
As the world of technology continues to evolve at breakneck speed, the reliance on Red Hat OpenShift for container orchestration has become nothing short of ubiquitous. Organizations worldwide entrust their applications and services to the power of Kubernetes, lured by its scalability, resilience and agility. Yet, no one is immune to unexpected tragedy. In this era of digital transformation, one crucial question looms large: How well-prepared are you to weather the storm when disaster strikes your environment?
Imagine this scenario: Your container environment, the backbone of your mission-critical applications, suddenly grinds to a halt, posing significant threats to business continuity. An unforeseen event, whether a malicious attack or hardware failure, sends shockwaves through your system. In the face of chaos, every second counts. Your data, reputation and bottom line are all at stake.
This article takes a journey through the tumultuous waters of disaster recovery, exploring the key strategies and tools that Red Hat provides to help you navigate and recover from events that bring your Kubernetes infrastructure to its knees. Whether you're a seasoned Kubernetes pro or just dipping your toes into container orchestration, understanding how to prepare and recover from disasters is not an option—it's a necessity.
Master the disaster
Depending on the criticality of the situation and how downtime impacts your business, your disaster recovery strategy may have different needs and requirements. Having standalone backups of each of your environments is helpful, but what really matters is having an end-to-end framework that covers a whole multi-site relocation process.
Red Hat Advanced Cluster Management for Kubernetes extends the value of OpenShift by serving as a management console for your Kubernetes fleet. Besides managing lifecycle, monitoring usage and handling Day 2 configurations, Red Hat Advanced Cluster Management provides the ease of application mobility across the entire fleet while providing the flexibility needed for different use cases. I'll briefly explore all options:
- VolSync: VolSync is an open source project that is an add-on. It makes it easy to capture time-based copies of application states across your whole fleet. Data replication can be applied to different locations, storage types and vendors.
- Metro-DR: Offered by Red Hat Advanced Cluster Management and Red Hat OpenShift Data Foundation integrated stack, Metro-DR ensures continuity during the unavailability with no data loss. (RPO/Recovery Point Objective = 0)
- Regional-DR: Offered by Red Hat Advanced Cluster Management and OpenShift Data Foundation integrated stack, Regional-DR ensures continuity during the unavailability, accepting some data loss in a predictable amount. (RPO/Recovery Point Objective = Minimal)
- Third-party: Various third-party solutions can also take advantage of Red Hat Advanced Cluster Management's inventory and built-in health mechanisms of OpenShift clusters for a self-managed solution.
The solution proposed in this article uses Regional-DR, targeting minimal RPO and minimal RTO.
The anatomy of the solution
Consider an active-passive setup in this scenario, with Red Hat Advanced Cluster Management serving as the central hub for coordination. To begin, Red Hat Advanced Cluster Management oversees the primary cluster housing crucial applications, designated as "Primary." The secondary cluster, referred to as "Secondary," remains in a standby state with ample capacity to handle workloads in case of unavailability. These clusters are securely linked, benefiting from the Submariner add-ons for enhanced connectivity.
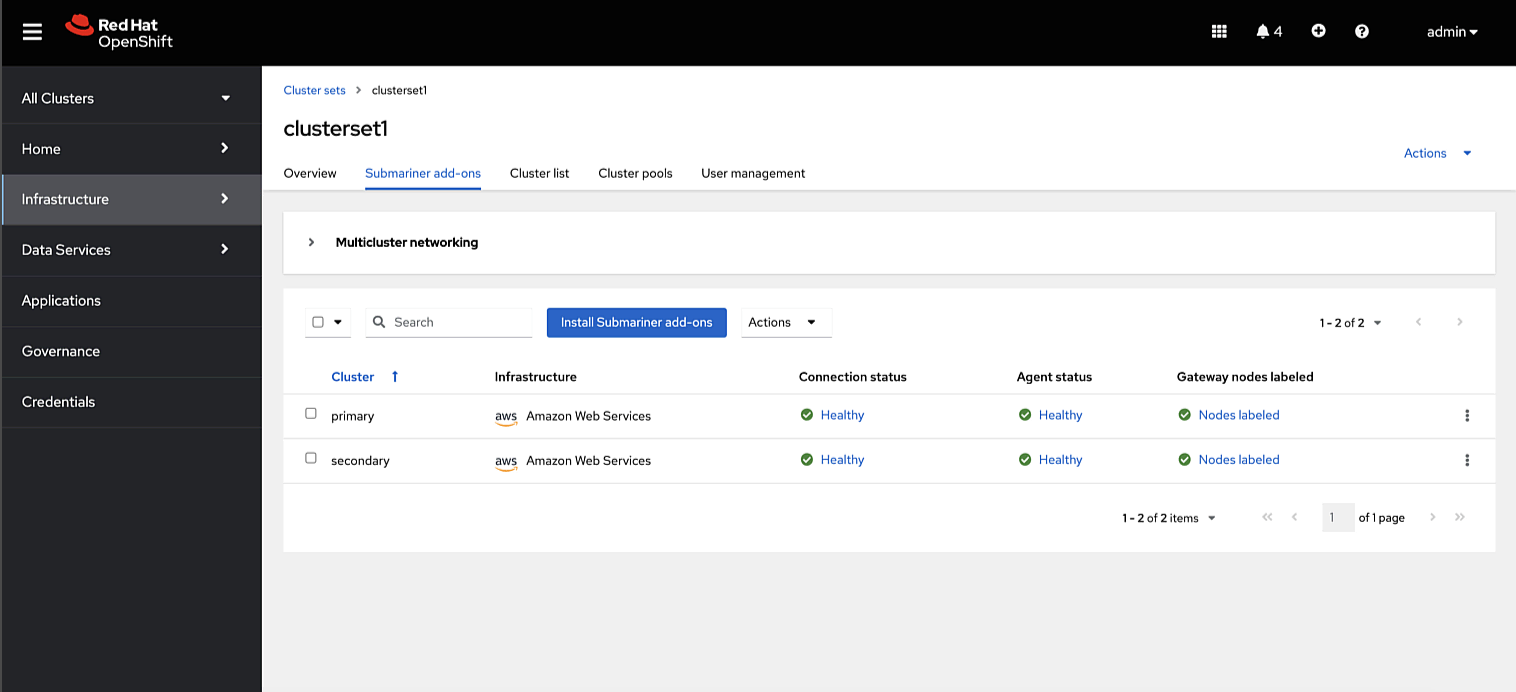
The failover process within Red Hat Advanced Cluster Management operates on a per-application basis. Therefore, you can configure distinct settings for each application. Consider a database application that must remain on-premises due to regulatory requirements, even during an outage, requiring constant data synchronization and replication. Less critical front-end applications may leverage on-demand public cloud instances with a more lenient recovery point objective (RPO). You can implement these configurations regardless of the specific demands.
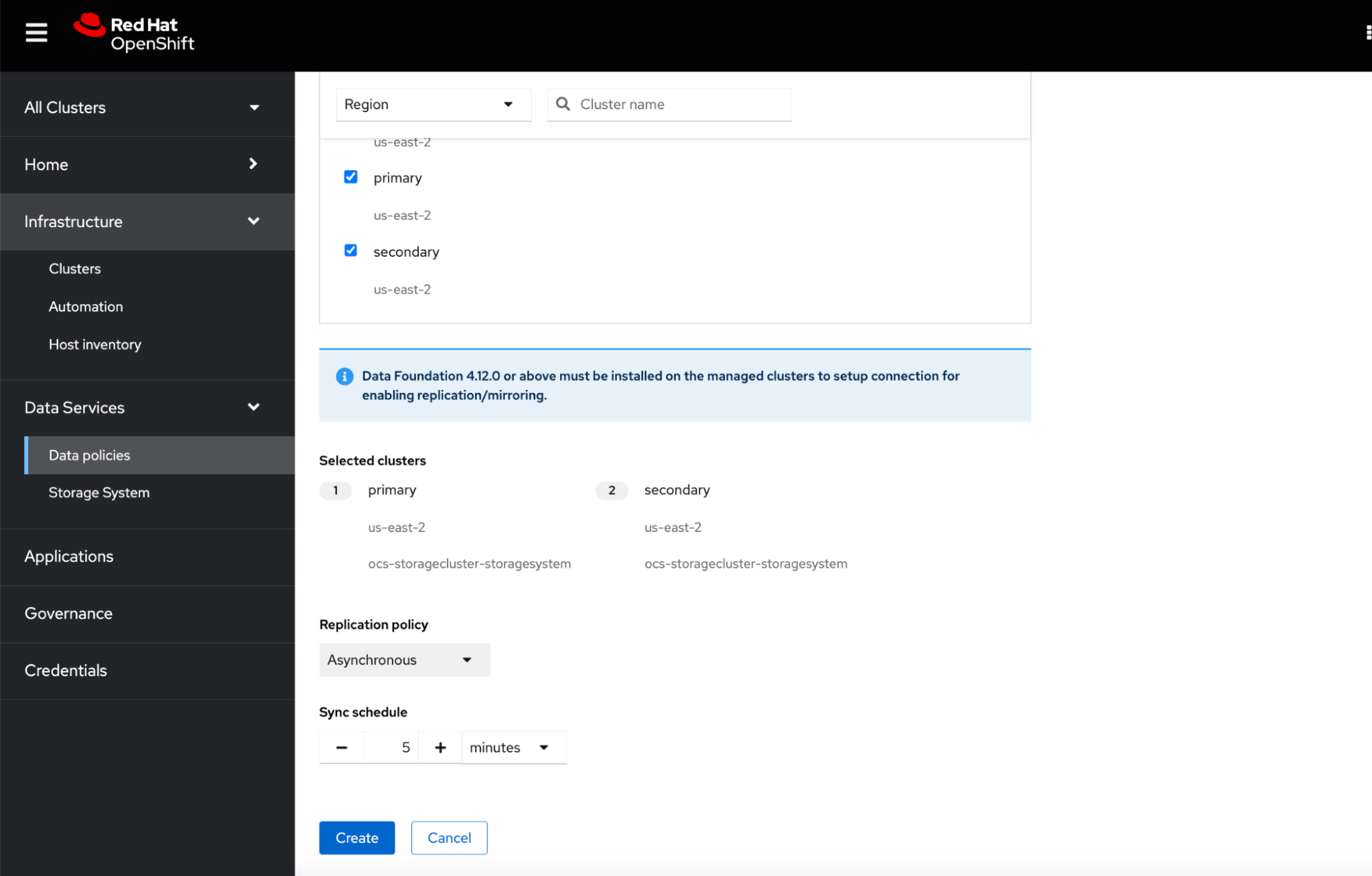
It's worth noting that Red Hat Advanced Cluster Management offers a user-friendly dashboard. You can conveniently view all components of your applications, such as Deployments, PersistentVolumes and more, along with their health status indicated by a green checkmark. You can modify these components, remove them, or even initiate a failover seamlessly in this interface.
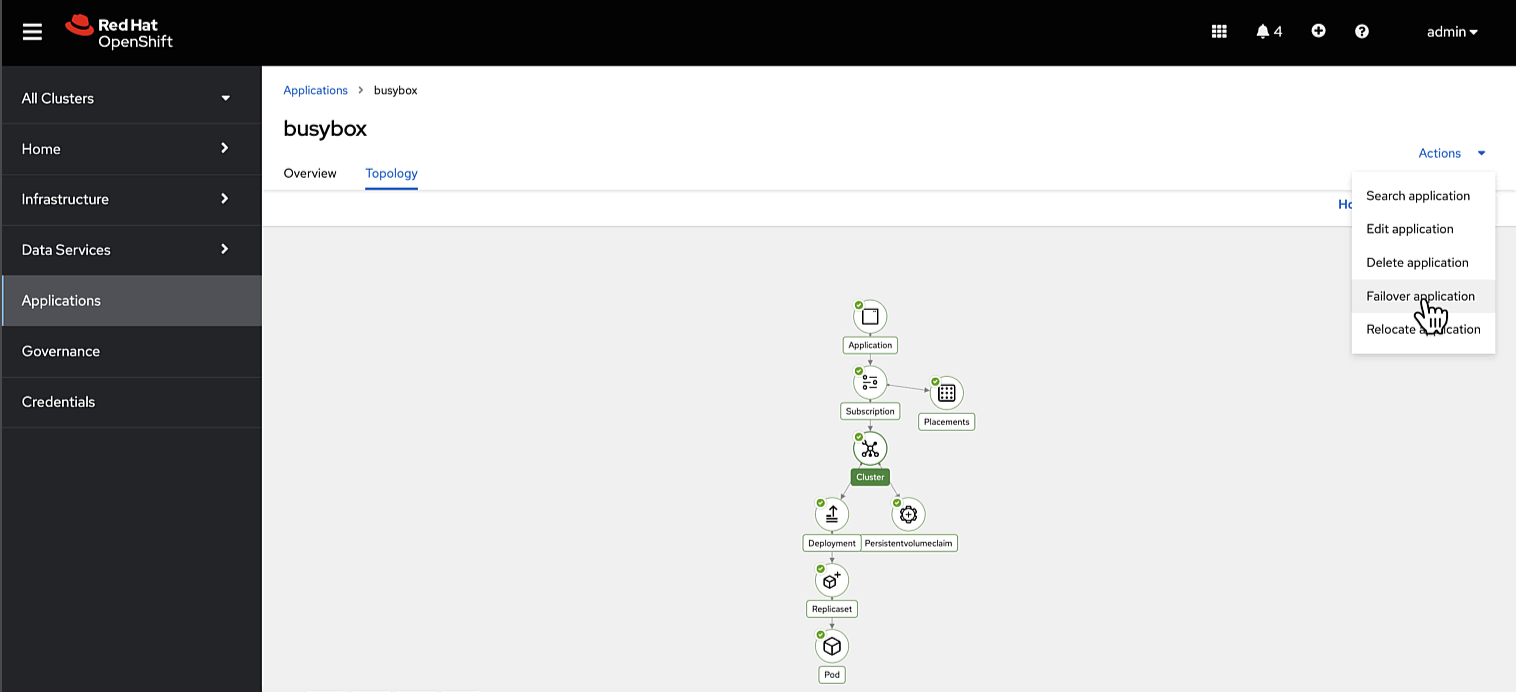
Undoubtedly, a failover operation is a highly sensitive procedure, necessitating the option for manual initiation. However, what if you intend to automate it in response to specific events or alerts?
That’s where Event-Driven Ansible comes into play.
Event-Driven Ansible
As part of Red Hat Ansible Automation Platform, Event-Driven Ansible can watch for and take action on events, even within a Kubernetes environment.
In the framework this article discusses, Event-Driven Ansible captures a Prometheus event. In this case, it verifies whether a specific CPU threshold is met. If it is met, Ansible Automation Platform turns to its automation controller, which is responsible for running an Ansible job template that triggers an Ansible Playbook.
This Ansible Playbook calls the Red Hat Advanced Cluster Management API and triggers the application failover from one OpenShift cluster to another.
The following diagram illustrates the process:
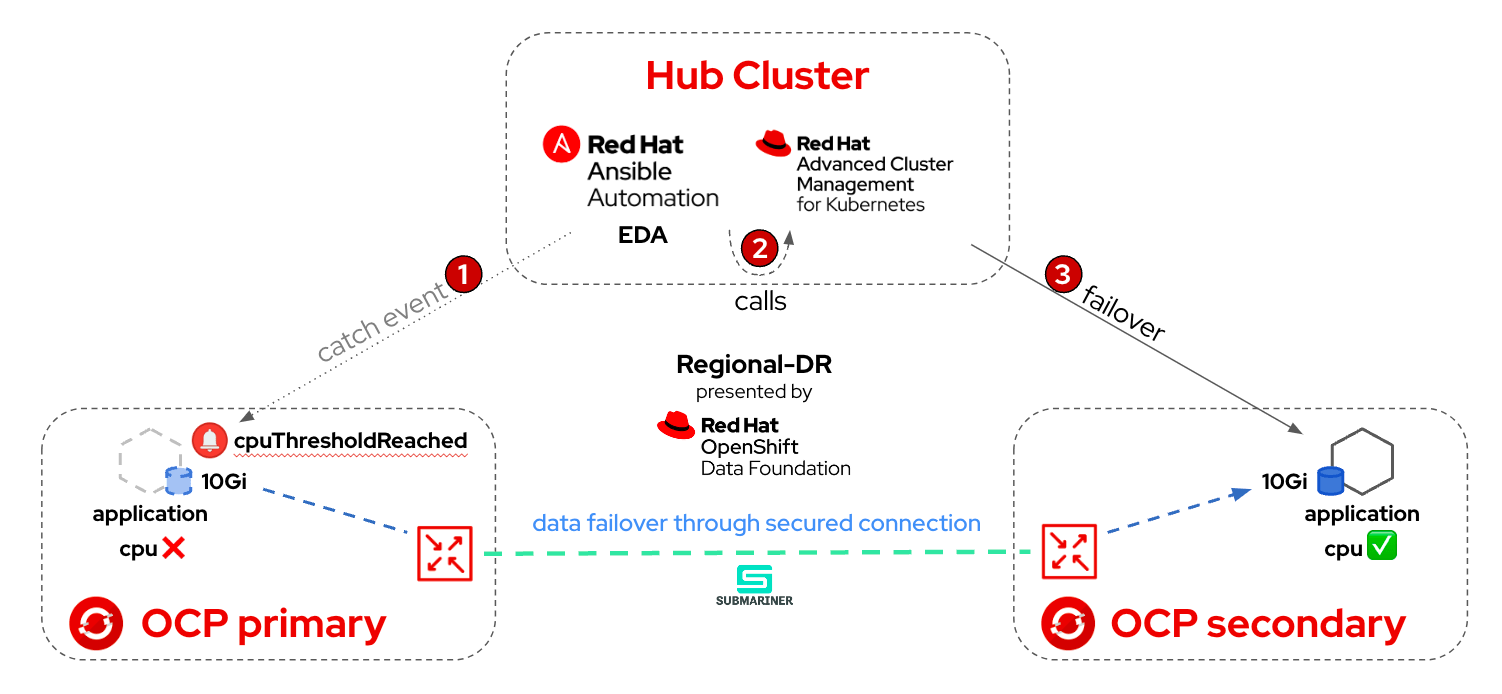
In this setup, there's no requirement to access the Red Hat Advanced Cluster Management or Ansible Automation Platform user interfaces for manual execution. This duo will autonomously address critical situations triggered by events of your choice, whether they result from or signify issues in your environments. The remarkable aspect is that you can integrate any in-house resource, be it a Prometheus alert, a Kafka message, or a webhook, to serve as the event Event-Driven Ansible monitors. Check out the list of the Ansible source plugins to explore the full range of possibilities.
To learn more, check out our two-part video series on business continuity with Red Hat Advanced Cluster Management and Ansible Automation Platform.
关于作者

Luiz Bernardo joined Red Hat is 2019 where he has supported and advocated for technologies like Linux containers and Kubernetes by providing meaningful engagements with the open source community and Red Hat customers. Born in Brazil and currently living in the Netherlands, Luiz is a sports lover and has a passion for dogs.








产品
工具
试用购买与出售
沟通
关于红帽
我们是世界领先的企业开源解决方案供应商,提供包括 Linux、云、容器和 Kubernetes。我们致力于提供经过安全强化的解决方案,从核心数据中心到网络边缘,让企业能够更轻松地跨平台和环境运营。