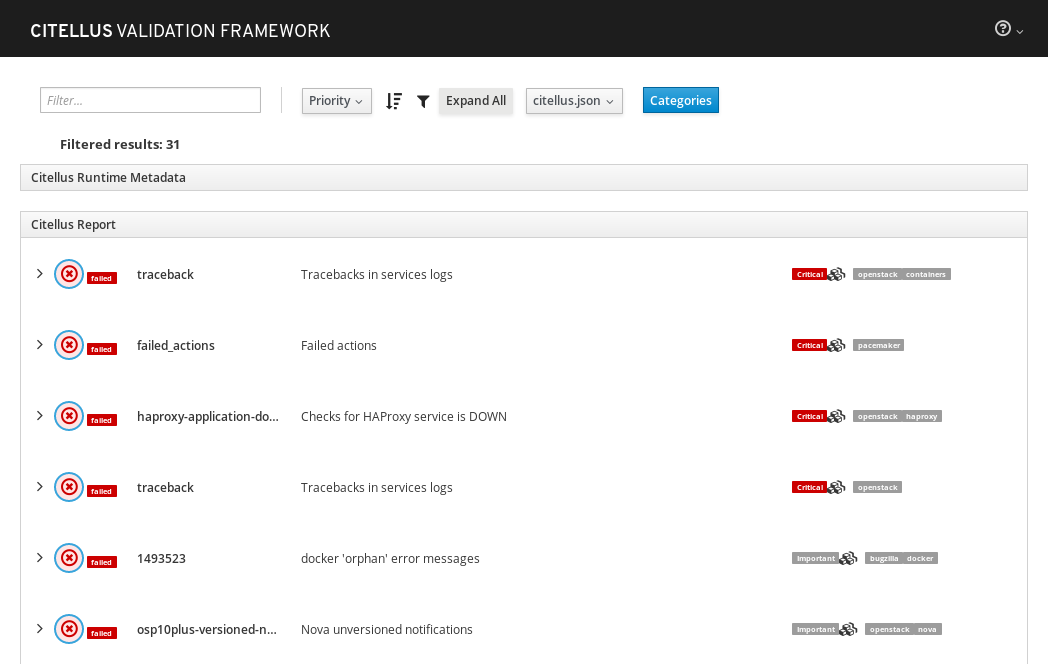
Since its inception, new features have been added to Citellus, such as:
-
Save results to json file and reuse those results for faster execution (rerunning only missing or modified plugins)
-
Ansible playbook support
-
Plugins for mangling data like setting ‘chronyd’ as skipped when there’s ‘ntpd’ running, etc
It’s already finished?
There was, however, a missing step: checking for servers inter-dependency issues. An auxiliary tool was created: ‘magui.py’ that efficiently reuses existing functions in Citellus but extends it to the ‘system-group’ level.
Additionally, we implemented a lot of new features thanks to the collaboration of our colleagues, and now we extended the functionality not to just group the results together from different systems, but also to:
-
highlight when files that are different shouldn’t be, or the other way around
-
group set of tests together creating ‘profiles’, like for example you would be checking when diagnosing a ‘cluster’ issue
-
Using Ansible and a playbook that copies Citellus, executes them and brings back the results from each host, system check can be automated to gather status of multiple live systems from a single point of control, all controlled from magui.py
This is still presented in json format, which allows easy external consumption (even our ‘www’ interface does use json to show the results in an easier way).
Current status
Citellus, now with more than 200 plugins (each covering one or more issues), is used daily by colleagues across the globe when diagnosing cases. It has been integrated into several systems we use for diagnosis and can be used in the same way by customers to surface useful troubleshooting data with minimal effort on a wide variety of issues.
Citellus has been presented to several groups and to some customers as one of the quick steps you can perform when hitting an issue or willing to do some health check on their systems and also upstream:
-
Devconf.CZ 2018: https://www.youtube.com/watch?v=SDzzqrUdn5A
-
SuperSec 2018
From that internal collaboration we also got new features:
-
Initial support for Debian based systems
-
Testing also for CentOS and RDO issues as it was very easy to adapt
-
A lot of new contributors!
Red Hat is an exciting place to work, and with the support of our managers and the collaborative environment between GEOS and teams, we are able to enhance the open source world with tools that also help us on our daily basis.
Additionally, with Citellus, we learned how to follow the upstream approach for other projects like OpenStack via implementing unit testing, code review, etc., to enhance code quality and catch common issues.
Want to quickly try it?
# citellus (each one is a valid method)
-
git clone https://github.com/citellusorg/citellus.git
-
citellus/citellus.py /path/to/sosreport # OR
-
sudo citellus/citellus.py -l # to run live against your system
-
Check README https://github.com/citellusorg/citellus/blob/master/README.citellus.md for more execution options
# for Magui
-
git clone https://github.com/citellusorg/citellus.git
-
citellus/magui.py /path/to/sosreport1 /path/to/sosreport2 …
-
Check README https://github.com/citellusorg/citellus/blob/master/README.magui.md for more execution options
Of course, if any problem is found, you’re invited to either raise an issue or to even submit patches to the project so that others can benefit from it: https://github.com/citellusorg/citellus/blob/master/CONTRIBUTING.md
If you want to keep up to date with our developments don’t forget to check https://citellus.org/


 David Vallée Delisle is a Technical Support Engineer for OpenStack in the U.S. David was a system administrator at Telco company for 13 years before joining Red Hat in 2017. He’s now learning to contribute his experience to the open source community. Find more posts by David Vallée Delisle at https://www.redhat.com/en/blog/authors/david-vallée-delisle
David Vallée Delisle is a Technical Support Engineer for OpenStack in the U.S. David was a system administrator at Telco company for 13 years before joining Red Hat in 2017. He’s now learning to contribute his experience to the open source community. Find more posts by David Vallée Delisle at https://www.redhat.com/en/blog/authors/david-vallée-delisleA Red Hat Technical Account Manager (TAM) is a specialized product expert who works collaboratively with IT organizations to strategically plan for successful deployments and help realize optimal performance and growth. The TAM is part of Red Hat’s world-class Customer Experience and Engagement organization and provides proactive advice and guidance to help you identify and address potential problems before they occur. Should a problem arise, your TAM will own the issue and engage the best resources to resolve it as quickly as possible with minimal disruption to your business.
Connect with TAMs at a Red Hat Convergence event near you! Red Hat Convergence is a free, invitation-only event offering technical users an opportunity to deepen their Red Hat product knowledge and discover new ways to apply open source technology to meet their business goals. These events travel to cities around the world to provide you with a convenient, local one-day experience to learn and connect with Red Hat experts and industry peers.
About the authors

Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges

Original shows
Entertaining stories from the makers and leaders in enterprise tech
Products
- Red Hat Enterprise Linux
- Red Hat OpenShift
- Red Hat Ansible Automation Platform
- Cloud services
- See all products
Tools
- Training and certification
- My account
- Customer support
- Developer resources
- Find a partner
- Red Hat Ecosystem Catalog
- Red Hat value calculator
- Documentation
Try, buy, & sell
Communicate
About Red Hat
We’re the world’s leading provider of enterprise open source solutions—including Linux, cloud, container, and Kubernetes. We deliver hardened solutions that make it easier for enterprises to work across platforms and environments, from the core datacenter to the network edge.
Select a language
Red Hat legal and privacy links
- About Red Hat
- Jobs
- Events
- Locations
- Contact Red Hat
- Red Hat Blog
- Diversity, equity, and inclusion
- Cool Stuff Store
- Red Hat Summit