As the adoption of Kubernetes continues to surge, organizations face the challenge of managing and scaling multiple clusters efficiently. Red Hat Advanced Cluster Management for Kubernetes is a powerful solution that simplifies cluster management and streamlines operations across the hybrid cloud environment. This blog post explores the key features and benefits of Red Hat Advanced Cluster Management, how it empowers organizations to unleash the full potential of Kubernetes, and how to set up high availability and disaster recovery for Red Hat Advanced Cluster Management.
What can Red Hat Advanced Cluster Management do?
Centralized management and visibility
Red Hat Advanced Cluster Management offers a centralized management platform that provides a holistic view of your Kubernetes clusters, regardless of location—on-premises, public cloud, or hybrid environments. This comprehensive visibility enables administrators to monitor, configure, and deploy applications consistently across multiple clusters from a single control plane. Red Hat Advanced Cluster Management saves valuable time and effort while offering a consistent and reliable deployment experience by eliminating the need for manual management of individual clusters.
Policy-based governance and compliance
Maintaining compliance and enforcing governance policies can be complex in a distributed Kubernetes environment. Red Hat Advanced Cluster Management simplifies this process by offering policy-based governance capabilities. Administrators can define and enforce policies spanning multiple clusters, enabling consistent security configurations, resource allocation, and compliance standards throughout the entire Kubernetes landscape. Red Hat Advanced Cluster Management provides a unified approach to managing and enforcing policies, reducing the risk of misconfigurations and enhancing security posture.
Application lifecycle management
Red Hat Advanced Cluster Management streamlines the application lifecycle management process, enabling organizations to deploy, manage, and update applications seamlessly across multiple clusters. With Red Hat Advanced Cluster Management, administrators can create application topologies, define deployment strategies, and automate the application rollout process. This simplifies the management of complex, multi-tiered applications and brings consistency across all clusters. Red Hat Advanced Cluster Management's application-centric approach makes it easier to handle application updates, scaling, and rollback, providing greater agility and reducing the time-to-market for new features.
Built-in observability and troubleshooting
Troubleshooting and monitoring Kubernetes clusters can be challenging, especially when dealing with a large-scale, distributed environment. Red Hat Advanced Cluster Management addresses this pain point by providing built-in observability features that help administrators gain insights into the health and performance of their clusters. From real-time monitoring to centralized logging and alerting, Red Hat Advanced Cluster Management offers a comprehensive set of tools to diagnose issues and perform root cause analysis. This visibility allows organizations to proactively identify and resolve problems, minimizing downtime and improving the overall reliability of their Kubernetes infrastructure.
High availability and disaster recovery
Suppose a Kubernetes environment consists of multiple clusters centrally administered by Red Hat Advanced Cluster Management. Knowing that such an important piece cannot be lost, it would be interesting to have a high availability and disaster recovery solution for Red Hat Advanced Cluster Management.
Red Hat Advanced Cluster Management can be tough to use if you don't know the basics. This article will explain everything you need to know to build a high availability and disaster recovery solution for Red Hat Advanced Cluster Management.
Before you get started
At the time of writing, the latest release of Red Hat Advanced Cluster Management is version 2.8. In this version, a standby cluster promoted to Active permanently replaces the old cluster that served in this role. The old cluster cannot be brought back online, as disaster recovery does not work this way. Disaster recovery processes occur when the primary site is lost. A function to have two Red Hat Advanced Cluster Management clusters online acting as Active/Standby is still under development.
Prerequisites
Red Hat Advanced Cluster Management requires the following resources:
- Three Infra Nodes
- 16 GB RAM
- 4 vCPU
- 120 GB Hard Disk
- Object Storage
Recommendations
Because Red Hat OpenShift is a comprehensive platform with many components, we recommend that Red Hat Advanced Cluster Management run on its own cluster that does not share OpenShift resources and workloads with other applications.
Sharing an OpenShift cluster for Red Hat Advanced Cluster Management with other solutions can make the restoration process more complex and costly, making it difficult to restore structures in the available time windows.
Regularly restore backups and activate a hub cluster standby to assimilate this process as best as possible.
Compatibility
On dedicated Red Hat Advanced Cluster Management clusters, OpenShift APIs for Data Protection must be at version 1.1.X for compatibility purposes.
