
This post illustrates a graphical notation for Kubernetes API objects: Kubernetes Deployment Language (KDL). Kubernetes API objects can be used to describe how a solution will be deployed in Kubernetes.
KDL is helpful for describing and documenting how applications will be deployed in Kubernetes and is especially useful when these applications are comprised of several components. I've created a simple graphical convention to describe these deployments, so that the diagram could be easily whiteboarded and captured in a document.
To better understand the objective, you can draw a parallel to UML, which had several graphical languages to describe different aspects of application architecture. The difference between UML and KDL is we don't have to do forward or reverse engineering (that is, we don't convert the diagrams in yaml files or vice versa). This way we can manage how much information we want to display in the diagrams. As a general rule of thumb we will only display architecturally relevant information.
Here you can find a git repo with the latest version of KDL and you can also download a visio stencil for the proposed notation.
Kubernetes API Objects
In general, Kubernetes API objects cover the following areas:
| Area | Color convention | Example |
|---|---|---|
| OpenShift Cluster | Red | The Kubernetes cluster(s) involved in the solution |
| Compute | Green | Deployment |
| Networking | Yellow | Service |
| Storage | Blue | Persistent Volume Claim. Persistent Volume |
Kubernetes cluster
The Kubernetes cluster is simply represented as a rectangle:

All the other API objects will live inside the cluster or at its edges. There should never be a need to call out individual nodes of a Kubernetes cluster.
You can represent components outside the cluster and show how they connect to components inside the cluster. This graphical convention does not cover components outside the cluster.
Compute
The compute objects are the most complex. In general, they are represented by a rectangle with badges around it to show additional information. Here is a template:
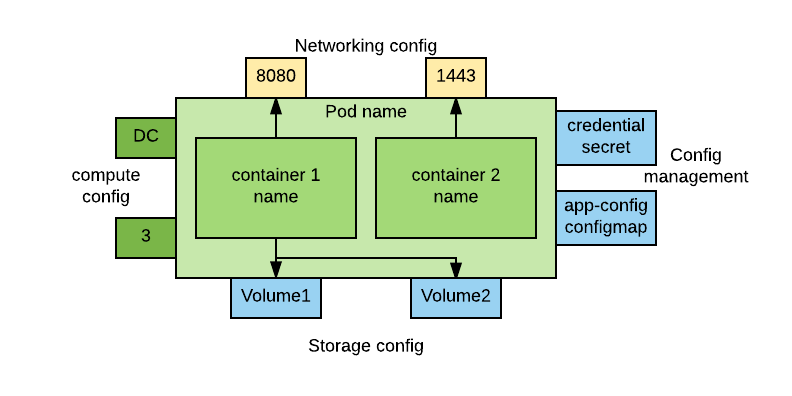
The central section of the image represents a pod. In it we can find one or more containers. Both pod and containers should have a name.
On the left side of the pod we have additional compute information. The top badge specifies the type of controller for this pod. Here are the types of controllers and their abbreviations:
| Type of controller | Abbreviation |
|---|---|
| Replication Controller | RC |
| Replica Set | RS |
| Deployment | D |
| DeploymentConfig (OpenShift only) | DC |
| DaemonSet | DS |
| StatefulSet | SS |
| Job | J |
| Cron Job | CJ |
On the bottom, we have the cardinality of the instances of that pod. This field assumes different meaning and format depending on the type of controller. Here is a reference table:
| Type Of Controller | Format |
|---|---|
| Replication Controller | A number or a range (for example, 3 or 2:5) |
| ReplicaSet | A number or a range (for example, 3 or 2:5) |
| Deployment | A number or a range (for example, 3 or 2:5) |
| DeploymentConfig (OpenShift only) | A number or a range (for example, 3 or 2:5) |
| DaemonSet | The node selector: storage-node=true |
| StatefulSet | A number: 3 |
| Job | A number representing the degree of parallelism: 3 |
| Cron Job | A number representing the degree of parallelism: 3 |
At the top of the pod we have the exposed ports. You can use the little badges to just show the port number or add the port name. Here is an example:
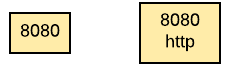
These badges are in yellow because they represent networking config. You can connect each port with the container that is actually exposing that port, if relevant. But in most cases this will not be necessary because most pods have just one container.
At the bottom of the pod we have the attached volumes. The name of the volume should be displayed in the rectangle. In most cases these will be persistent volumes. If the volume type is not a persistent volume it may be relevant to show it. Also, sometimes it may be important to show the mount point. Here are examples of acceptable notation:

The right side of the pod will have volumes that pertain to the configuration of the pod: secrets and configmaps. The name of the data volume should be indicated. It is important to distinguish between configmaps and secrets, so the type of volume should be indicated. If necessary, the mount point can also be shown. See these examples:

Networking
There are two types of networking objects: services and ingresses (routes in OpenShift).
Services
A service can be represented with an oval as in the following picture:
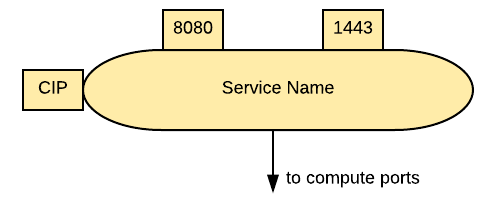
On the left side is a badge representing the type of service. The possible abbreviations are below:
| Type | Abbreviation |
|---|---|
| Cluster IP | CIP |
| Cluster IP, ClusterIP: None | HS a.k.a. Headless service |
| Node Port | NP |
| LoadBalancer | LB |
| External Name (OpenShift only) | EN |
| External IP | EIP |
The exposed ports are at the top of the service. The same convention applies here as for the compute ports.
The service should be connected to a compute object. This will implicitly define the service selector, so there is no need to have it indicated in the picture. If a service allows traffic from the outside of the cluster to internal pods, such as for LoadBalancer or Node Port or External IP, it should be depicted on the edge of the cluster.
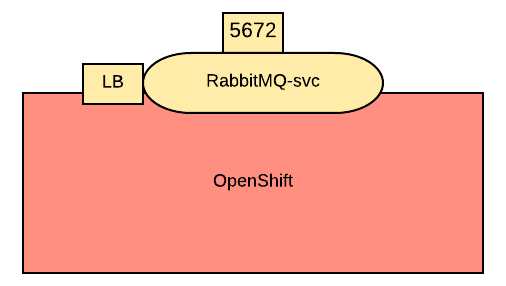
The same concept applies to services that regulate outbound traffic, such as External Name. However, in this case, they would probably appear at the bottom of the OpenShift cluster rectangle.
Ingresses
Ingresses can be indicated with a parallelogram as in this image:
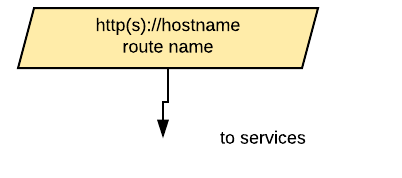
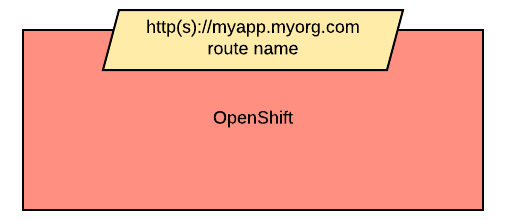
An ingress shows the ingress name and, optionally, the host exposed. An ingress will be connected to a service (the same rules apply to OpenShift routes). Ingresses are always shown at the edge of the OpenShift cluster.
Storage
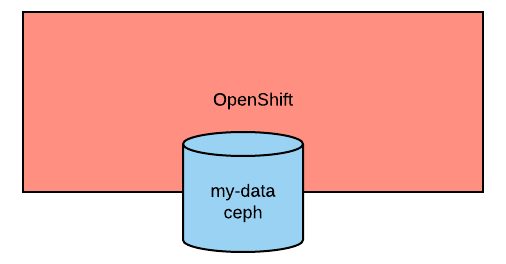
Storage is used to indicate persistent volumes. The color of storage is blue and its shape is a bucket, as seen in the following image:
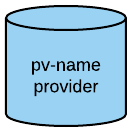
Storage should indicate the persistent volume name and the storage provider, for example, NFS, gluster, etc.
Persistent storage is always depicted at the edge of the cluster because it's a configuration pointing to an externally available storage.
Putting it all together
Here's an example how this notation can be used to describe the deployment of an application. Our application is a bank service application that uses a mariadb database as its datastore. Here is the deployment diagram:
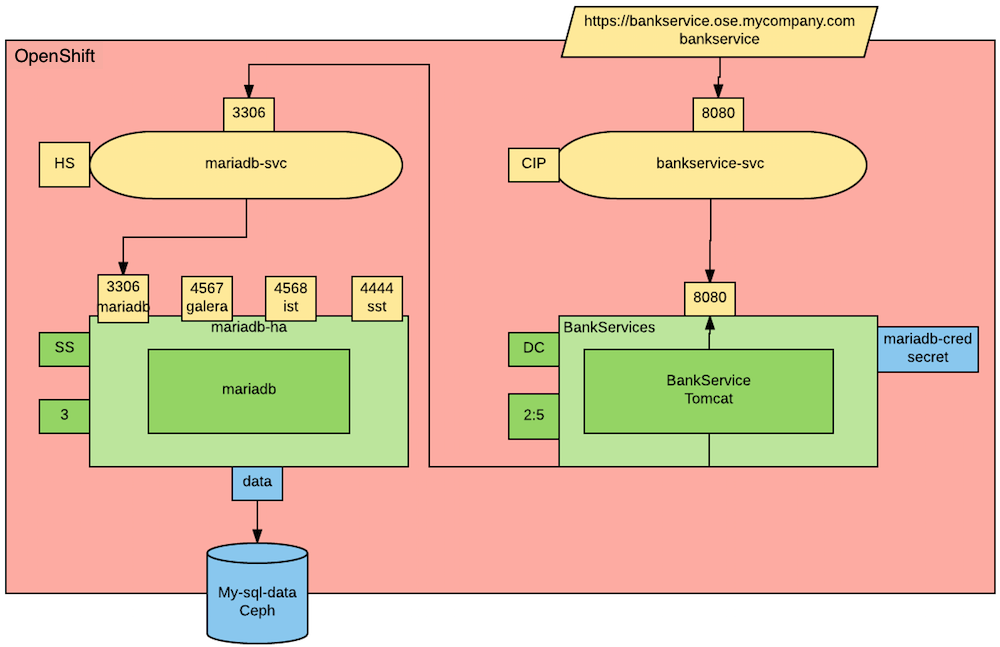
Notice that the mariadb pod uses StatefulSet and a persistent volume for its data. This pod is not exposed externally to the cluster, but its service is consumed by the BankService app.
The BankService app is a stateless pod controlled by a deployment config which has a secret with the credentials to access the database. It also has a service and a route so that it can accept inbound connections from outside the cluster.
Sull'autore

Raffaele is a full-stack enterprise architect with 20+ years of experience. Raffaele started his career in Italy as a Java Architect then gradually moved to Integration Architect and then Enterprise Architect. Later he moved to the United States to eventually become an OpenShift Architect for Red Hat consulting services, acquiring, in the process, knowledge of the infrastructure side of IT.
Currently Raffaele covers a consulting position of cross-portfolio application architect with a focus on OpenShift. Most of his career Raffaele worked with large financial institutions allowing him to acquire an understanding of enterprise processes and security and compliance requirements of large enterprise customers.
Raffaele has become part of the CNCF TAG Storage and contributed to the Cloud Native Disaster Recovery whitepaper.
Recently Raffaele has been focusing on how to improve the developer experience by implementing internal development platforms (IDP).
Altri risultati simili a questo
Ricerca per canale

Automazione
Novità sull'automazione IT di tecnologie, team e ambienti

Intelligenza artificiale
Aggiornamenti sulle piattaforme che consentono alle aziende di eseguire carichi di lavoro IA ovunque

Hybrid cloud open source
Scopri come affrontare il futuro in modo più agile grazie al cloud ibrido

Sicurezza
Le ultime novità sulle nostre soluzioni per ridurre i rischi nelle tecnologie e negli ambienti

Edge computing
Aggiornamenti sulle piattaforme che semplificano l'operatività edge

Infrastruttura
Le ultime novità sulla piattaforma Linux aziendale leader a livello mondiale

Applicazioni
Approfondimenti sulle nostre soluzioni alle sfide applicative più difficili

Serie originali
Raccontiamo le interessanti storie di leader e creatori di tecnologie pensate per le aziende
Prodotti
- Red Hat Enterprise Linux
- Red Hat OpenShift
- Red Hat Ansible Automation Platform
- Servizi cloud
- Scopri tutti i prodotti
Strumenti
- Formazione e certificazioni
- Il mio account
- Supporto clienti
- Risorse per sviluppatori
- Trova un partner
- Red Hat Ecosystem Catalog
- Calcola il valore delle soluzioni Red Hat
- Documentazione
Prova, acquista, vendi
Comunica
- Contatta l'ufficio vendite
- Contatta l'assistenza clienti
- Contatta un esperto della formazione
- Social media
Informazioni su Red Hat
Red Hat è leader mondiale nella fornitura di soluzioni open source per le aziende, tra cui Linux, Kubernetes, container e soluzioni cloud. Le nostre soluzioni open source, rese sicure per un uso aziendale, consentono di operare su più piattaforme e ambienti, dal datacenter centrale all'edge della rete.
Seleziona la tua lingua
Red Hat legal and privacy links
- Informazioni su Red Hat
- Opportunità di lavoro
- Eventi
- Sedi
- Contattaci
- Blog di Red Hat
- Diversità, equità e inclusione
- Cool Stuff Store
- Red Hat Summit