The generative artificial intelligence (AI) landscape has undergone rapid evolution over the past year. As the power of generative large language models (LLMs) grows, organizations increasingly seek to harness their capabilities to meet business needs. Because of the intense computational demands of running LLMs, deploying them on a performant and reliable platform is critical to making cost-effective use of the underlying hardware, especially GPUs.
This article introduces the methodology and results of performance testing the Llama-2 models deployed on the model serving stack included with Red Hat OpenShift AI. OpenShift AI is a flexible, scalable MLOps platform with tools to build, deploy and manage AI-enabled applications. Built using open source technologies, it provides trusted, operationally consistent capabilities for teams to experiment, serve models and deliver innovative apps.
The model serving stack
The model serving software stack is based on KServe, OpenShift Serverless and OpenShift Service Mesh. To run the Llama-2 models, we also used Caikit and text-generation-inference-service (TGIS), though OpenShift AI also supports OpenVINO and offers the ability to modularly use other custom runtimes. The NVIDIA GPU Operator manages and exposes GPUs so the Text Generation Inference server (TGIS) container can use them.
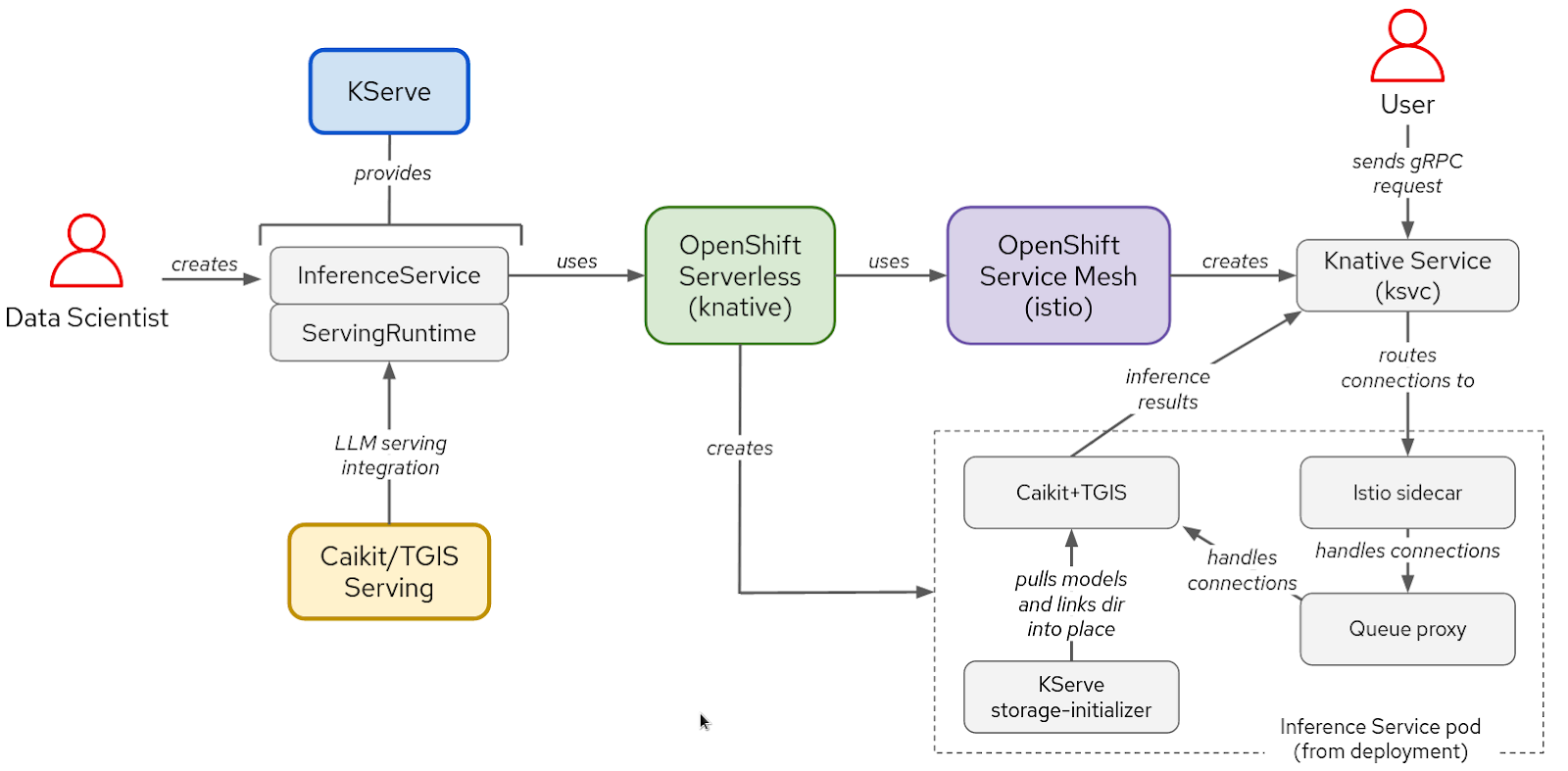
Figure 1: Interactions between components and user workflow in KServe/Caikit/TGIS stack
KServe provides many cutting-edge serving capabilities for AI model inference by leveraging OpenShift Serverless and OpenShift Service Mesh. These components encapsulate the complexity involved in networking, service configuration, autoscaling and health checking for production model serving.
The Caikit toolkit enables users to manage models through a set of developer-friendly APIs. Caikit provides standard gRPC (Remote Procedure Call) and HTTP interfaces that we can use to query various foundation models. It forwards the requests to the inferencing service, TGIS.
TGIS is an early fork of the Hugging Face text-generation-inference serving toolkit. It provides several important features to optimize the performance of serving LLMs, such as continuous batching, dynamic batching, Tensor Parallelism (model sharding), support for PyTorch 2 compile and more.
The NVIDIA GPU Operator automates the management of various software components needed to provision and use NVIDIA GPUs in OpenShift. This includes the driver container, device plugin, Data Center GPU Manager (DCGM) metrics exporter and more. The DCGM metrics exporter allows us to analyze GPU metrics such as memory utilization, streaming multiprocessor (SM) utilization and others using the OpenShift monitoring Prometheus instance.
Performance testing methodology for large language models
To evaluate the performance of a large language model, we are interested in the classic measures of latency and throughput. However, the end-to-end latency of requests to an LLM can vary widely depending on a few factors. The most important aspect is the length of the output because of how LLMs generate text one token at a time. Therefore, we primarily measure latency in terms of latency per token, or "time per output token" (TPOT).
Tokens are units of text that represent a word or sub-word string of characters. When a large language model processes text, it is first converted into tokens. The exact scheme used to map text to tokens varies from model to model. Tokens are assigned numerical representations and are arranged in vectors that are fed into the model and output from the model.
Another factor that impacts total request latency is "prefill" time, which is the time it takes for the input prompt tokens to be processed before the model generates the first new token. A third significant contributor to the total request latency is queuing time. In cases where the inference service cannot process requests fast enough to keep up with the incoming load due to hardware constraints, such as GPU memory, some requests will need to wait in a queue before being processed. Because of these factors, "time to first token" (TTFT) is a common metric for measuring LLM performance. TTFT is especially relevant for use cases like chatbots, where the tokens are streamed and displayed as they are generated.
Similar to latency, throughput varies widely if measured using requests per second depending on the number of tokens being generated in the requests. Therefore, we measure overall throughput in terms of total tokens generated per second across all users querying the model.
Load testing with llm-load-test
We have created an open source tool called llm-load-test to load test models running on the OpenShift AI model serving stack. It is written in Python and utilizes the gRPC load testing tool called ghz under the hood. We have forked ghz to add the ability to save the response and the worker thread ID for each request in the test output.
Going beyond the features offered in ghz, llm-load-test allows us to run multiple ghz processes in parallel with the input dataset in a randomized order in each instance. This allows us to simulate many different users querying the model with different prompts simultaneously. llm-load-test also can upload the results directly to an S3 bucket after an experiment, tagging the output objects with corresponding metadata for the run.
Input dataset
You can configure the input prompts in llm-load-test for the load test using a JSON file. We chose a dataset of 32 inputs from the OpenOrca dataset with varying input/output lengths for the experiments we ran to generate the results shared in this blog post. The longest input in our test data was 1688 tokens, and the longest output was 377 tokens. Figure 2 shows the distribution of input/output lengths in the test dataset.

Figure 2: Token length of test dataset.
Using a mixture of input and output sizes is important to test the continuous batching and dynamic batching capabilities of TGIS in a realistic scenario. Recent models have started to support very large 4k+ context lengths, which is especially important for use cases such as retrieval-augmented generation (RAG). Because of this, we intend to increase the size of our load-testing dataset to include larger input lengths in the future.
Performance results of llama-2 on OpenShift AI on AWS
The following performance measurements were gathered using a self-managed installer-provisioned infrastructure (IPI) OpenShift cluster installed on AWS. We installed the OpenShift AI operator and created ServingRuntime and InferenceService objects to enable serving the model with Kserve, Caikit and TGIS.
Table 1 below summarizes the results from testing four combinations of model and AWS instance types:
Model | Instance | GPU Type | GPU Memory per GPU | GPU Count | Tensor Parallelism degree (# shards) |
llama-2-7b-hf | g5.2xlarge | A10G | 24GB | 1 | 1 |
llama-2-13b-hf | g5.12xlarge | A10G | 24GB | 4 | 4 |
llama-2-70b-hf | g5.48xlarge | A10G | 24GB | 8 | 8 |
llama-2-70b-hf | p4d.24xlarge | A100 | 40GB | 8 | 8 |
Table 1: Summary of test configurations.
In each configuration, we ran several four-minute load tests using llm-load-test with different numbers of concurrent threads (the concurrency parameter in the figures below). In each test, each concurrent thread continuously sends one request at a time as soon as it receives the answer from the previous request.
As a visual example of one experiment, Figure 3 below shows a plot of the total latency of each request over the duration of the test. The color of each dot represents the token length, so you can visualize how closely correlated the token length is with the overall request output.

Figure 3: Total latency of all requests over the duration of a load test.
We parsed the TGIS logs to get the total latency of each request and calculated throughput by dividing the total tokens generated during the load test by the duration of the test (240 seconds).
Figure 4 shows the latency and throughput measured when load testing llama-2-7b on the g5.2xlarge instance with various load test concurrency settings. In this case, we see that throughput increases as we increase the load test concurrency up to a concurrency of ~20 threads. Due to GPU memory constraints of the g5.2xlarge instance, TGIS cannot fit more than ~20 requests (depending on the input/output length of the requests) into a batch at one time.

Figure 4: Latency and throughput summary for Llama-2-7b on g5.2xlarge.
The Figure 5 graph shows the latency and throughput measured when load testing llama-2-13B on the g5.12xlarge instance. In this case, we see that minimum latency per token starts lower than the 7B model on g5.2xlarge, and throughput scales well up to at least 30 concurrent requests despite the model being larger and the instance having the same type of GPUs. This is due to the significant performance benefits of using tensor parallelism to distribute the model across the 4 GPUs.

Figure 5: Latency and throughput summary for Llama-2-13b on g5.12xlarge.
Figure 6 shows the latency and throughput measured when load testing llama-2-70b on the g5.48xlarge instance. In this case, the latency per token is higher across the board than in the prior configurations. Models like llama-2-70B have significant hardware requirements. The 8xA10G GPUs have 192GB of VRAM combined, most of which is required just to load the 70B parameters in 16-bit precision into memory (70 B*16 bits = ~140 GB). Depending on your performance requirements, even more compute may be desired, such as the p4d.24xlarge instances.