OpenShift APIs for Data Protection in version 1.2.0 is not supported for clusters with Red Hat Advanced Cluster Management, as versions 1.1.X and 1.2.0 have different custom resource definitions (CRDs).
In version 1.2.0, there is a feature called status.phase that does not exist in version 1.1.X. This causes a compatibility issue where backups will stay in status.phase=InProgress.
Note: OpenShift APIs for Data Protection 1.2.0 can be used normally on clusters that do not have Red Hat Advanced Cluster Management.
High availability/disaster recovery architecture definition
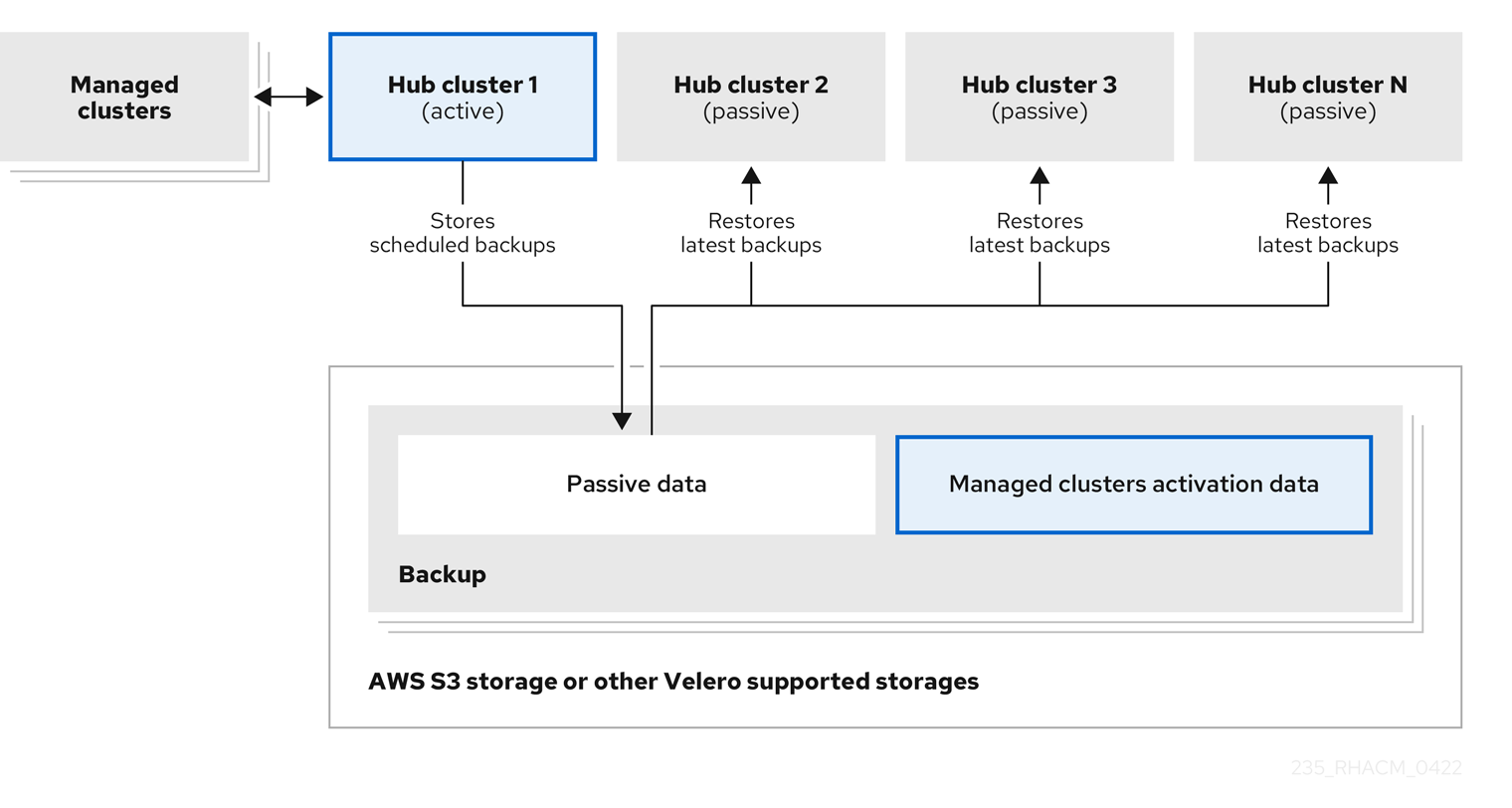
Typically, a high availability/disaster recovery architecture for Red Hat Advanced Cluster Management consists of a standard Active/Standby operation, with a primary cluster hub in a single location serving all resources required to deploy and manage individual OpenShift clusters on the network. In addition, there are N number of standby hub clusters in geographically separate locations, where backups of the primary cluster are continuously restored, leaving such standby replicas ready to assume operation as an active node (Primary) in case of failure.
