
Large Language Model (LLM) inference has emerged as a crucial technology lately, influencing how enterprises approach AI-driven solutions driving new interest in integrating LLMs into enterprise applications. But when deploying LLMs in production environments, performance becomes paramount, with throughput (measured in tokens generated per second) on a GPU serving as a key metric. In principle, a model with higher throughput can accommodate a large user base for a given hardware infrastructure, while meeting specific latency and accuracy requirements, which ultimately reduces the cost of model deployment for end-users.
Red Hat, in collaboration with Supermicro, has made significant strides in addressing this challenge through the publication of impressive MLPerf inference results using Red Hat OpenShift AI with NVIDIA GPUs and the vLLM inference runtime. These results demonstrate the potential for high-performance and cost-effective LLM inference in an enterprise setting, empowering organizations to harness the full potential of Generative AI technologies.
What is MLPerf?
MLCommons is a collaboration of over 125 founding members and affiliates, including startups, leading companies, academics, and non-profits from around the globe, strives to democratize AI through open industry-standard benchmarks that measure quality and performance of the most popular open models and datasets. MLCommons publishes a benchmarking suite called MLPerf that aims to deliver a representative benchmarking suite for AI workloads that fairly evaluates AI model performance enabling fair comparison of competing systems and software solutions.
Red Hat OpenShift AI is a flexible, scalable MLOps platform with tools to build, deploy, and manage AI-enabled applications. Built using open source technologies, it provides trusted, operationally consistent capabilities for teams to experiment, serve models, and deliver innovative apps. OpenShift AI supports the full lifecycle of AI/ML experiments and models, on-premise and in the public cloud.
vLLM is a high-throughput and memory-efficient open-source library, using a kernel optimized for CUDA, for fast LLM inference and serving with PagedAttention. This enables processing long sequences by efficiently managing GPU memory. It also features continuous batching, which dynamically adjusts the batch size based on the available memory and computational resources. vLLM is flexible and has seamless integration with Hugging Face models, OpenAI compatibility. It supports both NVIDIA and AMD, and tensor parallelism for distributed inference.
MLPerf results
Red Hat has published two sets of results in the latest MLPerf 4.0 inference submission round in the open division. The first is an offline scenario result on the GPT-J 6 billion parameter model on our partner Supermicro’s hardware (specifically, a GPU A+ Server AS-4125GS-TRNT with 8xH100 PCIe GPUs and PCI interconnect). The other result is both offline and server scenarios for a newly introduced benchmark in MLPerf 4.0 for the Llama2-70 billion parameter model on NVIDIA’s DGX H100 machine with 8xH100 SXM GPUs with NVlink interconnect. Both submissions used unquantized and non-compiled versions of the models with the vLLM runtime. Both are leading results in their category of uncompiled and non-quantized models.
To run these benchmarks, we created a custom implementation of the MLPerf inference harness to work with OpenShift AI’s model serving stack that includes KServe for providing a high-level abstraction to AI/ML frameworks, as shown in Figure 1.
With Single Node OpenShift (SNO) installed on the System Under Test (DGX H100 / GPU A+ Server AS-4125GS-TRNT), our MLPerf inference implementation took full advantage of Red Hat OpenShift AI’s capabilities. The inference setup consisted of two instances of vLLM, each with a tensor parallelism of 4 (4 GPUs per instance), deployed seamlessly with KServe and Istio for application-aware networking, tied together through the OpenShift AI framework. Both vLLM instances had the original fp16 Llama2-70b model loaded. The benchmark driver pod, responsible for load generation and result accumulation, was running in a separate pod on the system, sending load over HTTP evenly to both vLLM instances. Our implementation of the benchmark driver is available on Github.
With Flash Attention for reduced GPU memory read/write, Paged Attention for reduced memory waste, and Continuous Batching for efficient resource utilization, vLLM provides high performance for both throughput and latency. With OpenShift and the add-on OpenShift AI product installed, this whole setup can be brought up with just a couple of YAML files.

Figure 1: MLPerf harness implementation for OpenShift AI
For the second test involving the GPT-J implementation, everything above remained the same except that we created eight instances of vLLM, one for each available H100 GPU.
Below are the results as published on the MLcommons website (choose the Open Division/Power drop-down menu).
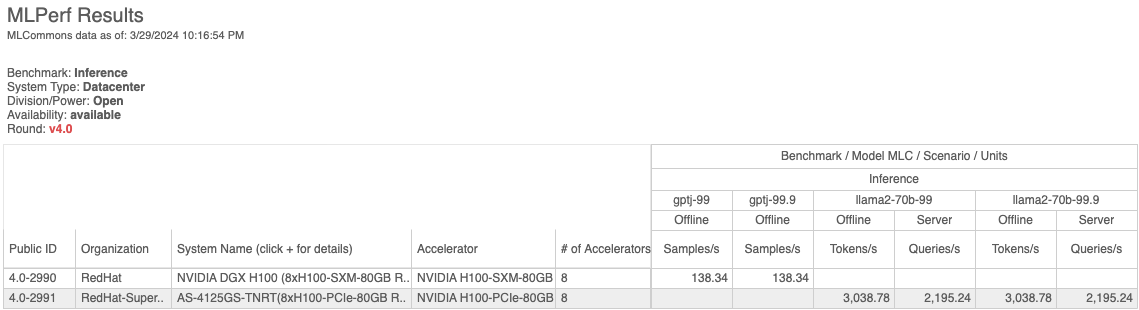
Figure 2: OpenShift AI results in the open division with vLLM
The results table shows that the tested configuration achieved 138 queries per second for the GPT-J benchmark, and over 3000 tokens per second for the Llama2-70B benchmark in offline mode with 99.9% accuracy. These results were achieved with an "out of the box” configuration, using the original FP16 model checkpoint weights.
The code and README.md for our submissions are available at https://github.com/mlcommons/inference_results_v4.0/tree/main/open/RedHat and https://github.com/mlcommons/inference_results_v4.0/tree/main/open/RedHat-Supermicro.
Next steps on OpenShift AI
Our future work includes building on this momentum to submit a variety of results in the next MLPerf 4.1 inference submission round on OpenShift AI with vLLM, as well as NVIDIA’s TensorRT-LLM inference runtime. We want to showcase the flexibility and performance of using OpenShift AI model serving stack as an abstraction layer for hosting LLMs in production.
Stay tuned for more exciting results from the OpenShift AI inference performance team! In the meantime, learn more about OpenShift AI, and sign up for a 60-day free trial here.
Acknowledgements
Nikola Nikolov and Jeff Liu at Super Micro Computer, Inc. were instrumental in helping us with this project. Nikola provided valuable guidance on running these workloads, and Jeff helped us around the clock with access to the hardware. We are grateful for their assistance and plan to continue collaborating with them on future benchmarking efforts.
About the authors

I am a software engineer focused on AI/ML performance on Kubernetes/OpenShift. I received my B.S. and M.S. in Computer Science from Columbia University, both with a focus on natural language processing and machine learning. I also work with IBM Research on various knowledge/data-related research topics.

Michey is a member of the Red Hat Performance Engineering team, and works on bare metal/virtualization performance and machine learning performance.. His areas of expertise include storage performance, Linux kernel performance, and performance tooling.

Diane Feddema is a Principal Software Engineer at Red Hat leading performance analysis and visualization for the Red Hat OpenShift Data Science (RHODS) managed service. She is also a working group chair for the MLCommons Best Practices working group and the CNCF SIG Runtimes working group.
She also creates experiments comparing different types of infrastructure and software frameworks to validate reference architectures for machine learning workloads using MLPerf™. Previously, Feddema was a performance engineer at the National Center for Atmospheric Research, NCAR, working on optimizations and tuning of parallel global climate models. She also worked at SGI and Cray on performance and compilers.
She has a bachelor's in Computer Science from the University of Iowa and master's in Computer Science from the University of Colorado.

Ashish Kamra is an accomplished engineering leader with over 15 years of experience managing high-performing teams in AI, machine learning, and cloud computing. He joined Red Hat in March 2017, where he currently serves as the Senior Manager of AI Performance at Red Hat. In this role, Ashish heads up initiatives to optimize performance and scale of Red Hat OpenShift AI - an end to end platform for MLOps, specifically focusing on large language model inference and training performance.
Prior to Red Hat, Ashish held leadership positions at Dell EMC, where he drove the development and integration of enterprise and cloud storage solutions and containerized data services. He also has a strong academic background, having earned a Ph.D. in Computer Engineering from Purdue University in 2010. His research focused on database intrusion detection and response, and he has published several papers in renowned journals and conferences.
Passionate about leveraging technology to drive business impact, Ashish is pursuing a Part-time Global Online MBA at Warwick Business School to complement his technical expertise. In his free time, he enjoys playing table tennis, exploring global cuisines, and traveling the world.

Nikola Nikolov is AI/HPC solutions engineer from Supermicro. Nikola received PhD in Nuclear Physics from the University of Knoxville, Tennessee focused on large-scale HPC computations in Nuclear Astrophysics at Oak Ridge National Laboratory under National Nuclear Security Administration (NNSA) Stewardship grant.
Before joining the industry, he spent last years in academics designing experiments with CERN Isolde collaboration and Cosmic Neutrino Detection with Los Alamos National Laboratory.
Prior to Supermicro, Nikola worked at KLA+ Inc. (former KLA-Tencor) as Big Data and ML developer in semiconductor industry. He designed HBase, Big-Table, and Data Lake infrastructures for Anomaly Detection and Failure Predictive analysis of semiconductor equipment. These Big-Data systems have been implemented successfully by major chip manufacturing companies like TSMC, Samsung, and SK Hynix.
Nikola has published both Peer-Reviewed academic articles in top scientific journals like Physical Review Letters and Nature, as well as engineering papers in Big Data management.
In the last 8 years he have focused mainly on public and hybrid cloud solutions with AWS and Google Cloud Platform. In Supermciro, Nikola works mostly into designing cutting edge AI/HPC infrastructure solutions as well as validating AI/HPC systems via MLPerf and HPC benchmarking.
Browse by channel

Automation
The latest on IT automation that spans tech, teams, and environments

Artificial intelligence
Explore the platforms and partners building a faster path for AI

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
Explore how we reduce risks across environments and technologies

Edge computing
Updates on the solutions that simplify infrastructure at the edge

Infrastructure
Stay up to date on the world’s leading enterprise Linux platform

Applications
The latest on our solutions to the toughest application challenges

Original shows
Entertaining stories from the makers and leaders in enterprise tech
Products
- Red Hat Enterprise Linux
- Red Hat OpenShift
- Red Hat Ansible Automation Platform
- Cloud services
- See all products
Tools
- Training and certification
- My account
- Developer resources
- Customer support
- Red Hat value calculator
- Red Hat Ecosystem Catalog
- Find a partner
Try, buy, & sell
Communicate
About Red Hat
We’re the world’s leading provider of enterprise open source solutions—including Linux, cloud, container, and Kubernetes. We deliver hardened solutions that make it easier for enterprises to work across platforms and environments, from the core datacenter to the network edge.
Select a language
Red Hat legal and privacy links
- About Red Hat
- Jobs
- Events
- Locations
- Contact Red Hat
- Red Hat Blog
- Diversity, equity, and inclusion
- Cool Stuff Store
- Red Hat Summit