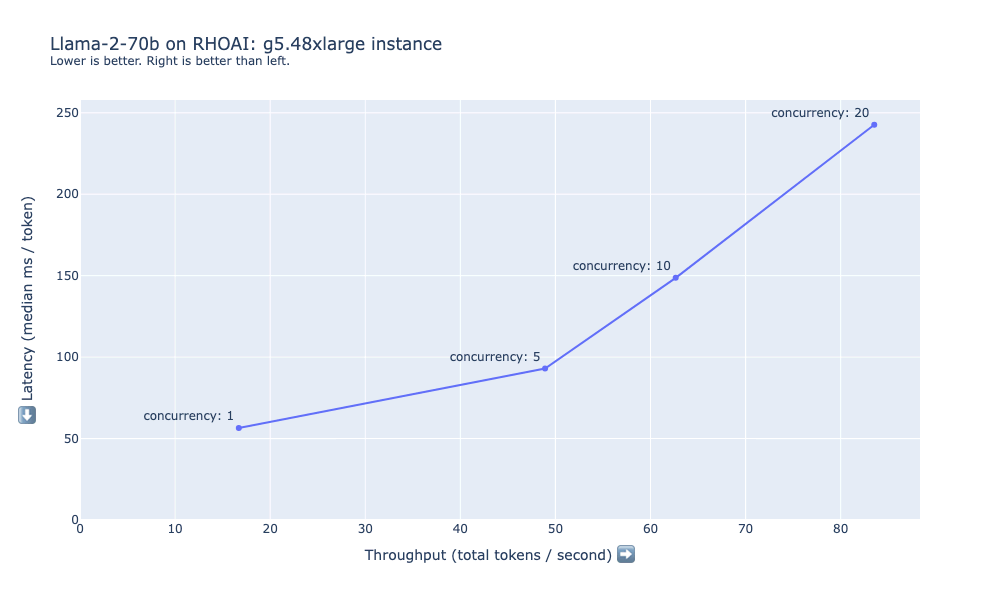
Figure 6: Latency and throughput summary for Llama-2-70b on g5.48xlarge.
Figure 7 shows the latency and throughput measured when load testing llama-2-70b on the p4d.24xlarge instance. On this instance, we can maintain much lower latency for the same number of users when compared with the g5.48xlarge instance. Even up to concurrency=30, throughput continues to scale as the load test concurrency increases.
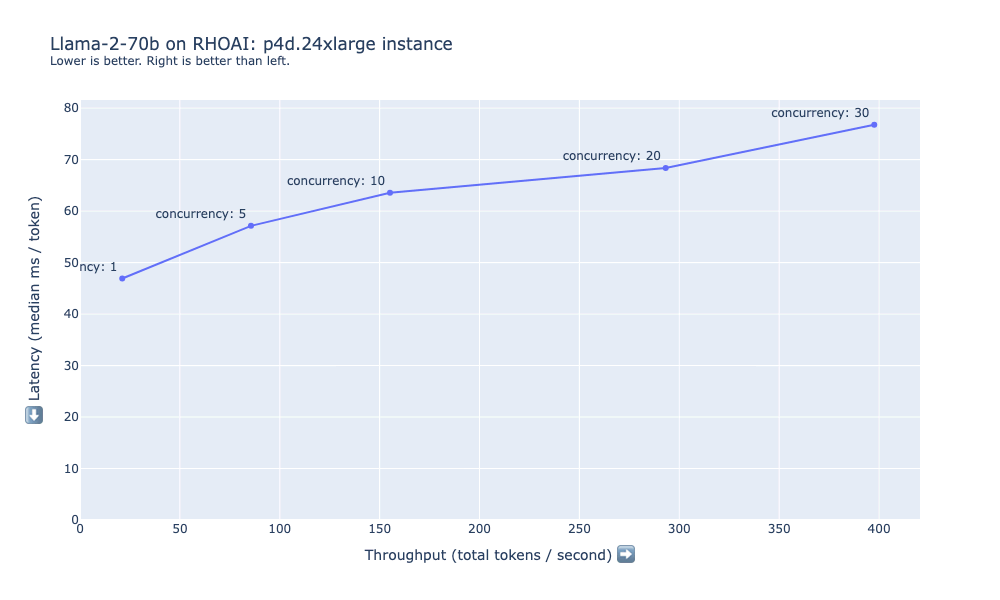
Figure 7: Latency and throughput summary for Llama-2-70b on p4d.24xlarge.
Cost calculations
We can estimate the cost to generate one million tokens using the measured throughput and instance type costs. The table below summarizes these estimates using the measured throughput for the results we gathered with a load concurrency of 10.
Model | Instance | GPU Count | Instance cost ($/hr) | Load concurrency | Throughput (tokens/sec) | Minutes for 1 million tokens | Cost per million tokens ($) |
llama-2-7b-hf | g5.2xlarge | 1 | 1.21 | 10 | 161.3 | 103.32 | 2.09 |
llama-2-7b-hf | g5.12xlarge | 4 | 5.67 | 10 | 336.96 | 49.46 | 4.68 |
llama-2-13b-hf | g5.12xlarge | 4 | 5.67 | 10 | 203.24 | 82.01 | 7.75 |
llama-2-13b-hf | g5.48xlarge | 8 | 8.14 | 10 | 224.55 | 74.22 | 10.07 |
llama-2-70b-hf | g5.48xlarge | 8 | 8.14 | 10 | 62.65 | 266.05 | 36.11 |
llama-2-70b-hf | p4d.24xlarge | 8 | 32.77 | 10 | 155.18 | 107.41 | 58.66 |
Table 2: Results summary for each configuration with calculated cost per million tokens.
Future work
These results are a small snapshot of the testing we are doing on the Performance and Scale for AI Platforms (PSAP) team at Red Hat. Along with performance testing for other aspects of OpenShift AI, we are actively continuing our performance and scalability analysis of the model serving stack. We hope to share more results of testing other models, autoscaling model replicas based on traffic and more in the future.
We will continue to develop llm-load-test, and there are several features we hope to add soon, such as:
- The ability to measure time-to-first-token and time-per-output-token for streaming requests.
- Pluggable/modular interfaces to query models that are behind different APIs, including HTTP and gRPC interfaces.
- Warmup phase and ability to validate that the model is loaded and responding without errors.
- More complex load patterns, such as a random Poisson arrival rate.
Conclusion
Our performance testing of Llama-2 models on OpenShift AI provides an overview of the latency, throughput and cost tradeoffs involved in running LLMs in several configurations. For example, for the 7B model, the g5.2xlarge instance was most affordable, but stepping up to the g5.12xlarge may be beneficial for some use cases due to the significant latency and throughput improvements from tensor parallelism. Running the larger models should result in higher quality output but requires more GPU memory, which comes at a higher cost.
OpenShift AI offers a performant and adaptable model-serving solution for organizations navigating the complexities of deploying generative large language models. Whether prioritizing model quality, latency, throughput or cost, the platform's flexibility accommodates diverse requirements. To explore these benefits for your specific use case, try deploying your model of choice on OpenShift AI.
About the author

David Gray is a Senior Software Engineer at Red Hat on the Performance and Scale for AI Platforms team. His role involves analyzing and improving AI model inference performance on Red Hat OpenShift and Kubernetes. David is actively engaged in performance experimentation and analysis of running large language models in hybrid cloud environments. His previous work includes the development of Kubernetes operators for kernel tuning and specialized hardware driver enablement on immutable operating systems.
David has presented at conferences such as NVIDIA GTC, OpenShift Commons Gathering and SuperComputing conferences. His professional interests include AI/ML, data science, performance engineering, algorithms and scientific computing.
More like this
AI in telco – the catalyst for scaling digital business
The nervous system gets a soul: why sovereign cloud is telco’s real second act
Technically Speaking | Build a production-ready AI toolbox
Technically Speaking | Platform engineering for AI agents
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds