
In der heutigen Welt ist es entscheidend, Kunden Services kontinuierlich und mit minimalen bis keinen Ausfällen zur Verfügung zu stellen. Das Red Hat Enterprise Linux (RHEL) High Availability Add-On unterstützt Sie dabei, dieses Ziel zu erreichen, indem es die Zuverlässigkeit, Skalierbarkeit und Verfügbarkeit von Produktionssystemen verbessert. Dies gelingt mithilfe von HA-Clustern (High Availability, Hochverfügbarkeit), die Single Points of Failure eliminieren und beim Ausfall eines Knotens in einem Service einen Failover zu einem anderen Cluster-Knoten durchführen.
In diesem Beitrag zeige ich, wie Sie die RHEL-Systemrolle ha_cluster zur Konfiguration eines HA-Clusters nutzen, der einen Apache HTTP-Server mit gemeinsamem Storage im Aktiv/Passiv-Modus ausführt.
RHEL-Systemrollen sind Ansible Roles und Ansible-Module, die in RHEL enthalten sind und konsistente Workflows bereitstellen, um die Ausführung manueller Aufgaben zu optimieren. Weitere Informationen zum RHEL-HA-Clustering finden Sie in der Dokumentation Konfigurieren und Verwalten von Hochverfügbarkeits-Clustern.
Überblick über die Umgebung
In meiner Beispielumgebung habe ich ein Kontrollknotensystem namens controlnode und zwei gemanagte Knoten, rhel8-node1 und rhel8-node2, die allesamt auf RHEL 8.6 ausgeführt werden. Die beiden gemanagten Knoten werden über einen APC-Netzschalter mit dem Hostnamen apc-switch eingeschaltet.
Ich möchte einen Cluster mit dem Namen rhel8-clustererstellen, der aus den Knoten rhel8-node1 und rhel8-node2 besteht. Der Cluster führt einen Apache HTTP-Server im Aktiv/Passiv-Modus mit einer Floating-IP-Adresse aus, die Seiten aus einem ext4-Dateisystem bereitstellt, das auf einem logischen LVM-Datenträger (Logical Volume Management) gemountet ist. Das Fencing wird über apc-switch bereitgestellt.
Beide Cluster-Knoten sind mit dem gemeinsamen Storage über ein ext4-Dateisystem verbunden, das auf einem logischen LVM-Volume gemountet ist. Auf beiden Knoten ist ein Apache HTTP-Server installiert und konfiguriert. Weitere Informationen finden Sie in den Kapiteln Konfigurieren eines LVM-Volumes mit einem ext4-Dateisystem in einem Pacemaker-Cluster und Konfigurieren eines Apache HTTP-Servers im Dokument Konfigurieren und Verwalten von Hochverfügbarkeits-Clustern.
Ich habe bereits auf allen 3 Servern ein Ansible-Dienstkonto mit dem Namen ansible eingerichtet. Die SSH-Schlüsselauthentifizierung habe ich dabei so eingerichtet, dass sich das ansible-Konto auf controlnode bei jedem Knoten anmelden kann. Zusätzlich wurde das Dienstkonto ansible so konfiguriert, dass es auf jedem Knoten über sudo Zugriff auf das Root-Konto hat. Außerdem habe ich die Pakete rhel-system-roles und ansible auf controlnode installiert. Weitere Informationen zu diesen Aufgaben finden Sie im Beitrag Einführung in RHEL-Systemrollen.
Definition von Inventory-Datei und Rollenvariablen
Im System controlnode muss zunächst eine neue Verzeichnisstruktur erstellt werden:
[ansible@controlnode ~]$ mkdir -p ha_cluster/group_vars
Diese Verzeichnisse werden wie folgt verwendet:
- Das Verzeichnis ha_cluster enthält das Playbook und die Inventory-Datei.
- Die Datei ha_cluster/group_vars enthält Variablendateien für Inventory-Gruppen, die auf Hosts in den entsprechenden Ansible-Inventory-Gruppen angewendet werden.
Ich muss eine Ansible-Inventory-Datei definieren, um die Hosts aufzulisten und zu gruppieren, für die die Systemrolle ha_cluster konfiguriert werden soll. Ich erstelle die Inventory-Datei unter ha_cluster/inventory.yml mit dem folgenden Inhalt:
---
all:
children:
rhel8_cluster:
hosts:
rhel8-node1:
rhel8-node2:Das Inventory definiert eine Inventory-Gruppe namens rhel8_cluster und weist die 2 gemanagten Knoten dieser Gruppe zu.
Als Nächstes definiere ich die Rollenvariablen, die das Verhalten der Systemrolle ha_cluster bei der Ausführung steuern. Die Datei README.md für die Rolle ha_cluster ist unter /usr/share/doc/rhel-system-roles/ha_cluster/README.md verfügbar und enthält wichtige Informationen über die Rolle, einschließlich einer Liste der verfügbaren Rollenvariablen und deren Verwendung.
Eine der Variablen, die für die Rolle ha_cluster definiert werden müssen, ist die Variable ha_cluster_hacluster_password. Sie legt das Passwort für die Benutzer von hacluster fest. Damit dieser Wert nicht im Klartext gespeichert wird, verschlüssele ich ihn mit Ansible Vault.
[ansible@controlnode ~]$ ansible-vault encrypt_string 'your-hacluster-password' --name ha_cluster_hacluster_password
New Vault password:
Confirm New Vault password:
ha_cluster_hacluster_password: !vault |
$ANSIBLE_VAULT;1.1;AES256 376135336466646132313064373931393634313566323739363365616439316130653539656265373663636632383930323230343731666164373766353161630a303434316333316264343736336537626632633735363933303934373666626263373962393333316461616136396165326339626639663437626338343530360a39366664336634663237333039383631326263326431373266616130626333303462386634333430666333336166653932663535376538656466383762343065
Encryption successfulErsetzen Sie your-hacluster-password durch das Passwort Ihrer Wahl. Wenn Sie den Befehl ausgeführt haben, werden Sie zur Eingabe eines Vault-Passworts aufgefordert, mit dem die Variable beim Ausführen des Playbooks entschlüsselt werden kann. Wenn Sie das Vault-Passwort eingegeben und durch die erneute Eingabe bestätigt haben, wird die verschlüsselte Variable in der Ausgabe angezeigt. Die Variable wird in der Variablendatei gespeichert, die im nächsten Schritt erstellt wird.
Jetzt erstelle ich eine Datei, die Variablen für meine Cluster-Knoten definiert, die in der Inventory-Gruppe rhel8_cluster aufgeführt sind. Dazu erstelle ich eine Datei unter ha_cluster/group_vars/rhel8_cluster.yml mit folgendem Inhalt:
---
ha_cluster_cluster_name: rhel8-cluster
ha_cluster_hacluster_password: !vault |
$ANSIBLE_VAULT;1.1;AES256
3761353364666461323130643739313936343135663237393633656164393161306535
39656265373663636632383930323230343731666164373766353161630a3034343163
3331626434373633653762663263373536393330393437366662626337396239333331
6461616136396165326339626639663437626338343530360a39366664336634663237
3330393836313262633264313732666161306263333034623866343334306663333361
66653932663535376538656466383762343065
ha_cluster_fence_agent_packages:
- fence-agents-apc-snmp
ha_cluster_resource_primitives:
- id: myapc
agent: stonith:fence_apc_snmp
instance_attrs:
- attrs:
- name: ipaddr
value: apc-switch
- name: pcmk_host_map
value: rhel8-node1:1;rhel8-node2:2
- name: login
value: apc
- name: passwd
value: apc
- id: my_lvm
agent: ocf:heartbeat:LVM-activate
instance_attrs:
- attrs:
- name: vgname
value: my_vg
- name: vg_access_mode
value: system_id
- id: my_fs
agent: ocf:heartbeat:Filesystem
instance_attrs:
- attrs:
- name: device
value: /dev/my_vg/my_lv
- name: directory
value: /var/www
- name: fstype
value: ext4
- id: VirtualIP
agent: ocf:heartbeat:IPaddr2
instance_attrs:
- attrs:
- name: ip
value: 198.51.100.3
- name: cidr_netmask
value: 24
- id: Website
agent: ocf:heartbeat:apache
instance_attrs:
- attrs:
- name: configfile
value: /etc/httpd/conf/httpd.conf
- name: statusurl
value: http://127.0.0.1/server-status
ha_cluster_resource_groups:
- id: apachegroup
resource_ids:
- my_lvm
- my_fs
- VirtualIP
- WebsiteDadurch erstellt die Rolle ha_cluster einen Cluster mit dem Namen rhel8-cluster auf den Knoten.
Im Cluster ist ein Fence-Gerät namens myapc vom Typ stonith:fence_apc_snmp definiert. Das Gerät ist über die IP-Adresse apc-switch mit dem Anmeldenamen apc und dem Passwort apc erreichbar. Cluster-Knoten werden über dieses Gerät mit Strom versorgt: rhel8-node1 wird an Socket 1 angeschlossen und rhel8-node2 wird an Socket 2 angeschlossen. Da keine weiteren Fence-Geräte verwendet werden, habe ich die Variable ha_cluster_fence_agent_packages festgelegt. Dadurch wird der Standardwert überschrieben und verhindert, dass andere Fence-Agenten installiert werden.
Im Cluster werden 4 Ressourcen ausgeführt:
- Die LVM-Volume-Gruppe my_vg wird von der Ressource my_lvm vom Typ ocf:heartbeat:LVM-activate aktiviert.
- Das Dateisystem ext4 wird vom gemeinsam genutzten Storage-Gerät /dev/my_vg/my_lv auf /var/www durch die Ressource my_fs vom Typ ocf:heartbeat:Filesystem gemountet.
- Die Floating-IP-Adresse 198.51.100.3/24 für den HTTP-Server wird von der Ressource VirtualIP vom Typ ocf:heartbeat:IPaddr2 gemanagt.
- Der HTTP-Server wird durch eine Website-Ressource vom Typ ocf:heartbeat:apache dargestellt. Die Konfigurationsdatei ist unter /etc/httpd/conf/httpd.conf gespeichert und die Statusseite zur Überwachung ist unter http://127.0.0.1/server-status verfügbar.
Alle Ressourcen werden in eine apachegroup-Gruppe platziert, damit sie auf einem einzelnen Knoten ausgeführt und in der angegebenen Reihenfolge gestartet werden: my_lvm, my_fs, VirtualIP, Website.
Erstellung des Playbooks
Im nächsten Schritt wird die Playbook-Datei unter ha_cluster/ha_cluster.yml mit dem folgenden Inhalt erstellt:
---
- name: Deploy a cluster
hosts: rhel8_cluster
roles:
- rhel-system-roles.ha_clusterDieses Playbook ruft die Systemrolle ha_cluster für sämtliche Systeme auf, die in der Inventory-Gruppe rhel8_cluster definiert sind.
Ausführung des Playbooks
Jetzt ist alles vorbereitet und ich kann das Playbook ausführen. In dieser Demonstration verwende ich einen RHEL-Kontrollknoten und führe das Playbook über die Befehlszeile aus. Dabei wechsle ich mit dem Befehl cd in das Verzeichnis ha_cluster und führe das Playbook dann mit dem Befehl ansible-playbook aus.
[ansible@controlnode ~]$ cd ha_cluster/ [ansible@controlnode ~]$ ansible-playbook -b -i inventory.yml --ask-vault-pass ha_cluster.yml
Damit lege ich fest, dass das Playbook ha_cluster.yml ausgeführt werden soll, dass es als Root ausgeführt werden soll (Flag -b), dass die Datei inventory.yml als mein Ansible-Inventory verwendet werden soll (Flag -i) und dass ich zur Eingabe des Vault-Passworts aufgefordert werden soll, um die Variable ha_cluster_hacluster_password zu entschlüsseln (Flag --ask-vault-pass).
Nach Abschluss des Playbooks muss ich sicherstellen, dass keine Aufgaben fehlgeschlagen sind:
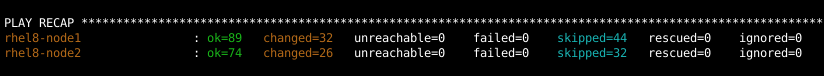
Validierung der Konfiguration
Um zu überprüfen, ob der Cluster eingerichtet wurde und Ressourcen ausführt, melde ich mich bei rhel8-node1 an und zeige den Clusterstatus an:
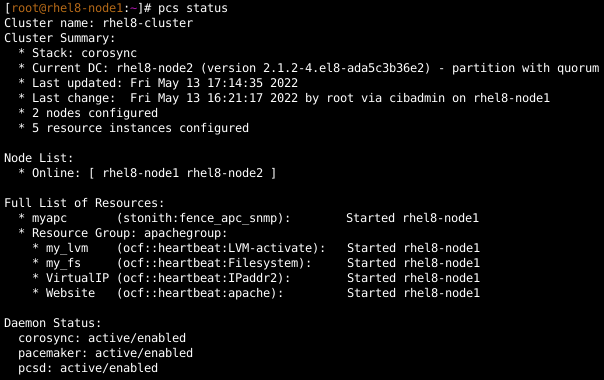
Ich überprüfe dies auch auf rhel8-node2, wo dieselbe Ausgabe angezeigt wird.
Als Nächstes öffne ich einen Webbrowser und stelle eine Verbindung zur IP 198.51.100.3 her, um zu überprüfen, ob der Zugriff auf die Website möglich ist.
Um das Failover zu testen, ziehe ich ein Netzwerkkabel von rhel8-node1 heraus. Nach einer Weile führt der Cluster das Failover aus und isoliert rhel8-node1. Ich melde mich bei rhel8-node2 an und zeige den Cluster-Status an. Der Status zeigt, dass alle Ressourcen von rhel8-node1 zu rhel8-node2 migriert wurden. Ich lade die Website auch im Webbrowser neu, um zu überprüfen, ob sie weiterhin aufgerufen werden kann.

Ich verbinde rhel8-node1 wieder mit dem Netzwerk und führe einen Neustart durch, damit es wieder mit dem Cluster verbunden wird.
Fazit
Mit der RHEL-Systemrolle ha_cluster können Sie RHEL-HA-Cluster schnell und konsistent konfigurieren, auf denen verschiedenste Workloads ausgeführt werden. In diesem Beitrag habe ich gezeigt, wie Sie mit der Rolle einen Apache HTTP-Server konfigurieren können, der eine Website über einen gemeinsamen Storage in einem Aktiv/Passiv-Modus ausführt.
Red Hat bietet viele RHEL-Systemrollen, mit denen Sie auch andere wichtige Aspekte Ihrer RHEL-Umgebung automatisieren können. In dieser Liste der verfügbaren RHEL-Systemrollen finden Sie weitere Informationen zu den verschiedenen Rollen, mit denen Sie Ihre RHEL-Server mithilfe von Automatisierung effizienter und konsistenter managen können.
Sie möchten mehr über Red Hat Ansible Automation Platform erfahren? Lesen Sie unser E-Book Handbuch zur Automatisierungsarchitektur.
Über den Autor

Tomas Jelinek is a Software Engineer at Red Hat with over seven years of experience with RHEL High Availability clusters.
Nach Thema durchsuchen

Automatisierung
Das Neueste zum Thema IT-Automatisierung für Technologien, Teams und Umgebungen

Künstliche Intelligenz
Erfahren Sie das Neueste von den Plattformen, die es Kunden ermöglichen, KI-Workloads beliebig auszuführen

Open Hybrid Cloud
Erfahren Sie, wie wir eine flexiblere Zukunft mit Hybrid Clouds schaffen.

Sicherheit
Erfahren Sie, wie wir Risiken in verschiedenen Umgebungen und Technologien reduzieren

Edge Computing
Erfahren Sie das Neueste von den Plattformen, die die Operations am Edge vereinfachen

Infrastruktur
Erfahren Sie das Neueste von der weltweit führenden Linux-Plattform für Unternehmen

Anwendungen
Entdecken Sie unsere Lösungen für komplexe Herausforderungen bei Anwendungen

Original Shows
Interessantes von den Experten, die die Technologien in Unternehmen mitgestalten
Produkte
- Red Hat Enterprise Linux
- Red Hat OpenShift
- Red Hat Ansible Automation Platform
- Cloud-Services
- Alle Produkte anzeigen
Tools
- Training & Zertifizierung
- Eigenes Konto
- Kundensupport
- Für Entwickler
- Partner finden
- Red Hat Ecosystem Catalog
- Mehrwert von Red Hat berechnen
- Dokumentation
Testen, kaufen und verkaufen
Kommunizieren
Über Red Hat
Als weltweit größter Anbieter von Open-Source-Software-Lösungen für Unternehmen stellen wir Linux-, Cloud-, Container- und Kubernetes-Technologien bereit. Wir bieten robuste Lösungen, die es Unternehmen erleichtern, plattform- und umgebungsübergreifend zu arbeiten – vom Rechenzentrum bis zum Netzwerkrand.
Wählen Sie eine Sprache
Red Hat legal and privacy links
- Über Red Hat
- Jobs bei Red Hat
- Veranstaltungen
- Standorte
- Red Hat kontaktieren
- Red Hat Blog
- Diversität, Gleichberechtigung und Inklusion
- Cool Stuff Store
- Red Hat Summit