Backups are stored on S3-compliant object storage, which must be accessible from all Red Hat Advanced Cluster Management hub clusters at all times. Such access is necessary for performing new backups and/or restoring data when required.
The primary hub cluster will back up Red Hat Advanced Cluster Management data based on a customer-defined schedule. The default is every two hours, but you can adjust it as needed.
Standby hub clusters will retrieve the most recent versions of backups stored in S3 and restore the information on their local clusters.
Cluster types:
- Hub Cluster: Red Hat Advanced Cluster Management itself.
- Managed Cluster: Clusters managed by the hub cluster.
High availability
The architecture is Active/Standby, as managed OpenShift clusters can contact only one hub cluster at a time for management purposes.
An Active/Active operation is not yet available as it requires structural changes regarding the internal database operation, which are still under development.
Switching
In the event of a failure in the primary cluster hub, the resource backups must be restored in a standby cluster hub, and the latter must be activated and promoted to a new primary cluster hub.
Upon activation, managed clusters will start sending their management information to this new hub cluster.
- The switching process is manual and must be initiated by an OpenShift administrator user.
Red Hat Advanced Cluster Management data restoration
It is important to note that the Red Hat Advanced Cluster Management backup and restore procedure described in this post only applies to data contained within Red Hat Advanced Cluster Management itself, such as cluster build custom resources (CRs), policies, and other related information.
- Custom configurations of OpenShift clusters, such as additional operators or any other custom configurations, are not covered in the Red Hat Advanced Cluster Management-related procedure, and therefore, such customizations will not be restored on Red Hat Advanced Cluster Management standby hub clusters.
- A complete restore of an OpenShift cluster is performed with a different procedure as it covers the platform as a whole.
OpenShift administrators must ensure that hub clusters have the same set of operators, CRDs, and other custom settings. Typically, this goal is achieved with GitOps, Argo CD, or other automation tools.
- It is recommended to keep Red Hat OpenShift and operator versions consistent across all Red Hat Advanced Cluster Management hub clusters for compatibility.
The cluster backup and restore operator is based on the OpenShift APIs for Data Protection operator and Velero solution. Many of the concepts from OpenShift APIs for Data Protection and Velero also apply to the Red Hat Advanced Cluster Management backup and restore procedure.
Generally speaking, all resources defined by a user for creating, managing, and maintaining clusters using Red Hat Advanced Cluster Management are backed up through the process outlined in this document.
Some features are not covered in this procedure, such as backup operator features and others that are not relevant to the operation of the primary Red Hat Advanced Cluster Management hub cluster.
For a complete list of all included and excluded features, please refer to this link.
Limitations
Only managed clusters created using the Hive API are automatically connected to a restored hub cluster. Managed clusters that were manually imported must be reconnected to the new hub cluster. In the future, I will cover a way to automate this process through the Managed Service Account feature.
Wrap up
At this point, I have covered the relevant details about basic compatibility, what is covered, and the limitations of the Red Hat Advanced Cluster Management high availability/disaster recovery process. The next post starts preparing the technical requirements.
About the author

Andre Rocha is a Consultant at Red Hat focused on OpenStack, OpenShift, RHEL and other Red Hat products. He has been at Red Hat since 2019, previously working as DevOps and SysAdmin for private companies.
More like this
The speed of trust: How global leaders are moving AI from lab to lifecycle
Scaling Earth and space AI models with Red Hat AI Inference Server and Red Hat OpenShift AI
Understanding AI Security Frameworks | Compiler
Data Security And AI | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds