One of the key components of a container-based architecture is security.
There are many facets to it (just have a look at the list of topics in the official OpenShift documentation here), but some of the most basic requirements are authentication and authorization. In this article, I explain how authentication and authorization work in Kubernetes and Red Hat OpenShift. I cover interactions between the different layers of a Kubernetes ecosystem, including the infrastructure layer, Kubernetes layer, and the containerized applications layer.
What is authentication and authorization?
In simple terms, authentication in a computer system is a way to answer “Who are you?” while authorization is “Now that I know it’s you, what are you allowed to do?”
In my experience, most of the difficulty in understanding this topic in Kubernetes is due to how many components (users, APIs, containers, pods) interact with each other. When talking about authentication, you have to clarify first what components are involved. Are you authenticating to the Kubernetes cluster? Or are you talking about a microservice trying to access another microservice within the environment? Or maybe a cloud resource sitting outside of the Kubernetes cluster? Or an endpoint (a cloud resource, a system, or a person) trying to access and use one of the applications running on the cluster?
Authentication and authorization with OAuth 2.0 and OIDC
Suppose a user is trying to access an endpoint. The user could be:
- A real person
- A non-human account (an application pod, system component, a software pipeline, or a physical or logical entity)
The endpoint could be:
- An API
- A piece of software (like a database)
- A physical or virtual server
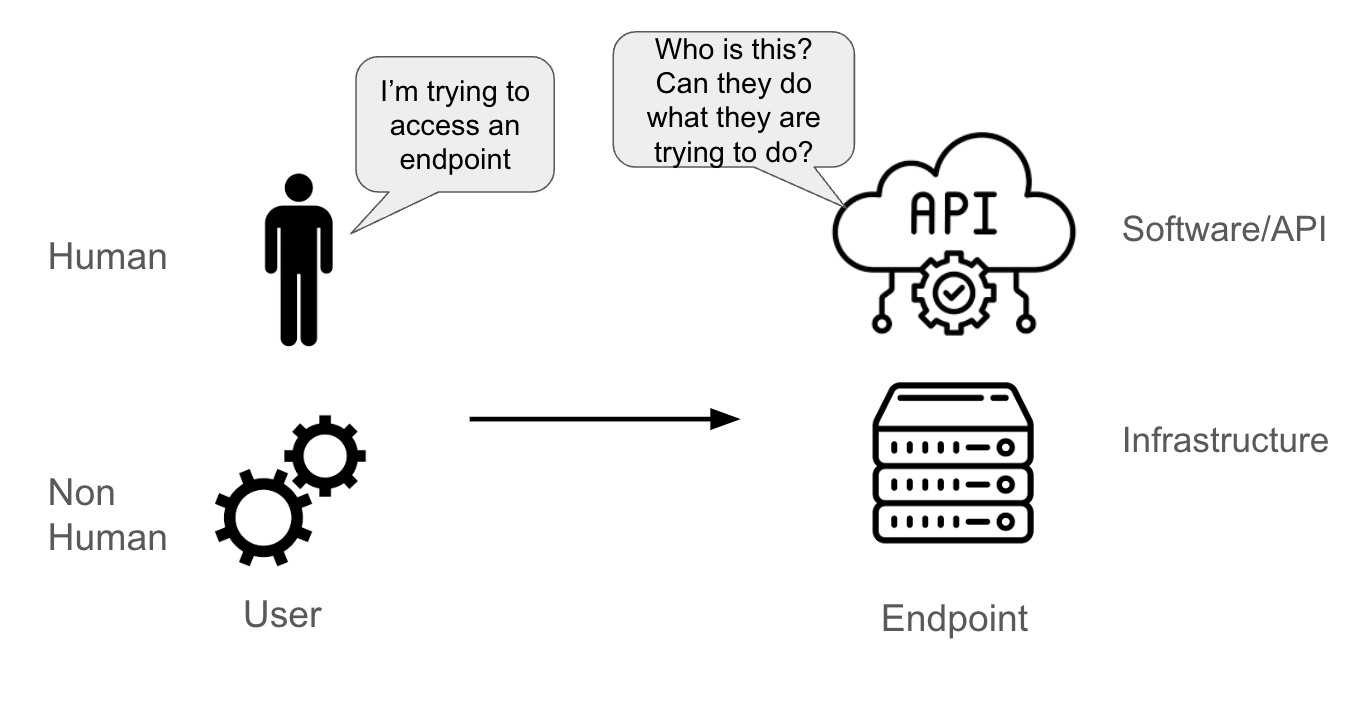
When the endpoint receives a request from the user, it must be able to understand:
- Who is sending this request (that’s the authentication part)
- What this user is entitled to do (that’s the authorization part)
There's a whole section in the official Kubernetes documentation about authentication. The main point of that documentation is that authentication in Kubernetes refers to the process of authenticating an API request made to the Kubernetes API server. Those requests can be made from the kubectl or oc commands in a terminal, a GUI, or through API calls, but ultimately everything is sent to the API server.
Even though there are many authentication technologies and protocols available (LDAP, SAML, Kerberos, and more), the most successful and common API authentication method is the combination of OAuth 2.0 and OpenID Connect (OIDC).
OAuth 2.0 is an authorization protocol (not an authentication protocol) designed to grant access to a set of resources (for example, a remote API or user data). To achieve this, OAuth 2.0 uses an access token, which is a piece of data that represents authorization to access a resource on behalf of the end-user.
OpenID Connect (OIDC) is an authentication protocol that extends the OAuth 2.0 framework by providing an identity layer on top of it. It provides a mechanism for requesting specific user information, such as name or email address, and allows users to grant or deny access to this information. The protocol's main extension of OAuth2 is an additional field returned with the access token called an ID token. This token is a JSON Web Token (JWT) with specific fields, such as a user's email, signed by the server.
The diagram below shows the steps taken when a user tries to configure a set of actions in a kubernetes cluster using the kubectl command. The full process is more complex, but well documented in the official documentation.
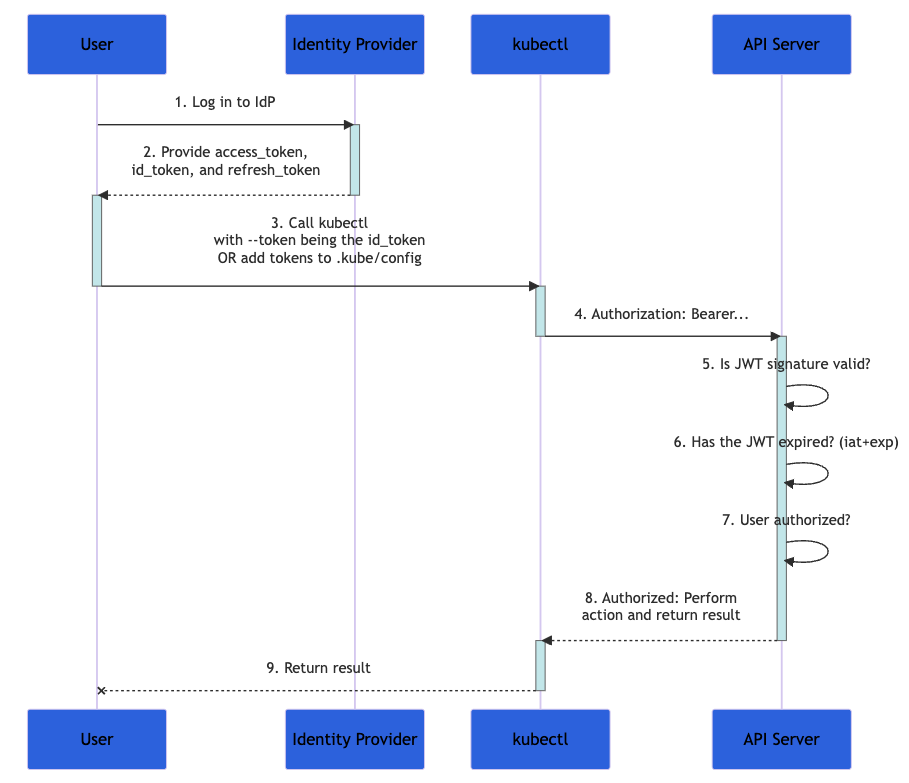
Caption: A flowchart from Kubernetes documentation demonstrating the authentication process
- First, you log in to an identity provider
- The identity provider provides you with an
access_token, id_tokenand arefresh_token - With
kubectl, use yourid_tokenwith the--tokenparameter, or add the token tokubeconfig - The
kubectlsends theid_tokenin a header called "Authorization" to the API server - The API server verifies that the JWT signature is valid, that the
id_tokenhasn't expired, and that user is authorized for this transaction - The API server returns a response to
kubectl, which provides feedback to you
Because your id_token contains all the data needed to validate your identity, Kubernetes doesn't need further interaction with the identity provider. That's a highly scalable solution to authentication, especially when each request is stateless.
What is role-based access control (RBAC)?
Role-based access control (RBAC) is a method of regulating access to computer or network resources based on the roles of individual users within an organization. For example, a system administrator on a platform might be entitled to make modifications to the whole environment (potentially impacting every application on the cluster). If you're responsible for managing just one application on the cluster, however, you're probably only allowed to make modifications to that application.
The figure below shows these two example users. The green icon is a user belonging to the HR team, while the black icon is a platform admin. The HR user can access only the resources under the HR apps group, but the platform admin can access anything within the platform.
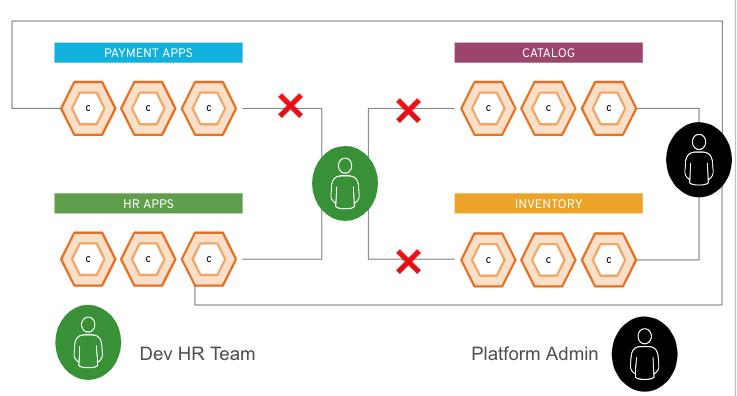
The HR user is granted a green token during the authorization step, and the admin is granted a black token. As part of their interaction with the endpoint (the Kubernetes cluster or OpenShift API), each user would add their token (green or black) to their requests. Based on this token, the cluster knows which applications each user can access.
Transport layer and endpoints
The most common transport mechanism for reaching a Kubernetes endpoint is Transport Layer Security (TLS), which provides an encrypted tunnel for HTTPS.
If you're a systems administrator for a Linux or Windows virtual machine, your access methodology for those endpoints is probably SSH or RDP. These protocols encrypt traffic between you (the user) and the endpoint (the Linux or Windows server). Similarly, when dealing with an API, software, or third-party Software-as-a-Service (SaaS), the most common transport mechanism is TLS.
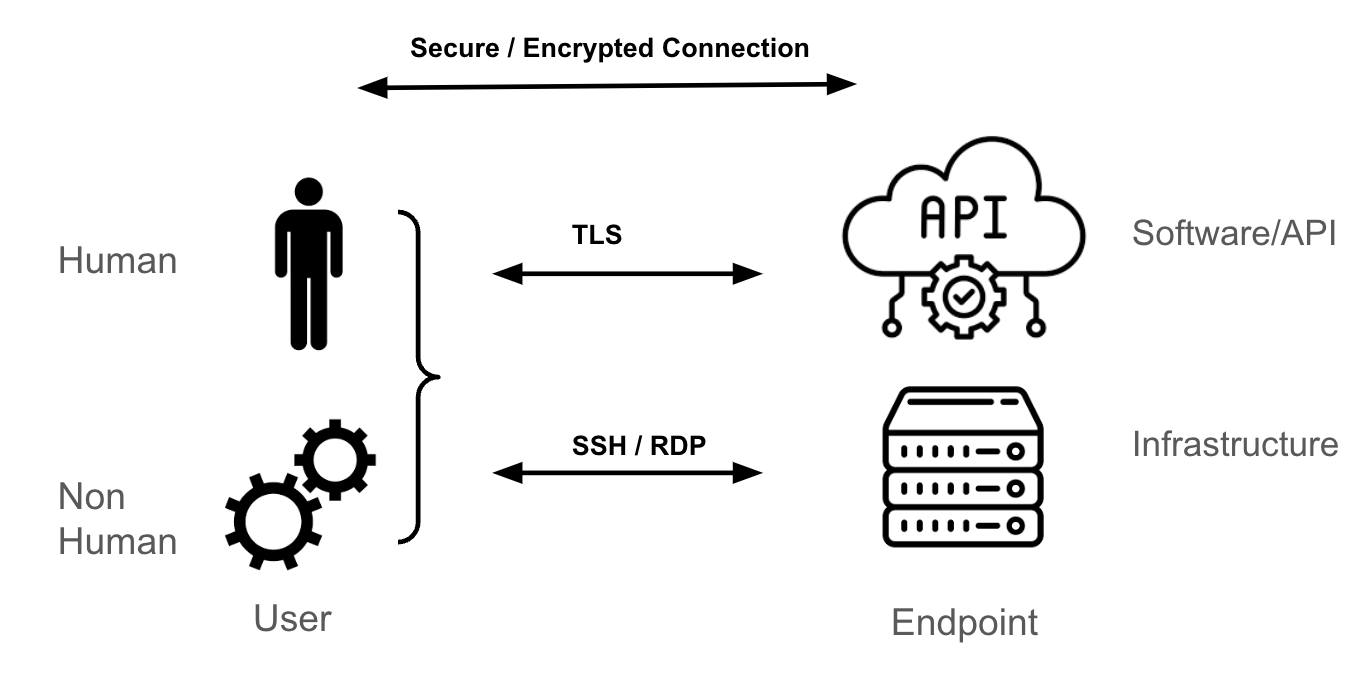
How a secure and encrypted session is established between both the endpoint and the user is not within the scope of this blog, but it relies on tunnels and keys (or certificates) that are used to authenticate the endpoint(s) (either the user or the endpoint or both) and encrypt and decrypt the packets sent between the endpoints.
The layers of Kubernetes and OpenShift access
The three concepts of authentication, authorization and transport are relatively straight-forward, once you're aware of them. However, in any IT environment, there are multiple layers to consider, and this is where much of the complexity and confusion arise.
In a Kubernetes architecture, there are 3 main layers:
- Infrastructure layer: Compute, storage, and networking. This layer could be a public cloud, an on-premises or colocation datacenter, or a mix of all of these
- Kubernetes layer: Responsible for the hosting and management of all containerized applications
- Containerized applications: The group of containers forming a specific application. These applications might include commercial off the shelf (COTS), independent software vendor (ISV), in-house developed applications, or any mix of these
Each layer provides and requires both authentication and authorization capabilities.
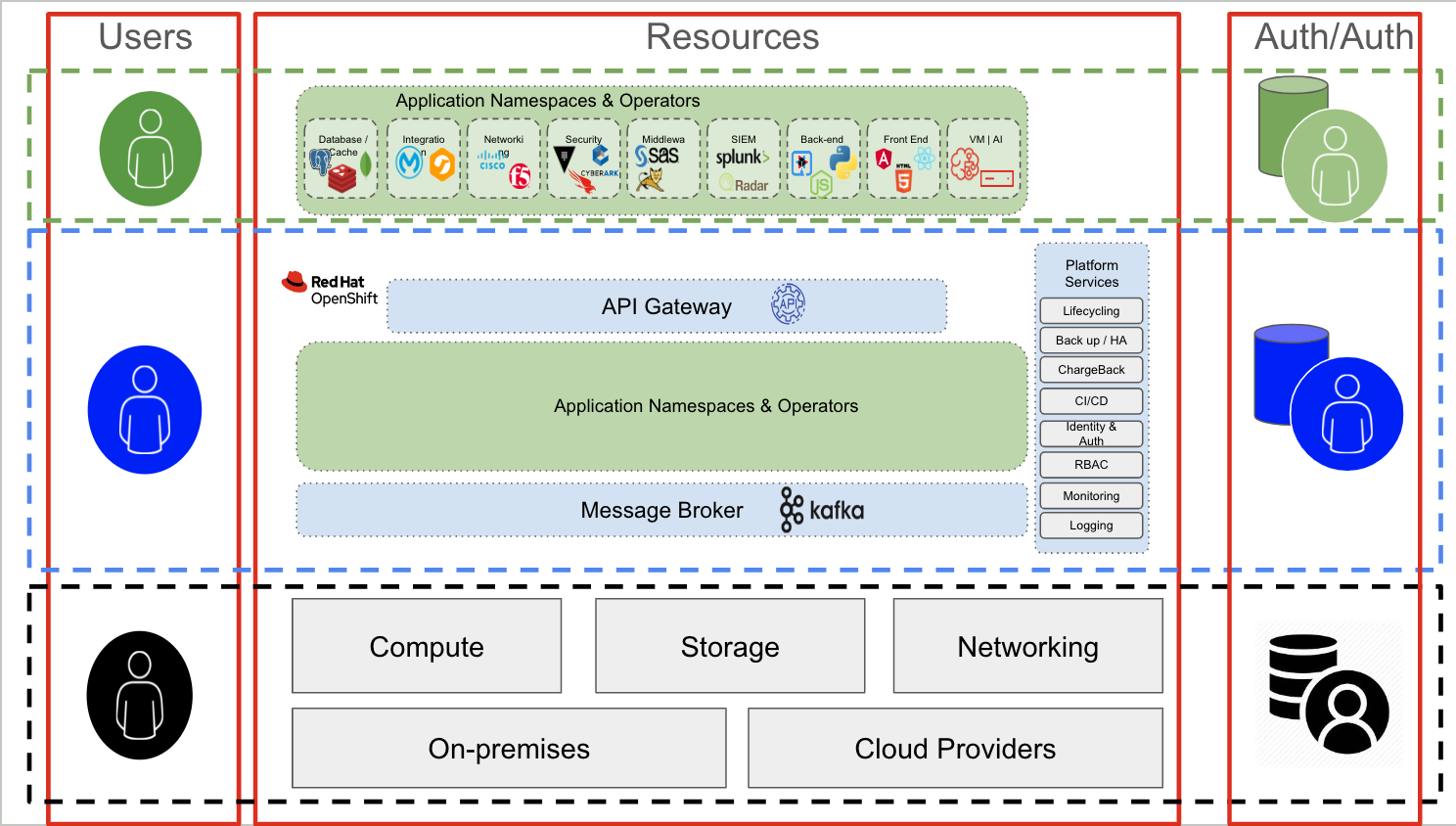
Authentication and authorization in the infrastructure layer
The users of the infrastructure layer are typically systems administrators who require access to specific components (either storage, networking, compute, or virtualization). To access this layer (the bottom layer, in black, in the figure above), an administrative user typically connects to a server over SSH, using dedicated interfaces to the storage, networking, or compute nodes (iLOs, iDRAC, and so on). The authentication mechanism can be a mix of RADIUS/TACACS (networking), LDAP or Kerberos (servers and storage), or other domain-specific authentication mechanisms.
Interestingly, the same infrastructure administrative user may be using an application (in the green layer), hosted on OpenShift (the blue layer) to help them perform their activities.
For example, the networking management stack may be a containerised application running on OpenShift. But in that context, the admin user is functionally a normal (green) user trying to access an application (the networking management stack, in this example). The authentication and authorization mechanisms are different in this layer. For example, a connection to the application is probably over a TLS/SSL connection, and may require credentials to access the network management stack console.
Authentication and authorisation in OpenShift
Moving up the layers and looking at the blue layer (that is, interacting with OpenShift or Kubernetes in general) means communicating to the Kubernetes API server. This is true for both human and non-human users, whether they're using a GUI console or a terminal. Ultimately, all interaction with OpenShift or Kubernetes goes through the API server.
The OAuth2/OIDC combination makes perfect sense for API authentication and authorization, so OpenShift features a built-in OAuth2 server. As part of the configuration of this OAuth2 server, an supported identity provider must be added. The identity provider helps the OAuth2 server confirm who the user is. Once this part has been configured, OpenShift is ready to authenticate users.
For an authenticated user, OpenShift creates an access token and returns that token to the user. This token is called an OAuth access token. A user can use those OAuth access tokens during each interaction with the OpenShift API until it expires or is revoked.
Users and service accounts
A user can be either human and non-human. In OpenShift, there are conceptually different roles that any given user might take:
- Regular users: Humans interacting with a Kubernetes cluster
- System users: Humans (for instance, a platform admin) and non-human cluster components (for instance, the registry, various control-plane nodes, and application nodes)
- Other non-human users: These include service accounts. They typically represent applications (within or outside the cluster) that need to interact with the Kubernetes API. For example, a pipeline using GitLab, GitHub, and Tekton would be using a service account to interact with OpenShift
Users and Service Accounts can be organized into groups in OpenShift. Groups are useful when managing authorization policies to grant permissions to multiple users at once. For example, you can allow a group access to objects within a project instead of granting access to each user individually.
A user can be assigned to one or more Groups, each of which represent a certain set of users. Most organizations already have user groups (for example, in an Active Directory server). It's possible to sync LDAP records with internal OpenShift group records.
Role-based access control (RBAC) and authorization
When a user has successfully authenticated and received an OAuth2 access-token, that user is granted a set of access privileges based on RBAC. An RBAC object determines whether a user is allowed to perform a given action on a resource. An RBAC definition can be cluster-wide or project-wide.
An RBAC is managed using:
- Rules: Sets of permitted verbs on a set of objects. These are collectively known as CRUD: create, read, update, delete. They're the fundamental operations of persistent storage. In the context of a RESTful API, they correspond to POST, GET, PUT or PATCH, and DELETE of the HTTP protocol. For example, a user or service account may have permission to create a pod
- Roles: Collections of rules. You can associate, or bind, users and groups to multiple roles
- Bindings: Associations between users and groups with a role
OpenShift provides predefined Roles (cluster-admin, basic user, and more). A good overview of RBAC using Rules, Roles and Bindings is illustrated in the figure below (extracted from the OpenShift documentation).
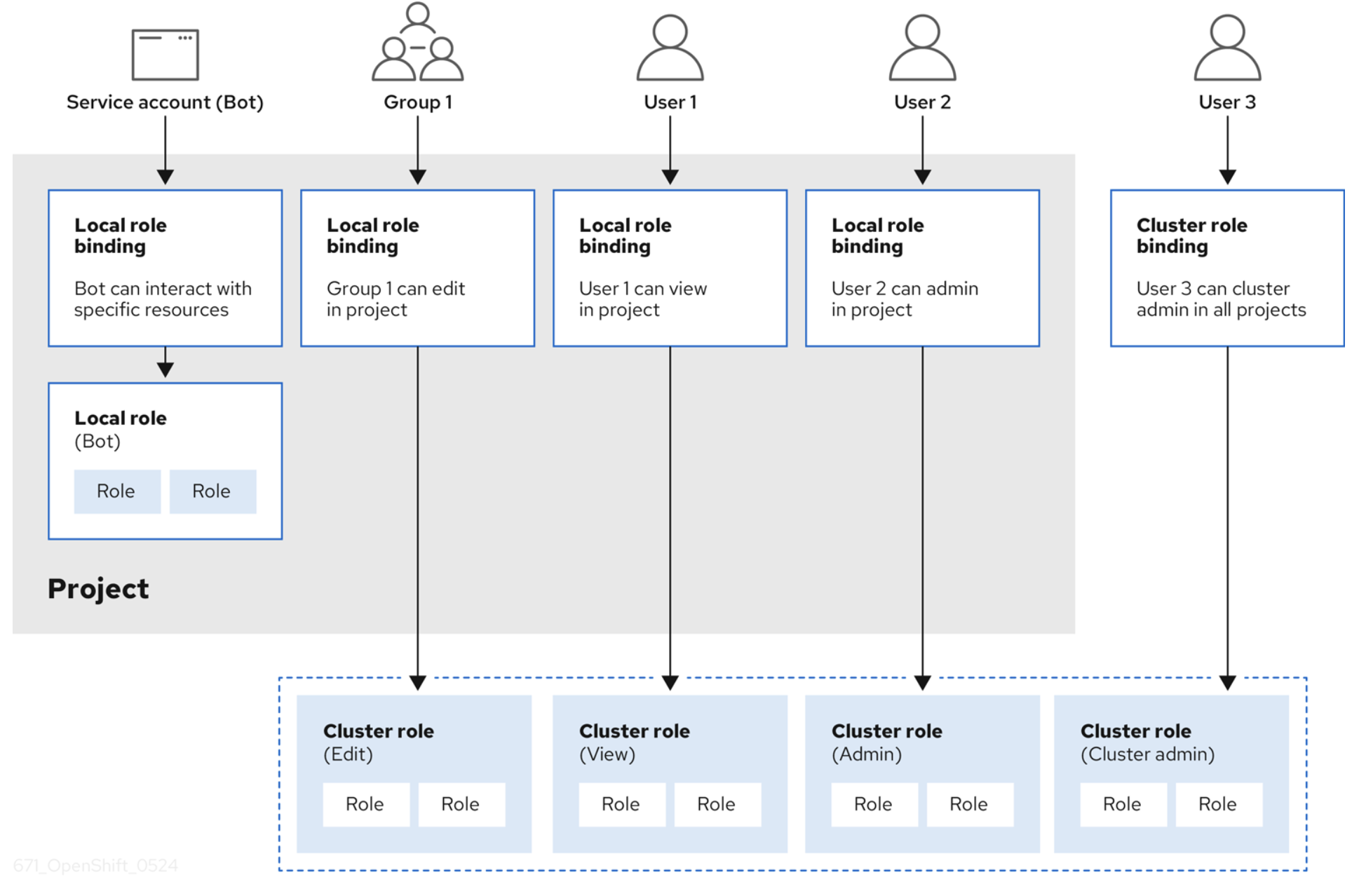
Authentication and authorization from resources within the OpenShift layer
A resource within the Kubernetes layer (typically a pod) can require access in order to perform one of the following actions:
- Interact with the Kubernetes API
- Interact with the host (the infrastructure layer) the resource is hosted on
- Interact with resources outside the cluster (for example, a cloud resource)

Interacting with the Kubernetes API
Any interaction with the Kubernetes API requires some sort of authentication using OAuth. A pod represents a non-human user, so it requires a service account to interact with the API server.
