
This blog shows how to use the Cluster Autoscaler and Machine API MachineAutoscaler to automatically scale an OpenShift cluster up or down based on traffic load. This can help to save resources and power costs by ensuring that the cluster only uses the number of nodes that it needs to handle the current load.
NOTE: Throughout this blog, we used the terms "scale up" or "scale down" to refer to increase or decrease the worker nodes of an OpenShift cluster, instead of using the terms "scale out" or "scale in."
Machine API overview
The Machine API is a combination of primary resources that are based on the upstream Cluster API(CAPI) project and custom OpenShift Container Platform resources.
For OpenShift Container Platform 4.12 clusters, the Machine API performs all node host provisioning management actions after the cluster installation finishes. Because of this system, OpenShift Container Platform 4.12 offers an elastic, dynamic provisioning method on top of public or private cloud infrastructure including Baremetal.
Architecture
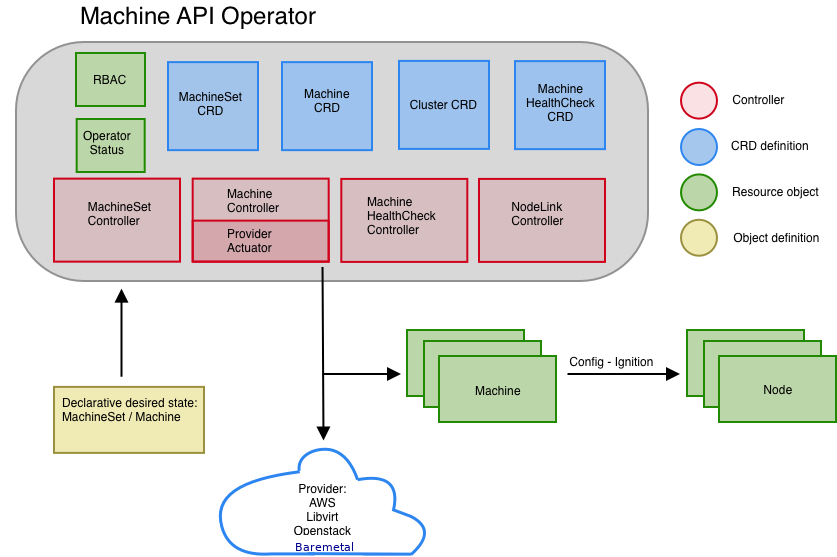
The Machine API Operator provisions the following resources:
- MachineSet
- Machine
ClusterAutoscalerMachineAutoscaler
The following custom resources add more capabilities to your cluster:
Machine autoscaler
The MachineAutoscaler resource automatically scales compute machines in a cloud. You can set the minimum and maximum scaling boundaries for nodes in a specified compute machine set, and the machine autoscaler maintains that range of nodes.
The MachineAutoscaler object takes effect after a ClusterAutoscaler object exists. Both ClusterAutoscaler and MachineAutoscaler resources are made available by the ClusterAutoscalerOperator object. Additionally, the MachineAutoscaler is a Kubernetes controller that watches for changes to MachineSet objects. When the MachineAutoscaler detects that the number of machines in the cluster falls below the desired number, it will create new machines of the specified type.
Cluster autoscaler
This resource is based on the upstream cluster autoscaler project. In the OpenShift Container Platform implementation, it is integrated with the Machine API by extending the compute machine set API. The Cluster Autoscaler is a Kubernetes controller that watches for pods that are unable to schedule on any of the existing nodes in the cluster. When the Cluster Autoscaler detects pods that are unable to schedule, it will add new nodes to the cluster.
You can use the cluster autoscaler to manage your cluster in the following ways:
- Set cluster-wide scaling limits for resources such as cores, nodes, memory, and GPU
- Set the priority so that the cluster prioritizes pods and new nodes are not brought online for less important pods
- Set the scaling policy so that you can scale up nodes but not scale them down
How OpenShift Cluster and Machine Autoscaler Works
In the scaling-up scenario, the Cluster Autoscaler periodically evaluate whether there are any unschedulable pods using this timer (--scan-interval, default:10s) and when the number of pending (un-schedulable) pods increases due to resource shortages and works to add additional nodes to the cluster.
Then MachineAutoScaler automatically scales the MachineSet desired state up and down, and limits between the minimum and maximum number of the machine that is configured, and ClusterAutoScaler decides the scaling up and down based on various parameters such as CPU, memory, etc. All of this works independently of underlying cloud infrastructure! The diagram below illustrates how it works.
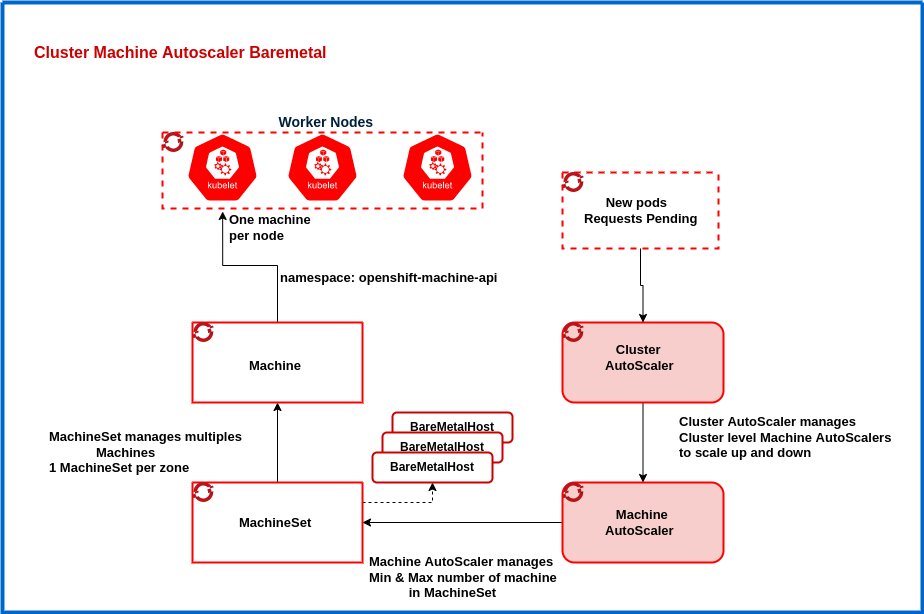
A similar mechanism exists for the scale-down scenario where CA may consolidate pods onto fewer nodes to free up a node and terminate it. This can be useful for reducing costs or for managing resources during periods of low traffic. However, it is important to note that moving pods can cause some disruption to applications. Therefore, it is important to carefully consider the impact of scale-down before implementing it.
Note: For Baremetal as Cloud-Provider, user must prepare BMH for new nodes that need to be scale up and this task can be done once. More new nodes can be added up as much as needed. The details how to create BMH is included in later sections
Cluster Autoscaler Tables
Cluster Autoscaler Parameters
Click here Raw Cluster Autoscaler Parameters Tables
Cluster Autoscaler Scale-down Spec Parameters
| Parameter | Description | Default |
|---|---|---|
enabled |
Should CA scale down the cluster | true |
delayAfterAdd |
How long after scale up that scale down evaluation resumes | 10 minutes |
delayAfterDelete |
How long after node deletion that scale down evaluation resumes, defaults to scan-interval | scan-interval |
delayAfterFailure |
How long after scale down failure that scale down evaluation resumes | 3 minutes |
unneededTime |
How long a node should be unneeded before it is eligible for scale down | 10 minutes |
utilizationThreshold |
Scale-in/down threshold (Requests value to CPU and Memory) | 0.5 (50%) |
Cluster Autoscaler Scale-up Spec Parameters
| Option | Default | Overview |
|---|---|---|
scan-interval |
10 seconds | Interval to evaluate scale out/down |
maxNodeProvisionTime |
15 mins | How long until a Node is scaled out and registered with the Master |
delayAfterAdd |
10 mins | Period after scale-out to evaluate scale-in |
maxPodGracePeriod |
10 mins | Maximum number of seconds CA waits for pod termination when trying to scale down a node |
Prerequisites
- OpenShift 4.12.x
- Initial OpenShift Infrastructure topology with 3+2 setup (this is just an example)
$ oc get node
NAME STATUS ROLES AGE VERSION
master-0 Ready control-plane,master 18h v1.25.8+27e744f
master-1 Ready control-plane,master 19h v1.25.8+27e744f
master-2 Ready control-plane,master 19h v1.25.8+27e744f
worker-0 Ready worker 18h v1.25.8+27e744f
worker-1 Ready worker 18h v1.25.8+27e744f
- An existing machineset for BM and normally if deployed with 3+1+, then there is one already created.
Otherwise it requires to create machinesets follow this link Create Machineset
$ oc -n openshift-machine-api get machinesets
NAME DESIRED CURRENT READY AVAILABLE AGE
abi-sb5b6-worker-0 2 2 2 2 19h
- New Servers with IP plan for BMH creation
- Baremetal servers type tested with Dell but with HP or other HW servers type can be supported as long as the BMC is RedFish or IPMI compatible
Prepare OpenShift Cluster and Machine Autoscaler
Create BMH, Secret and NMState for new node worker-2
More details how to create BMH click Create BMH
bmh-worker-2.yaml:
---
apiVersion: v1
kind: Secret
metadata:
name: worker-2
namespace: openshift-machine-api
type: Opaque
stringData:
nmstate: |
interfaces:
- name: eno1
type: ethernet
state: up
ipv4:
address:
- ip: 192.168.24.91
prefix-length: 25
enabled: true
dns-resolver:
config:
server:
- 192.168.24.80
routes:
config:
- destination: 0.0.0.0/0
next-hop-address: 192.168.24.1
next-hop-interface: eno1
---
apiVersion: v1
kind: Secret
metadata:
name: worker-2-bmc-secret
namespace: openshift-machine-api
type: Opaque
data:
username: cm9vdAo=
password: Y2FsdmluCg==
---
apiVersion: metal3.io/v1alpha1
kind: BareMetalHost
metadata:
name: worker-2
namespace: openshift-machine-api
spec:
online: True
bootMACAddress: b8:ce:f6:56:48:aa
bmc:
address: idrac-virtualmedia://192.168.24.159/redfish/v1/Systems/System.Embedded.1
credentialsName: worker-2-bmc-secret
disableCertificateVerification: True
username: root
password: calvin
rootDeviceHints:
deviceName: /dev/sdb
preprovisioningNetworkDataName: worker-2
$ oc apply -f bmh-worker-2.yaml
$ oc -n openshift-machine-api get bmh
NAME STATE CONSUMER ONLINE ERROR AGE
master-0 unmanaged abi-sb5b6-master-0 true 19h
master-1 unmanaged abi-sb5b6-master-1 true 19h
master-2 unmanaged abi-sb5b6-master-2 true 19h
worker-0 unmanaged abi-sb5b6-worker-0-pjpcl true 19h
worker-1 unmanaged abi-sb5b6-worker-0-xmfg9 true 19h
worker-2 available abi-sb5b6-worker-0-4qftf true 3h
$ oc -n openshift-machine-api get secret|grep worker-2
worker-2 Opaque 1 3h2m
worker-2-bmc-secret Opaque 2 17h
After create secrets and BMH, it will initiate the ironic to register and inspect the new worker-2 and then wait until it becomes available as shown in above
Deploying Cluster Autoscaler
- Cluster AutoScaler Definition
cluster-autoscaler.yaml:
apiVersion: "autoscaling.OpenShift.io/v1"
kind: "ClusterAutoscaler"
metadata:
name: "default"
spec:
podPriorityThreshold: -10
resourceLimits:
maxNodesTotal: 6
scaleDown:
enabled: true
delayAfterAdd: 5m
delayAfterDelete: 5m
delayAfterFailure: 30s
unneededTime: 60s
For details of each parameters, please click here Autoscaler-Definition
Note: since we perform cluster autoscaler on BM infrastructure so CPU and Memory are not specified under resourceLimits but for maxNodesTotal, it must be higher than initial setup e.g. 3+2 and + worker-2 = 6. The default name can not be changed and only one ClusterAutoscaler per Cluster.
Important: Be sure that the maxNodesTotal value in the ClusterAutoscaler resource definition that you create is large enough to account for the total possible number of machines in your cluster. This value must encompass the number of control plane machines and the possible number of compute machines that you might scale to.
- Create Cluster Autoscaler
New pod will createcluster-autoscaler-default
$ oc apply -f cluster-autoscaler.yaml
$ oc -n openshift-machine-api get pods
NAME READY STATUS RESTARTS AGE
cluster-autoscaler-default-84df578b46-tp7hx 1/1 Running 0 3h15m
- Machine Autoscaler Definition
machine-autoscaler.yaml:
apiVersion: "autoscaling.OpenShift.io/v1beta1"
kind: "MachineAutoscaler"
metadata:
name: "abi-sb5b6-worker-0"
namespace: "openshift-machine-api"
spec:
minReplicas: 1
maxReplicas: 3
scaleTargetRef:
apiVersion: machine.Openshift.io/v1beta1
kind: MachineSet
name: abi-sb5b6-worker-0
For MachineSet name, it can retrieve with this cmd:
$ oc -n openshift-machine-api get machinesets
NAME DESIRED CURRENT READY AVAILABLE AGE
abi-sb5b6-worker-0 2 2 2 2 20h
Define and update the minReplicas and maxReplicas accordingly
Note: Minimum is >= 1 Maximum needs to be correlate with maxNodesTotal from CA
- Deploying Machine Autoscaler
$ oc apply -f machine-autoscaler.yaml
$ oc -n openshift-machine-api describe machinesets abi-sb5b6-worker-0
Name: abi-sb5b6-worker-0
Namespace: Openshift-machine-api
Labels: machine.openshift.io/cluster-api-cluster=abi-sb5b6
machine.openshift.io/cluster-api-machine-role=worker
machine.openshift.io/cluster-api-machine-type=worker
Annotations: autoscaling.openshift.io/machineautoscaler: openshift-machine-api/abi-sb5b6-worker-0
machine.openshift.io/cluster-api-autoscaler-node-group-max-size: 3
machine.openshift.io/cluster-api-autoscaler-node-group-min-size: 1
Start Scale-up the OpenShift Cluster for worker-2 Node
- Create a test nginx deployment POD
test-nginx-deployment.yaml:
apiVersion: apps/v1
kind: Deployment
metadata:
name: test-deployment
spec:
replicas: 1
selector:
matchLabels:
app: test-app
template:
metadata:
labels:
app: test-app
spec:
containers:
- name: test-container
image: quay.io/avu0/nginx:init
command: ["/bin/sh", "-ec", "while :; do echo '.'; sleep infinity ; done"]
resources:
limits:
memory: 1Gi
cpu: "1"
requests:
memory: 1Gi
cpu: "1"
$ oc apply -f test-nginx-deployment.yaml
$ oc -n test get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
test-deployment 1/1 1 1 18h
- Start increase the CPU/MEMORY load by scale out more nginx PODS
$ oc -n test scale deployment/test-deployment --replicas=220
$ oc -n test get pod -o wide|grep Pending
test-deployment-547ff5b464-25wxp 0/1 Pending 0 11s <none> <none> <none> <none>
test-deployment-547ff5b464-2m27s 0/1 Pending 0 11s <none> <none> <none> <none>
test-deployment-547ff5b464-427vn 0/1 Pending 0 11s <none> <none> <none> <none>
test-deployment-547ff5b464-5kndf 0/1 Pending 0 11s <none> <none> <none> <none>
test-deployment-547ff5b464-6mkfb 0/1 Pending 0 11s <none> <none> <none> <none>
Checking scale-up logs:
The machineset will update automatic from 2 to 3 then new machine will create created and then for BMH of worker-2 will be provisioning and provisioned then machine for worker-2 will be running after all the installation is done
$ oc -n openshift-machine-api get machine
NAME PHASE TYPE REGION ZONE AGE
abi-sb5b6-master-0 Running 17h
abi-sb5b6-master-1 Running 17h
abi-sb5b6-master-2 Running 17h
abi-sb5b6-worker-0-gs6dn Running 19m
abi-sb5b6-worker-0-pjpcl Running 16h
abi-sb5b6-worker-0-xmfg9 Running 16h
$ oc -n openshift-machine-api get bmh
NAME STATE CONSUMER ONLINE ERROR AGE
master-0 unmanaged abi-sb5b6-master-0 true 17h
master-1 unmanaged abi-sb5b6-master-1 true 17h
master-2 unmanaged abi-sb5b6-master-2 true 17h
worker-0 unmanaged abi-sb5b6-worker-0-pjpcl true 17h
worker-1 unmanaged abi-sb5b6-worker-0-xmfg9 true 17h
worker-2 provisioned abi-sb5b6-worker-0-gs6dn true 31m
I0601 13:36:59.224467 1 scale_up.go:477] Best option to resize: MachineSet/OpenShift-machine-api/abi-sb5b6-worker-0
I0601 13:36:59.224480 1 scale_up.go:481] Estimated 1 nodes needed in MachineSet/OpenShift-machine-api/abi-sb5b6-worker-0
I0601 13:36:59.224496 1 scale_up.go:601] Final scale-up plan: [{MachineSet/OpenShift-machine-api/abi-sb5b6-worker-0 2->3 (max: 3)}]
I0601 13:36:59.224510 1 scale_up.go:700] Scale-up: setting group MachineSet/OpenShift-machine-api/abi-sb5b6-worker-0 size to 3
I0601 13:37:11.033718 1 static_autoscaler.go:445] No unschedulable pods
$ oc get nodes
NAME STATUS ROLES AGE VERSION
master-0 Ready control-plane,master 16h v1.25.8+27e744f
master-1 Ready control-plane,master 17h v1.25.8+27e744f
master-2 Ready control-plane,master 17h v1.25.8+27e744f
worker-0 Ready worker 16h v1.25.8+27e744f
worker-1 Ready worker 16h v1.25.8+27e744f
worker-2.abi.hubcluster-1.lab.eng.cert.redhat.com Ready worker 19m v1.25.8+27e744f
$ oc -n openshift-machine-api get machinesets
NAME DESIRED CURRENT READY AVAILABLE AGE
abi-sb5b6-worker-0 3 3 3 3 17h
Start Scale-down the OpenShift Cluster
- Decrease traffic loads by scale down test-deployment nginx PODS to 100
$ oc -n test scale deployment/test-deployment --replicas=100
Checking scale-down logs/info:
I0601 14:00:49.811893 1 delete.go:103] Successfully added DeletionCandidateTaint on node worker-2.abi.hubcluster-1.lab.eng.cert.redhat.com
I0601 14:01:00.815557 1 legacy.go:395] Scale-down calculation: ignoring 2 nodes unremovable in the last 5m0s
I0601 14:02:39.288038 1 drain.go:151] All pods removed from worker-2.abi.hubcluster-1.lab.eng.cert.redhat.com
- Checking machineset value should be
2
$ oc -n openshift-machine-api get machineset
NAME DESIRED CURRENT READY AVAILABLE AGE
abi-sb5b6-worker-0 2 2 2 2 17h
- Checking worker-2 node, BMH and Machine status
$ oc -n openshift-machine-api get bmh
NAME STATE CONSUMER ONLINE ERROR AGE
master-0 unmanaged abi-sb5b6-master-0 true 17h
master-1 unmanaged abi-sb5b6-master-1 true 17h
master-2 unmanaged abi-sb5b6-master-2 true 17h
worker-0 unmanaged abi-sb5b6-worker-0-pjpcl true 17h
worker-1 unmanaged abi-sb5b6-worker-0-xmfg9 true 17h
worker-2 deprovisioning abi-sb5b6-worker-0-gs6dn false 38m
NAME PHASE TYPE REGION ZONE AGE
abi-sb5b6-master-0 Running 17h
abi-sb5b6-master-1 Running 17h
abi-sb5b6-master-2 Running 17h
abi-sb5b6-worker-0-gs6dn Deleting 27m
abi-sb5b6-worker-0-pjpcl Running 16h
abi-sb5b6-worker-0-xmfg9 Running 16h
$ oc get no
NAME STATUS ROLES AGE VERSION
master-0 Ready control-plane,master 16h v1.25.8+27e744f
master-1 Ready control-plane,master 17h v1.25.8+27e744f
master-2 Ready control-plane,master 17h v1.25.8+27e744f
worker-0 Ready worker 16h v1.25.8+27e744f
worker-1 Ready worker 16h v1.25.8+27e744f
worker-2.abi.hubcluster-1.lab.eng.cert.redhat.com NotReady,SchedulingDisabled worker 9m41s v1.25.8+27e744f
- Finally checking after sometime and worker-2 reboot
$ oc -n openshift-machine-api get bmh
NAME STATE CONSUMER ONLINE ERROR AGE
master-0 unmanaged abi-sb5b6-master-0 true 17h
master-1 unmanaged abi-sb5b6-master-1 true 17h
master-2 unmanaged abi-sb5b6-master-2 true 17h
worker-0 unmanaged abi-sb5b6-worker-0-pjpcl true 17h
worker-1 unmanaged abi-sb5b6-worker-0-xmfg9 true 17h
worker-2 available false 49m
$ oc -n openshift-machine-api get machine
NAME PHASE TYPE REGION ZONE AGE
abi-sb5b6-master-0 Running 17h
abi-sb5b6-master-1 Running 17h
abi-sb5b6-master-2 Running 17h
abi-sb5b6-worker-0-pjpcl Running 17h
abi-sb5b6-worker-0-xmfg9 Running 17h
$ oc get nodes
NAME STATUS ROLES AGE VERSION
master-0 Ready control-plane,master 16h v1.25.8+27e744f
master-1 Ready control-plane,master 17h v1.25.8+27e744f
master-2 Ready control-plane,master 17h v1.25.8+27e744f
worker-0 Ready worker 16h v1.25.8+27e744f
worker-1 Ready worker 16h v1.25.8+27e744f
Note: The worker-2 after being scaled down, it will try to deprovisioning(BMH) and Deleting(Machine) and worker-2 server will reboot and shutdown/poweroff
Troubleshooting and Logs Checking Hints
- Check Logs from cluster-autoscaler-default
$ oc -n openshift-machine-api logs cluster-autoscaler-default-84df578b46-tp7hx -f
- Check Event Logs from OpenShift-Machine-API Namespace for Autoscaler activities
$ oc -n openshift-machine-api get event -o custom-columns="LAST SEEN:{lastTimestamp},KIND:{involvedObject.kind},REASON:{reason},SOURCE:{source.component},MESSAGE:{message}" -w
LAST SEEN KIND REASON SOURCE MESSAGE
2023-06-01T16:15:03Z BareMetalHost DeprovisioningComplete metal3-baremetal-controller Image deprovisioning completed
2023-06-01T19:07:47Z BareMetalHost DeprovisioningStarted metal3-baremetal-controller Image deprovisioning started
2023-06-01T16:58:58Z BareMetalHost DeprovisioningStarted metal3-baremetal-controller Image deprovisioning started
2023-06-01T16:15:04Z BareMetalHost PowerOff metal3-baremetal-controller Host soft powered off
2023-06-01T18:48:53Z BareMetalHost ProvisioningComplete metal3-baremetal-controller Image provisioning completed for
2023-06-01T16:34:54Z BareMetalHost ProvisioningComplete metal3-baremetal-controller Image provisioning completed for
2023-06-01T16:18:38Z BareMetalHost ProvisioningStarted metal3-baremetal-controller Image provisioning started for
2023-06-01T18:41:50Z BareMetalHost ProvisioningStarted metal3-baremetal-controller Image provisioning started for
2023-06-01T16:58:58Z Machine DrainProceeds machine-drain-controller Node drain proceeds
2023-06-01T16:58:58Z Machine Deleted machine-drain-controller Node "worker-2.abi.hubcluster-1.lab.eng.cert.redhat.com" drained
2023-06-01T16:58:58Z Machine DrainSucceeded machine-drain-controller Node drain succeeded
2023-06-01T19:07:47Z Machine DrainProceeds machine-drain-controller Node drain proceeds
2023-06-01T19:07:47Z Machine Deleted machine-drain-controller Node "worker-2.abi.hubcluster-1.lab.eng.cert.redhat.com" drained
2023-06-01T19:07:47Z Machine DrainSucceeded machine-drain-controller Node drain succeeded
2023-06-01T19:07:47Z MachineAutoscaler SuccessfulUpdate machine_autoscaler_controller Updated MachineAutoscaler target: OpenShift-machine-api/abi-sb5b6-worker-0
2023-06-01T18:31:55Z ConfigMap ScaledUpGroup cluster-autoscaler Scale-up: setting group MachineSet/OpenShift-machine-api/abi-sb5b6-worker-0 size to 3 instead of 2 (max: 3)
2023-06-01T18:31:56Z ConfigMap ScaledUpGroup cluster-autoscaler Scale-up: group MachineSet/OpenShift-machine-api/abi-sb5b6-worker-0 size set to 3 instead of 2 (max: 3)
2023-06-01T19:07:47Z ConfigMap ScaleDown cluster-autoscaler Scale-down: node worker-2.abi.hubcluster-1.lab.eng.cert.redhat.com removed with drain
2023-06-01T16:58:57Z ConfigMap ScaleDownEmpty cluster-autoscaler Scale-down: removing empty node "worker-2.abi.hubcluster-1.lab.eng.cert.redhat.com"
2023-06-01T16:58:58Z ConfigMap ScaleDownEmpty cluster-autoscaler Scale-down: empty node worker-2.abi.hubcluster-1.lab.eng.cert.redhat.com removed
2023-06-01T16:33:49Z ConfigMap ScaleUpTimedOut cluster-autoscaler Nodes added to group MachineSet/OpenShift-machine-api/abi-sb5b6-worker-0 failed to register within 15m11.328102816s
2023-06-01T18:47:04Z ConfigMap ScaleUpTimedOut cluster-autoscaler Nodes added to group MachineSet/OpenShift-machine-api/abi-sb5b6-worker-0 failed to register within 15m7.939004207s
2023-06-01T19:07:16Z ConfigMap ScaleDown cluster-autoscaler Scale-down: removing node worker-2.abi.hubcluster-1.lab.eng.cert.redhat.com, utilization: {0.02768586387434555 0.021352461143225622 0 cpu 0.02768586387434555}, pods to reschedule: test-deployment-547ff5b464-7hjfq,test-deployment-547ff5b464-47dq2
2023-06-01T19:06:35Z ClusterAutoscaler SuccessfulUpdate cluster_autoscaler_controller Updated ClusterAutoscaler deployment: OpenShift-machine-api/cluster-autoscaler-default
2023-06-01T16:15:03Z BareMetalHost DeprovisioningComplete metal3-baremetal-controller Image deprovisioning completed
2023-06-01T16:15:04Z BareMetalHost PowerOff metal3-baremetal-controller Host soft powered off
Links
- Cluster Autoscaler FAQ
- OpenShift 4.12 Cluster Autoscaler and MAPI
- Cluster Autoscaler Operator
- Machine API Operator
- OpenShift Cluster Autoscaler API IO v1
- Cluster Autoscaler Example YAML
- Machine Lifecycle UML Flow
Observations
Performing the Cluster and Machine Autoscaler using Baremetal as a cloud provider can have some drawbacks. The time it takes to power on and off Baremetal nodes can vary depending on the specific hardware and software configuration. However, during scale up or down, the Machine Controller initiates the power on/off of the node to do provision or deprovisioning, and it can take several minutes to power on a Baremetal node (a couple of reboots) and up to 8 minutes to power it off and reprovision the BMH node to be available and be ready for scale up again.
For example, if an autoscaler is configured to scale up a cluster of Baremetal nodes in response to increased demand, it may take several minutes for the new nodes to be powered on and ready to join the existing cluster. This can lead to a delay in the delivery of new services or applications to users.
Sugli autori

{kind=link}
Altri risultati simili a questo
Ricerca per canale

Automazione
Novità sull'automazione IT di tecnologie, team e ambienti

Intelligenza artificiale
Aggiornamenti sulle piattaforme che consentono alle aziende di eseguire carichi di lavoro IA ovunque

Hybrid cloud open source
Scopri come affrontare il futuro in modo più agile grazie al cloud ibrido

Sicurezza
Le ultime novità sulle nostre soluzioni per ridurre i rischi nelle tecnologie e negli ambienti

Edge computing
Aggiornamenti sulle piattaforme che semplificano l'operatività edge

Infrastruttura
Le ultime novità sulla piattaforma Linux aziendale leader a livello mondiale

Applicazioni
Approfondimenti sulle nostre soluzioni alle sfide applicative più difficili

Serie originali
Raccontiamo le interessanti storie di leader e creatori di tecnologie pensate per le aziende
Prodotti
- Red Hat Enterprise Linux
- Red Hat OpenShift
- Red Hat Ansible Automation Platform
- Servizi cloud
- Scopri tutti i prodotti
Strumenti
- Formazione e certificazioni
- Il mio account
- Supporto clienti
- Risorse per sviluppatori
- Trova un partner
- Red Hat Ecosystem Catalog
- Calcola il valore delle soluzioni Red Hat
- Documentazione
Prova, acquista, vendi
Comunica
- Contatta l'ufficio vendite
- Contatta l'assistenza clienti
- Contatta un esperto della formazione
- Social media
Informazioni su Red Hat
Red Hat è leader mondiale nella fornitura di soluzioni open source per le aziende, tra cui Linux, Kubernetes, container e soluzioni cloud. Le nostre soluzioni open source, rese sicure per un uso aziendale, consentono di operare su più piattaforme e ambienti, dal datacenter centrale all'edge della rete.
Seleziona la tua lingua
Red Hat legal and privacy links
- Informazioni su Red Hat
- Opportunità di lavoro
- Eventi
- Sedi
- Contattaci
- Blog di Red Hat
- Diversità, equità e inclusione
- Cool Stuff Store
- Red Hat Summit