
In November 2023, the Quay.io team migrated our database from the original MySQL instance to a brand new Postgres database. While the migration process itself was fairly smooth, it was not smooth for our customers. We experienced regular instability before and after the migration. Many of the issues we encountered were traced back to increased Quay.io traffic and differences in how MySQL and Postgres behave under load. We’d like to use this write up to share our insights and provide clarity around our recent instability.
Background
Quay.io was the first private container registry on the internet, going live in 2013. Our architecture at the time was built for large scale and easier operations, given that we were a small startup. Over the coming years, Quay.io became part of CoreOS and eventually Red Hat. Our team has grown and today Quay.io serves tens of petabytes of container images each month and is the central hub for many enterprise customers, including Red Hat’s entire container catalog.
While our traffic volume and importance have grown, our architecture has remained very similar to the original design. We’ve moved onto a managed Red Hat OpenShift cluster from standalone virtual machines (VMs), but the original Relational Database Service (RDS) database has been in use since we first went live.
The database behind Quay.io is critically important. As a container registry, our most important function is to store customer images in a safe manner and make them available when needed. Architecturally, this means holding image layer blobs in S3 storage while keeping track of which blobs belong to which customer image via our database. If we were to ever lose our database it would be a catastrophic event.
We were also running on MySQL 5.7 which is now quite old, with its end of life shortly approaching. As traffic volumes grew we continued to vertically scale our database until we were at the highest capacity possible on AWS. Our database had become a major architectural weakness and we started working on migrating it over to a more modern solution. This would give us far greater architectural choices as well as greater degrees of durability for our critical data.
After an evaluation of our choices we made the decision to move databases to Aurora Postgres. Nearly all Red Hat customers running Quay on-premises use Postgres instead of MySQL so it’s a familiar and well tested database for us. We chose Aurora since Quay.io runs in AWS and it made sense to stay within the AWS portfolio. Aurora provides many architectural and operational benefits over a dedicated RDS instance that we were eager to explore.
State of Quay.io pre-migration
In mid 2023 it was clear that our migration was becoming more and more necessary. Quay’s code has always been rather connection hungry and for the most part this hasn’t been an issue. The design of Quay.io is extremely simple (on purpose), with a set of stateless OpenShift pods working against a database (or Redis cache). Since our traffic patterns are predominantly reads we have optimized to put as few hops between an image pull event and the database. Inside a Quay pod is a vast ecosystem of worker processes that handle the web UI, the registry itself and asynchronous tasks such as garbage collection and coordination with Clair for security scans. This design is rooted in our original pre-OpenShift architecture.
On a normal day, Quay.io would run with anywhere between 7K to 9K connections and even sustain bursts in excess of 10K based on traffic volumes.

Traffic on Quay.io has steadily risen over the past few years as more customers have started using it. Red Hat itself is now serving its entire product catalog of images out of Quay.io and this has resulted in an ever growing steady-state connection count. We were running on a very large MySQL instance and things were running smoothly. That is, until they weren’t. When we would sustain a large traffic spike, or our read IOPS began to grow too large this could cause trouble. The worker processes within the Quay pods would have difficulty getting connections. As a result they would restart, requesting yet more connections, eventually causing a thundering herd of requests that would crash our RDS instance.
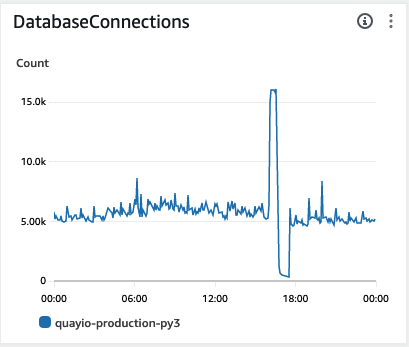
Here you can see the connection graph from an outage on November 8th, 2023. Everything is going fine until a small traffic burst causes a connection storm and eventual downtime. Clearly we needed to fix this.
Migrating the database
To handle the actual database migration, we decided to use AWS Data Migration Service (DMS). This would take care of many of the low level details involved with converting from MySQL to Postgres. We would use DMS to create a brand new Postgres database over the course of a few days and then use DMS to keep it in sync with MySQL until it was time for the migration event.
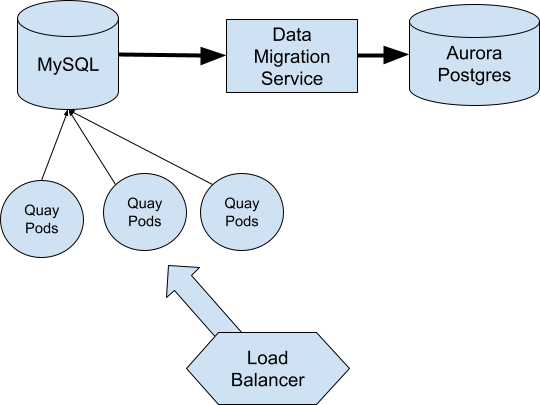
The migration procedure would be to shift Quay.io into read-only mode so the databases could be kept consistent while we restarted our Pods against the new database. Then we could re-enable writes and then reverse the DMS synchronization to capture Postgres changes back to MySQL just in case we needed to revert for any reason.
Early in the morning on Sunday, November 12th, 2023 our team carried out the migration and it went exactly as planned. We brought up our primary Quay.io Pods on Aurora Postgres and everything looked good. After four hours we closed the maintenance window and our site reliability engineering (SRE) team kept an eye on the database load.
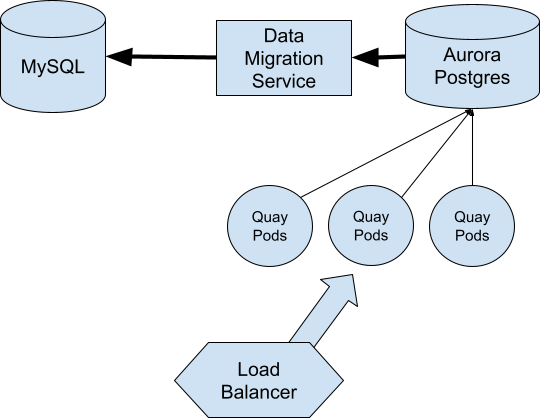
Then just after noon we were paged back into an incident with our SRE team. The performance of Quay.io was beginning to degrade quickly. We moved all of our traffic over to the secondary region and began to investigate.
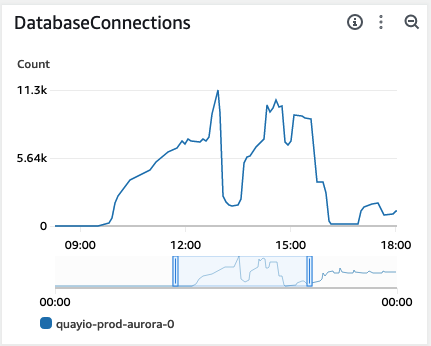
Looking at the database connections we immediately saw the issue. For some reason, Quay was never releasing any of its connections. Eventually we hit the server’s maximum, taking down the database.
Further investigation showed that unlike our original MySQL RDS instance, the Aurora Postgres instance was not configured to automatically terminate idle connections after a short time period. We realized we were seeing the same underlying behavior that drove some of our pre-migration outages happening in slow motion. We added a new configuration setting to our Object Relational Mapping (ORM) framework to perform the idle connection termination and instantly we saw the Aurora connection count rise and fall steadily.
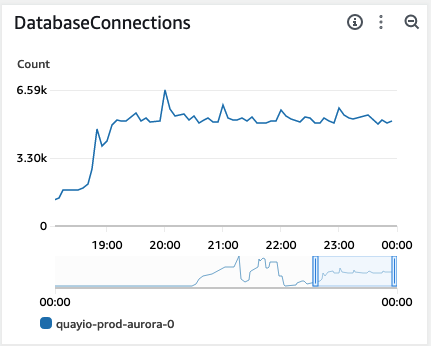
This gave us confidence to move all of our traffic back over to the primary region and re-enable write behaviors.
Migrating data is a dangerous business
On Monday morning we returned to work and our support team began escalating customer issues that showed some pulls were no longer working. As a registry service, these support escalations take top priority and our on-call team began to investigate. Reviewing the manifests that were no longer pulling, we noticed a trend— they were all truncated.
The manifest is an essential part of all container images: it is a JSON structure that ties the layers together to form the container image plus configuration data like the type of image. Images with a lot of layers would have a larger manifest. We did a few tests and confirmed that new pushes of large manifests were working fine, it appeared to just be with manifests that had already been part of our MySQL database before the migration.
We quickly stood up our pre-migration MySQL snapshot and created a utility script that would compare all manifests between MySQL and our new Aurora Postgres instance. This was not a quick job as Quay.io is currently managing over 60 million images. Our first version of the script ran sequentially and we quickly realized it would take far too long to complete. We adapted the script to run on ranges of manifests using multiple parallel instances and it completed in a matter of a few hours.
While the truncated manifests were being restored, we began to investigate how this happened. Somehow this had eluded our migration verification scripts (which were primarily focused on row counts and schema consistency). Deeper review of our DMS configuration showed that it was converting ‘longtext’ fields in MySQL to the internal ‘nclob’ type. In our configuration however, we noticed the following setting:
"FullLobMode": false,
"LobChunkSize": 64,
"LimitedSizeLobMode": true,
"LobMaxSize": 32,
This meant that we had been running DMS in “Limited LOB” mode and this was truncating any ‘nclob’ fields to 32K. We immediately re-scanned our MySQL schema to look for any other places this issue might have bitten us. We discovered that indeed, some image labels and repository descriptions may have been affected. We created new utility scripts to cover those cases as well.
Things still aren’t right
Over the next few weeks we continued to get sporadic reports of image pull failures from customers. We couldn’t find a reliable pattern for the failures and overall our Postgres instance looked healthy. However we began to notice that high traffic spikes were continuing to give us troubles. Even our own internal push/pull monitors were alerting occasionally and the database just seemed to get laggy despite an abundance of resources.
One challenge with troubleshooting issues like this is that we usually cannot reproduce them in a local or load testing environment. We knew our connection count was still too high, so we began to dig into our production metrics. We started by comparing the number of available connections to the number of actual connections in use by all of the registry workers across all of the Pods. This showed us that we were sitting on literally thousands of available connections but only using a small portion of them.
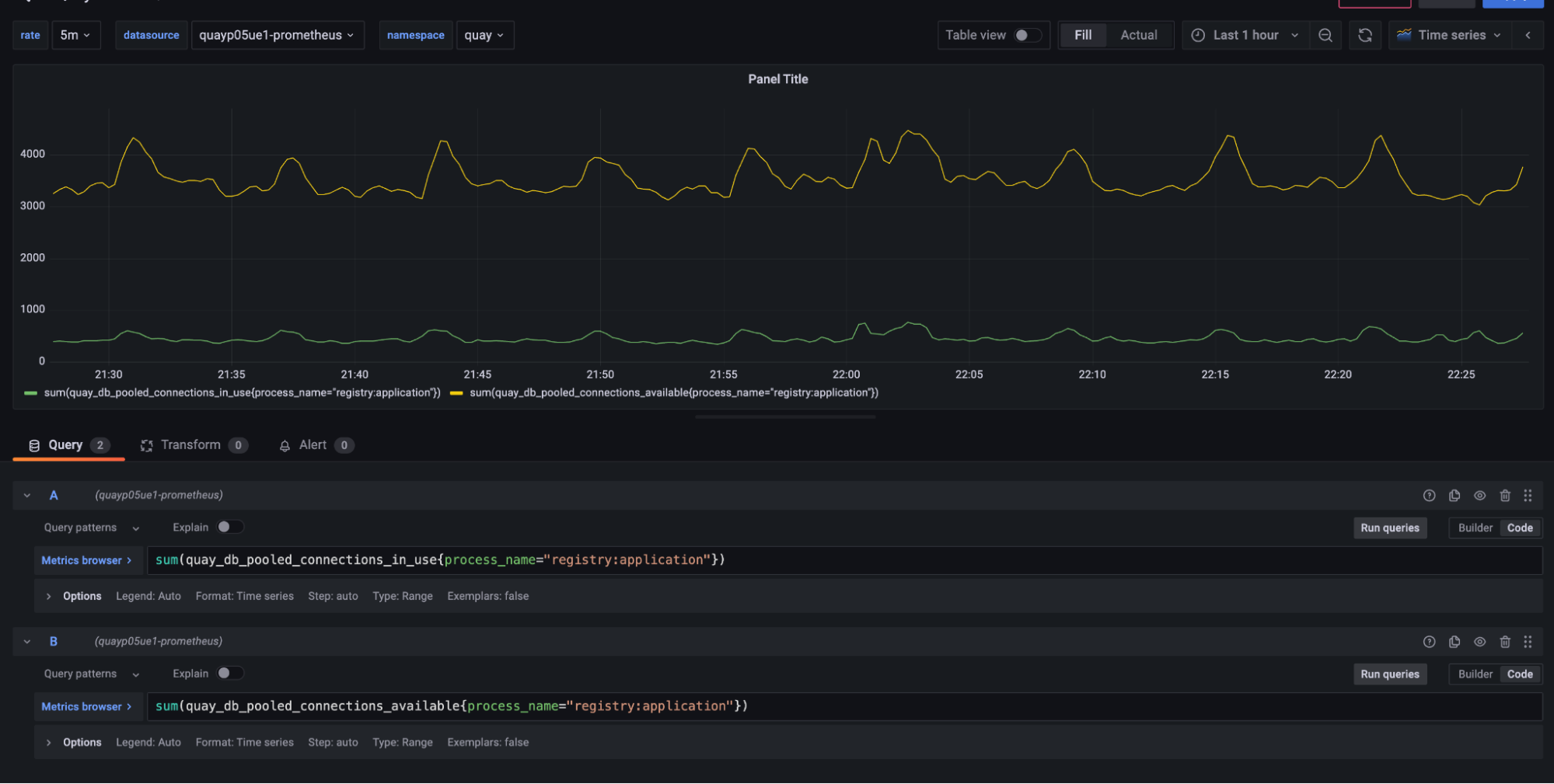
The next question was how much we could reduce the connection pool size itself. This isn’t as simple as changing a single number as we allocate a separate connection pool for each work instance. If we choose too low it might cause the workers to get backed up again and we would have another outage. We started by isolating the connection behavior for a single worker process instance.
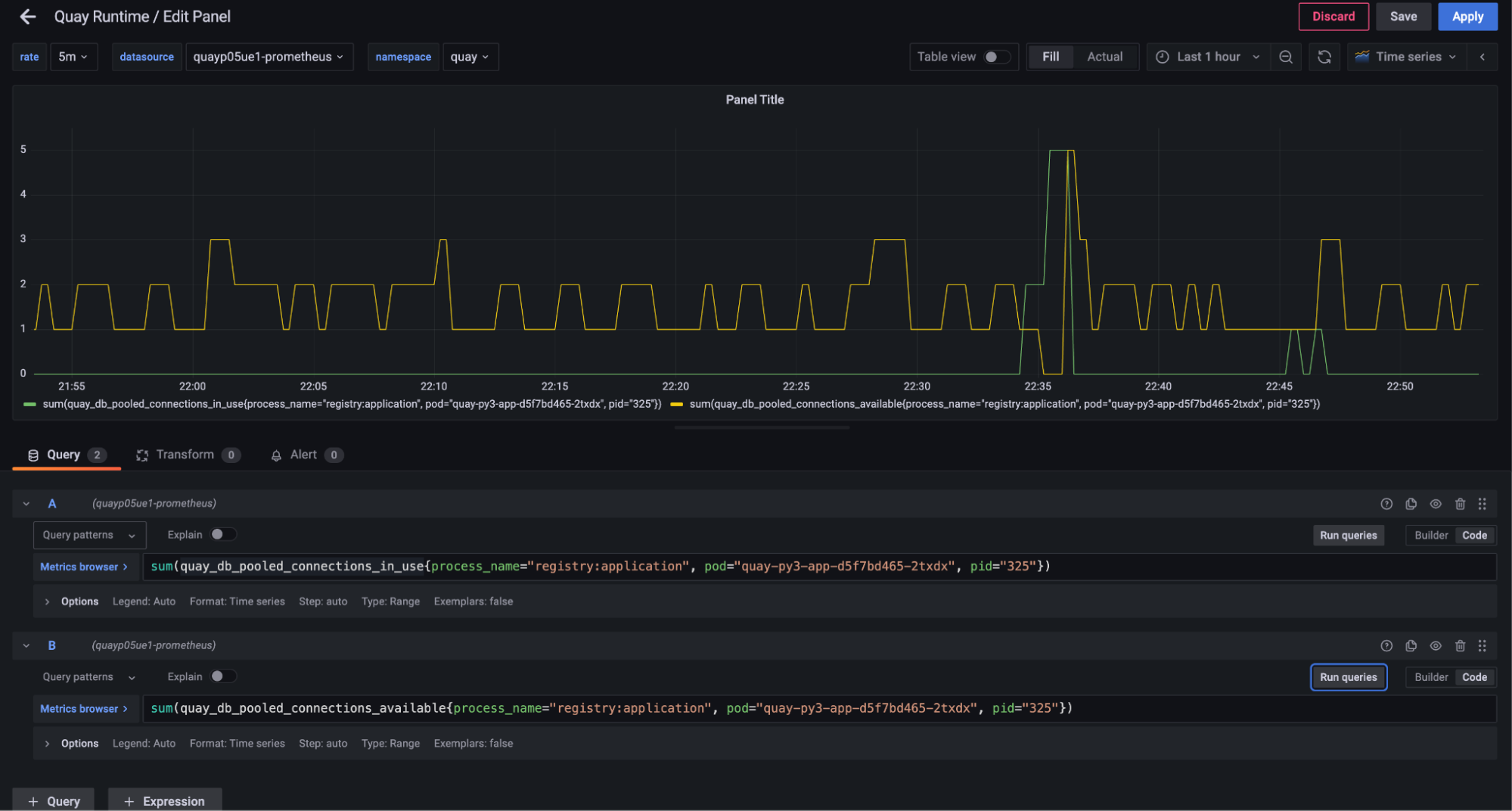
This was eye opening as it showed that even under load, this registry worker process (handling pushes and pulls) was holding on to up to five connections (out of a pool of 10) but only needing them for a few seconds across an entire hour.
Looking at the same graph for all registry worker processes across all of the pods showed a similar trend.
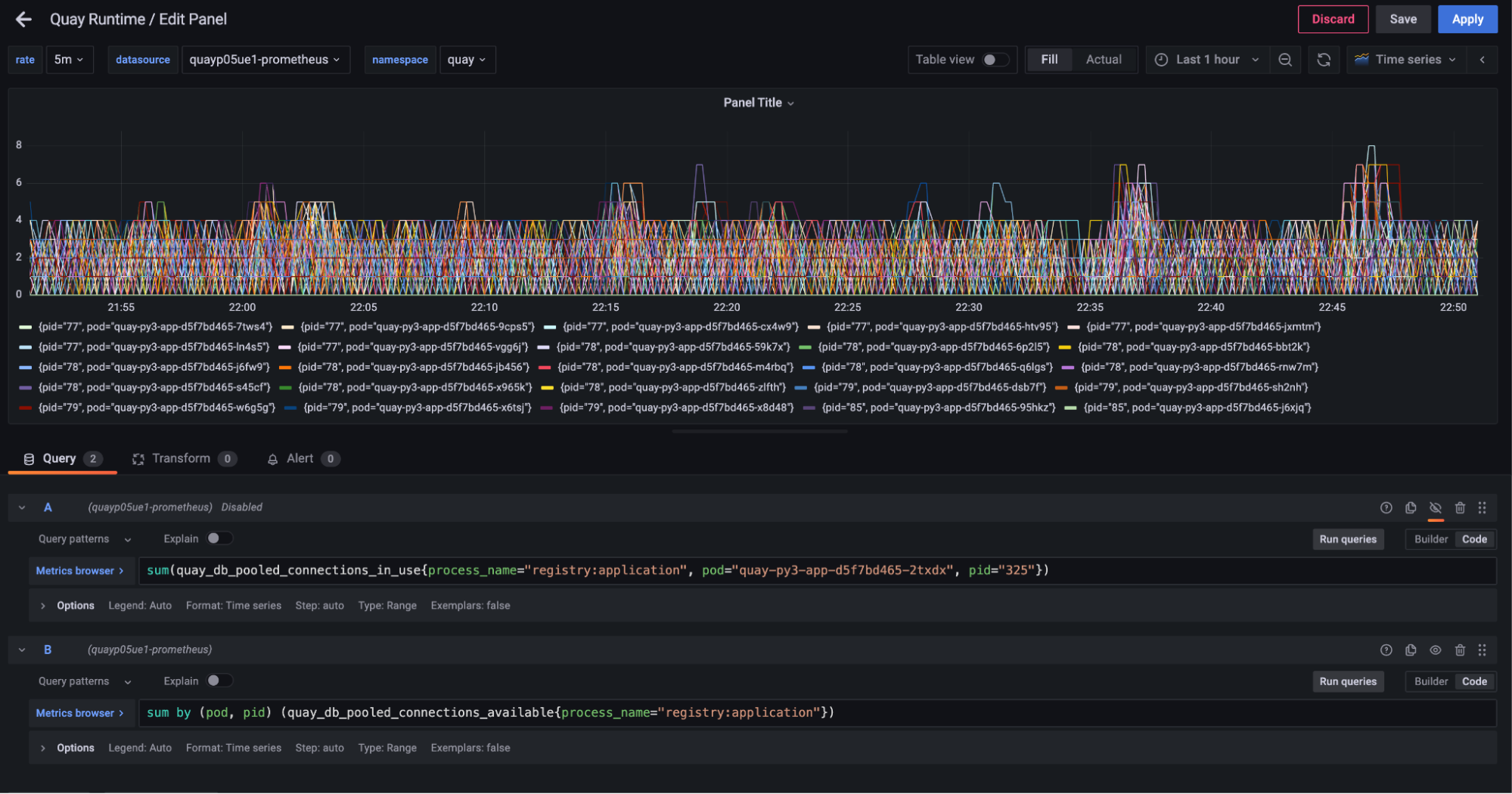
Across all of the workers, none were ever using more than a handful of connections during regular traffic levels, despite each keeping unused connections alive. We could also see that the load on each worker was not equal. Some workers were using more connections than others. We ran a check on the request counts going to each of our pods to see how our overall load balancing was working.
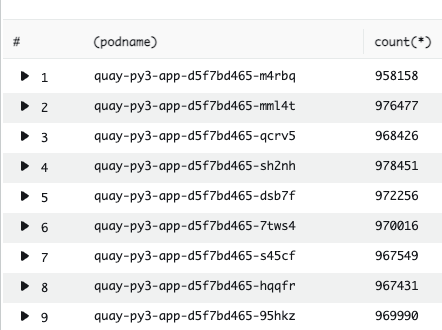
At the OpenShift level we saw consistent load balancing across all of our pods. Within each pod, however, we were seeing less evenly distributed requests. This meant that many of our worker processes were sitting idle yet holding on to database connections. We now knew that we could reduce the number of overall workers within our Pods and reduce our overall connection count without affecting our performance.
The two worker processes sitting on the most idle connections were the registry and web API workers. As an initial test, and to avoid any possibility of affecting image pulls, we chose to reduce the web API workers by half.
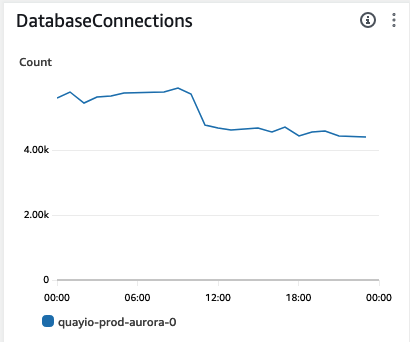
After dropping the web API worker count we saw an immediate drop in our overall connections. Even better, we saw a sudden boost in UI responsiveness and overall speed.
This gave us the confidence to then adjust our registry worker count from 64 per pod to 16 per pod.
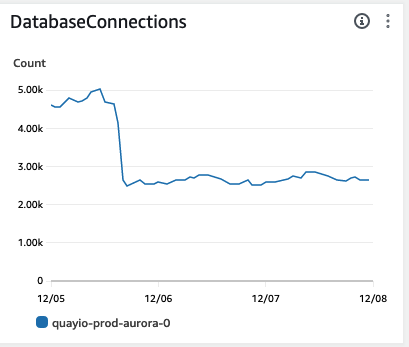
There was another immediate drop in database connections and no impact to performance. We stopped getting periodic monitor alerts and our number of HTTP 500 Internal Server Errors dropped to negligible levels. One concern was how this was affecting our CPU load since the traffic was now focused more tightly on a smaller number of worker processes.
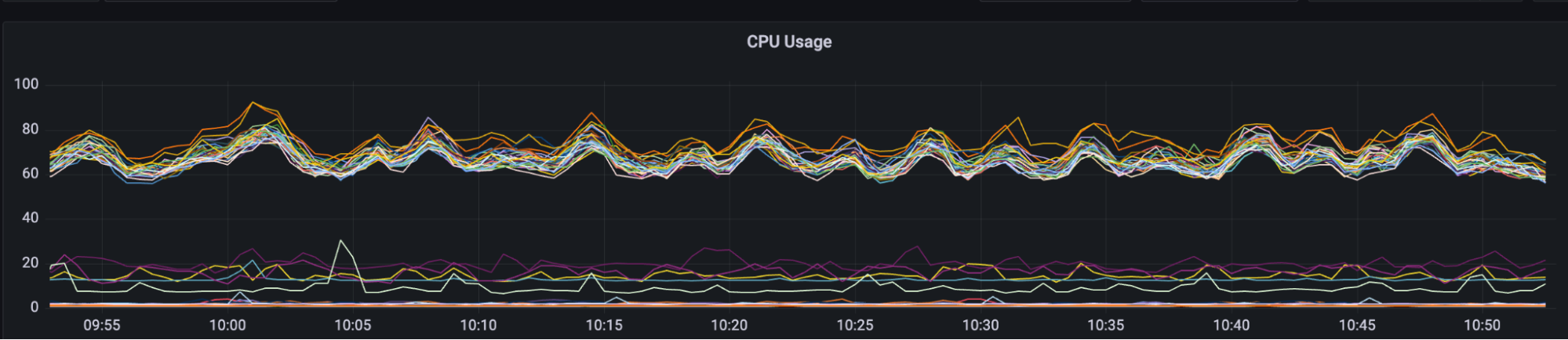
Across our production cluster we saw elevated CPU levels but nothing worrisome. And we could certainly scale that out easily enough as needed.
What have we learned?
After so much change and instability here's some of what we learned along the way.
- Your code will behave differently on a different database, especially under load, even if it’s one you know well. While Quay itself runs just fine on Postgres for our on-prem customers, this was the first time applying the full scale of Quay.io on a Postgres database. The way Quay organized its database connections suited MySQL databases well across various traffic patterns, but was unsuitable for Postgres at this scale.
- When migrating database platforms, you cannot have too many methods of verification. As we discovered, we needed row count-based verification, schema data type validation and even some form of content sampling verification to be really sure our migration was complete and correct.
What’s next?
Stabilizing our database connection load is only the first of a few things we’d like to explore in the coming months, including:
- Leveraging Aurora read replicas. Currently we are still just using a single instance for reads and writes. We have started to look at how Quay can utilize read replicas to spread our workload out and gain even more scale and improved performance. Initial findings have shown that the Aurora internal replication lag is causing some issues for our UI and rapid push/pull traffic, but we’re confident we can work around that.
- Introducing a connection proxy. Because our new database is so connection count-sensitive we are also looking at adding a proxy like pgbouncer in between our pods and the database to ensure it doesn’t suffer from connection storms. We have seen this proxy is adding some latency to our requests, however, so we haven’t added it yet. It remains something we are evaluating.
Wrap up
We hope this write up has been useful in shedding light on Quay.io’s instability during the last months of 2023. Our customers trust us with the images that drive their businesses and we take our uptime very seriously. The Quay team remains committed to learning from these incidents and continuously improving how we operate Quay.io for the greatest stability and availability.
About the authors

Syed is the technical lead for quay.io. He joined RedHat in 2021 and has been working to make quay.io more scaleable and efficient.

I joined Red Hat in 2019 to look after Quay, quay.io and the OpenShift Image Registry. I have been in software all of my career, doing development and product management both as a customer and a vendor.
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges

Original shows
Entertaining stories from the makers and leaders in enterprise tech
Products
- Red Hat Enterprise Linux
- Red Hat OpenShift
- Red Hat Ansible Automation Platform
- Cloud services
- See all products
Tools
- Training and certification
- My account
- Customer support
- Developer resources
- Find a partner
- Red Hat Ecosystem Catalog
- Red Hat value calculator
- Documentation
Try, buy, & sell
Communicate
About Red Hat
We’re the world’s leading provider of enterprise open source solutions—including Linux, cloud, container, and Kubernetes. We deliver hardened solutions that make it easier for enterprises to work across platforms and environments, from the core datacenter to the network edge.
Select a language
Red Hat legal and privacy links
- About Red Hat
- Jobs
- Events
- Locations
- Contact Red Hat
- Red Hat Blog
- Diversity, equity, and inclusion
- Cool Stuff Store
- Red Hat Summit