By default, a pod is associated with a service account, and a credential (token) for that service account is placed into the filesystem of each container in that pod, at /var/run/secrets/kubernetes.io/serviceaccount/token. There is debate over whether this model is a good idea or not, so this is configurable in OpenShift, and can be enforced using policies with tools like ACS.
Interacting with the host/Kubernetes infrastructure layer
This type of interaction does not rely on Kubernetes API calls. It is in fact related to the process level permissions management (Linux level permissions) of the underlying host.
Mapping the actions (permissions) that a pod can perform with the underlying infrastructure and what resources it can access is done using security context constraints (SCC). An SCC is an OpenShift resource that restricts a pod to a group of resources, and is similar to the Kubernetes security context resource.
For example, a process may or may not have permission to create a file in a given path, or it may not have write permissions to an existing file (it may only have read permissions). The primary purpose of both is to limit a pod's access to the host environment. You can use an SCC to control pod permissions, similar to the way role-based access control is used to manage user privilege.
Interacting with external resources
Sometimes a pod needs to access a resource outside of the cluster. For example, it may require access to an object store (like an S3 bucket) for data or log files. This requires you to understand how the resource authenticates users, and what you need to build in to the pod that's going to be communicating with that resource.
Amazon's identity and access management (IAM) for roles for service accounts (IRSA) is an example of such a design for providing pods with a set of credentials to access services on AWS. When a pod is created, a webhook injects variables (the path to the Kubernetes service-account token and the ARN of the role assumed) into the pod referencing the service account. This is also called “mutating”. If the IAM assumed role has the required AWS permissions, then the pod can run the AWS SDK operations by using temporary STS credentials.
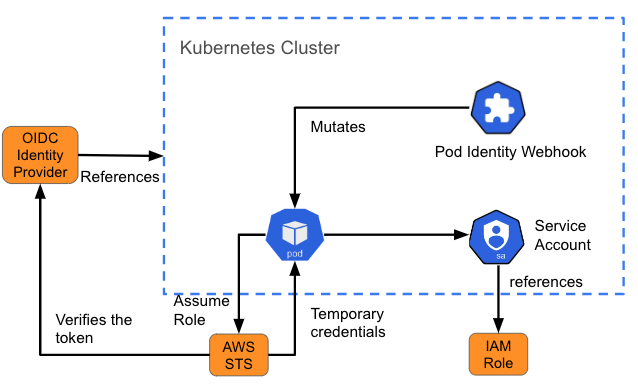
Authentication and authorization for containerised applications in OpenShift
The final layer is containerised applications. Similar to the previous layer, each container can be attempting to access:
- The Kubernetes API
- Another API provided either by another container within the cluster or a resource outside the cluster
- A non-API connection, such as contacting a specific port for database access
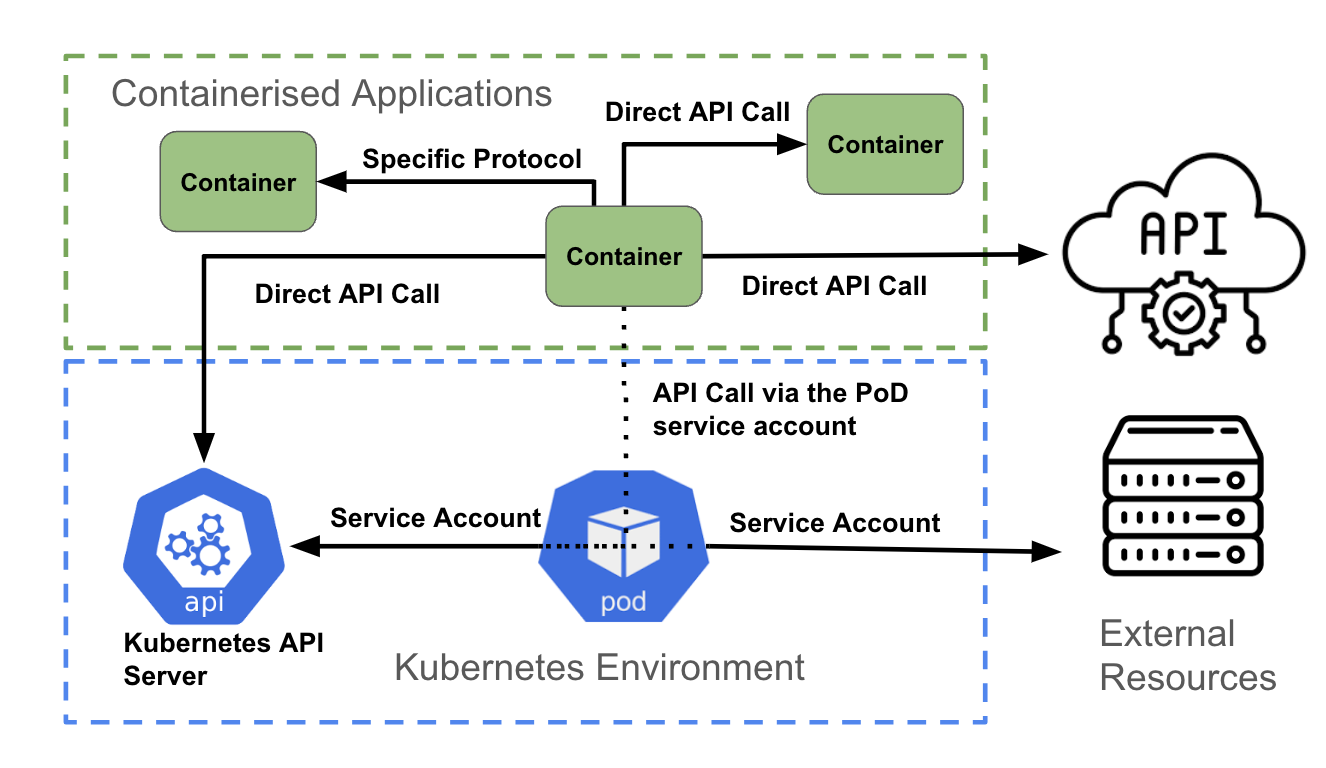
As the figure above illustrates, a container accessing an API can:
- Directly access another API using authentication credentials associated with the application (using Kubernetes Secrets, for example)
- Directly access a non-API endpoint, using the authentication mechanisms supported by the endpoint
- Make use of the pod service account
Direct API call
A container can access the Kubernetes API by fetching the KUBERNETES_SERVICE_HOST and KUBERNETES_SERVICE_PORT_HTTPS environment variables. For non-Kubernetes API traffic, an application can use either a client library (for instance, an AWS API), or a custom integration created by the developer.
Non-API based communication
An application may need to connect to a database to retrieve or push data. In such a case, authentication is typically handled as part of the code within the container, and can usually be updated at runtime using environment variables, secrets, ConfigMaps, and so on.
Use of service account
The recommended way to authenticate to the Kubernetes API server is with a service account credential. Most coding languages have a set of supported Kubernetes client libraries. Based on those libraries, the service account credentials of a pod are used to communicate with the API server. OpenShift automatically mounts a service account inside each pod, allowing it to access the scoped token.
For non-Kubernetes API calls, a container can also make use of the pod service account when authenticating to an external API service.
Authentication and authorization
A computer needs to know who a user is, and what that user is allowed to do. That's the domain of authentication and authorization, and now you understand how it's managed within Kubernetes and OpenShift.
Thanks to Shane Boulden and Derek Waters for their thorough review and feedback on this article.
About the author

Simon Delord is a Solution Architect at Red Hat. He works with enterprises on their container/Kubernetes practices and driving business value from open source technology. The majority of his time is spent on introducing OpenShift Container Platform (OCP) to teams and helping break down silos to create cultures of collaboration.Prior to Red Hat, Simon worked with many Telco carriers and vendors in Europe and APAC specializing in networking, data-centres and hybrid cloud architectures.Simon is also a regular speaker at public conferences and has co-authored multiple RFCs in the IETF and other standard bodies.
More like this
The nervous system gets a soul: why sovereign cloud is telco’s real second act
Refactoring isn’t just technical—it’s an economic hedge
Understanding AI Security Frameworks | Compiler
Data Security And AI | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds