One of the most important use cases in platform engineering is the provisioning of an environment. In this context, environment represents everything that developers need to run their applications. This definition is very loose and subjective, but it captures the essence of the concept.
If you are building a developer platform, you must provide developers with a self-service way to provision environments.
This is the first in a series of articles that will show an approach to Environments-as-a-Service (EaaS) for Kubernetes or Red Hat OpenShift-based platforms.
Think of environments as namespaces when building a development platform on Kubernetes. However, environments are more than that. They also encompass at least the following attributes:
- The configuration needed to make a namespace ready for hand-off to the developers.
- The credentials required to run applications in those namespaces.
- Configurations that are external to the namespaces, such as load balancers, DNS, firewalls and any other configurations surrounding Kubernetes and necessary to run the applications.
- Application dependencies, such as databases, messaging systems, etc.
Environment types
Environments have a life cycle. They are provisioned, and, at some point, they are deprovisioned. Deprovisioning environments at the appropriate time is part of the EaaS use case.
Different environment types have different life cycles. The following table summarizes the most common variations:
Type | Lifecycle | Description |
Software Development Life Cycle (SDLC) | Bound to application lifecycle | Used to run the application component, typically deployed by the CI/CD pipeline. |
Build namespace | Bound to application lifecycle | Used by the CI/CD pipeline to build the application components. |
Feature branch | Bound to the code repository branches lifecycle. | Used to deploy code built from a branch. |
Personal | Bound to user identity lifecycle, often periodically deleted to recover resources. | Used to run personal experiments. |
This article focuses on the SDLC environment type. However, similar considerations apply to the other types as well. The key differentiator between the types is what triggers their creation and deletion.
Environment-as-a-Service design principles
The following lists the principles used to design the capabilities of EaaS:
- Infrastructure as Code (IaC): Every configuration is stored in a Git repository.
- Workflows that involve human interaction, typically for review and approval purposes, are modeled either directly in the Git tool being used (GitHub, GitLab, etc.) or in another process that occurs before the creation of the pull requests to the Git tool. Once a configuration is merged, it is considered approved and will be applied to the infrastructure.
- All configuration is described via the Kubernetes API and applied via a GitOps operator, in this case, Argo CD.
This example focuses on the EaaS capability, but these principles should be generalized to the entire developer platform design.
With these principles in place, the interface to make configuration changes to the platform is constituted by a set of Git repositories containing Kubernetes manifests. This approach makes it relatively simple to control and straightforward to implement approval workflows and other compliance processes. It is also possible to apply validation rules as CI jobs within each Git repository, such as the linting of the Kubernetes manifests.
Namespace provisioning design
As discussed, an environment in a Kubernetes-based developer platform is not just a namespace. Since it also consists of resources deployed within namespaces, a namespace is the logical place to begin. This first article of the series focuses on the namespace provisioning process. Below is the high-level design of this entire process.

In this diagram, you can see that developers can create pull requests on a repository that contains the accepted namespaces. They can make pull requests directly from a portal. This is represented by Red Hat Developer Hub (Red Hat's distribution of Backstage) in the diagram. The advantage of using a portal is that developers don't have to learn how namespaces are defined in Kubernetes using YAML formatted files. The portal also allows the platform engineers to ensure that all namespace requests are created using the standards that an organization has set.
The characteristics and configurations of a namespace are dictated by a set of labels and annotations on the namespaces themselves. This works because, at runtime, the tenants will not be allowed to change such labels and annotations due to role-based access control (RBAC) policies applied to the namespace. This also aligns with other features that use namespace labels and annotations to control behavior within a namespace (e.g., node selector, default tolerations, tolerations whitelists, pod security standards, route sharding, etc.). The demonstration process is based on the following labels:
- Team: Represents the team that owns the application running in this namespace. It can be used to apply permissions rules, dispatch alerts, etc.
- Application: The application that runs in the namespace. It can be used to relate/integrate with other systems that need to know about applications, such as the application catalog (or CMDB), the credentials management system, the CI/CD system, the Git tool, etc.
- Size: Determines the namespace size in terms of the quota awarded to it.
- Environment: Represents the environment name/purpose (typically dev, qa, prod, etc.).
Once a pull request containing namespaces is created, the platform engineering team can evaluate the content and possibly accept the request. Checks and merges could also be automated. In most cases, one should ensure that there is enough available capacity in the clusters associated with the namespaces being requested. This check is relatively easy to automate. Other validations can be more difficult to implement, such as confirming that the requester of a namespace for an application is authorized to do so.
Once the pull request is merged, the GitOps operator (Argo CD) picks up the new content and creates the namespace(s). The diagram does not show the multicluster dimension of the problem, but with careful organization of the files in folders, you can manage multiple clusters.
Once the namespaces are created, the namespace configuration operator will apply the needed configurations by matching configuration policies with the new namespaces. The match occurs via a label selector.
At this point, the namespaces are created and fully configured. Two settings that are almost always present are quotas and RBAC. I already mentioned why quotas are needed. RBAC is needed to allow the tenants to operate on the target namespace.
Use the group sync operator to create OpenShift Groups and assign members to groups. This operator synchronizes Group information from external identity providers into OpenShift. It creates groups and memberships, while the namespace configuration operator creates the needed role binding to assign the correct role to the groups.
Tenants can now connect to OpenShift and operate within their namespaces.
Infrastructure preparation
I have prepared a GitOps repository that sets up this pattern and can be used as a reference for those who would like to implement this approach.
This repository manages three clusters—a hub and two managed clusters. It looks like this:

I'll walk through this repository and highlight the key portions.
Prerequisites
Before implementing this namespace provisioning pattern, it must meet some additional prerequisites. Mainly, you need an Identity Provider for user authentication and a developer portal. Install Red Hat Advanced Cluster Management for Kubernetes or multicluster engine for Kubernetes to manage the fleet of OpenShift clusters needed to implement the SDLC environments.
Check for the Red Hat Advanced Cluster Management operator installation and configuration. This step is not strictly necessary for this specific pattern, but it builds a foundation for future installments of this series.
With regard to the Identity Provider, I installed the Red Hat build of Keycloak. You can find the operator configuration here and the actual Keycloak instance configuration here. Crossplane and the Keycloak Crossplane provider were implemented to fully configure Keycloak declaratively. As you progress through the blog series, Crossplane will be fundamental to provisioning resources. For now, consider it an implementation detail.
I prepared the following users and groups in Keycloak:
Group | Users |
team-a | Adam, Amelie |
team-b | Brad, Brumilde |
Knowing the users that are present and their group membership will be useful later when you log in and want to confirm visibility and permissions.
You can find the configuration for Red Hat Developer Hub here. Naturally, it is integrated with Keycloak, so a user can use the same credentials with OpenShift and Red Hat Developer Hub.
Now that the prerequisites have been met, I'll examine the namespace provisioning pattern in further detail.
Namespace provisioning design
First, you need a Git repository to contain the namespace definitions. One is available here to demonstrate this approach. The naming convention for this repository is that every namespace definition under /<cluster-name>/* will be picked up by the relative cluster.
You can find the Argo CD application that enforces this configuration in the cluster here.
Now that the namespaces are created, enforce their configuration. The namespace configuration operator is installed along with some configurations in this example. Configure quotas and RBAC for now. More configurations will be needed in the future installments of this blog series.
Next, make sure that users can log in and that they will receive the correct permissions. Set up an Oauth configuration for OpenShift to authenticate them properly. To have the groups and membership synchronize from Keycloak, install and configure the group-sync-operator.
Finally, you can optionally configure a scaffolder template in Red Hat Developer Hub to facilitate the creation of namespaces for the developers.
A developer should, at this point, be able to connect to Red Hat Developer Hub and request namespaces, as shown below:
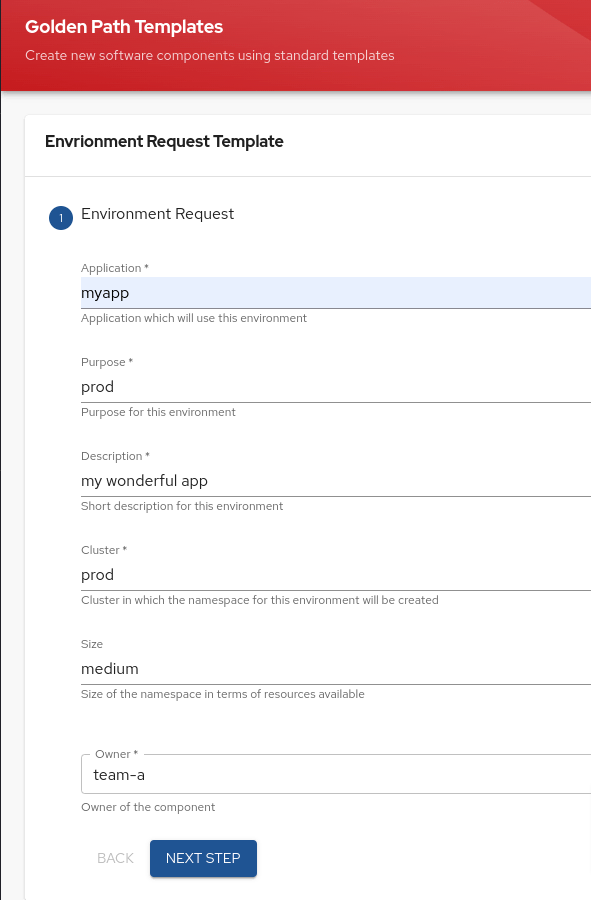
This process will generate a pull request to the namespaces repository for the platform team to examine, as seen below:

Once the namespace request PR is merged, the developer will be able to log in to OpenShift and operate in that namespace:
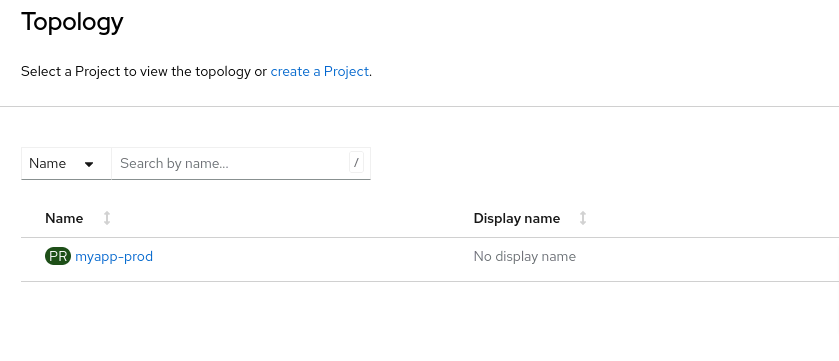
In this case, the user has created a single namespace.
Wrap up
This article showed an approach for the namespace provisioning use case. It implemented the solution using GitOps principles and a combination of the namespace configuration operator and the group sync operator.
Red Hat customers have successfully implemented these tools and approaches for several years. This approach works well because it is based on the composability principle, and it meets the defined requirements. Namespace configurations are determined by a set of rules that match the namespace labels and create the resulting namespace profile based on those values. As such, you don't need to know all the namespace profiles (i.e., all possible combinations of rules) that will be required in advance. Also, this approach is conducive to adding new rules as additional multi-tenancy requirements are defined. Finally, it is easy to change the namespace configuration if some configuration policies need to be updated. As soon as the configuration policy is updated, the namespace configuration operator updates all of the namespaces that are targeted to receive the desired configuration.
About the author

Raffaele is a full-stack enterprise architect with 20+ years of experience. Raffaele started his career in Italy as a Java Architect then gradually moved to Integration Architect and then Enterprise Architect. Later he moved to the United States to eventually become an OpenShift Architect for Red Hat consulting services, acquiring, in the process, knowledge of the infrastructure side of IT.
Currently Raffaele covers a consulting position of cross-portfolio application architect with a focus on OpenShift. Most of his career Raffaele worked with large financial institutions allowing him to acquire an understanding of enterprise processes and security and compliance requirements of large enterprise customers.
Raffaele has become part of the CNCF TAG Storage and contributed to the Cloud Native Disaster Recovery whitepaper.
Recently Raffaele has been focusing on how to improve the developer experience by implementing internal development platforms (IDP).
More like this
Strategic momentum: The new era of Red Hat and HPE Juniper network automation
Redefining automation governance: From execution to observability at Bradesco
Technically Speaking | Taming AI agents with observability
Press Start | Command Line Heroes
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds