
What does successful network automation look like? What are the metrics that can measure the effectiveness of this practice and its business value?
Some will say we should look at time and cost savings, but we should not forget about driving consistency and a simpler operation to reduce risk. In this context, what are the use-cases that will get us there?

https://pixabay.com/illustrations/bot-cyborg-automation-helper-robot-48…
While there are generic use-cases, the real value of automation is truly uncovered when you are able to translate your existing processes into automated workflows that need no human intervention in order to be executed.
If your current processes are too complex, you can start by breaking them down into smaller chunks of work that will become the building blocks of your workflows. The simpler these units of work are, the more reliable/reusable they become. This blog post will walk through several use-cases for network automation, and show examples of data validation and functional testing to automate Methods of Procedure (MOP). We can then combine these building blocks into an overall workflow to gradually increase our time savings and reap more benefits from our automation as we add more building blocks.
“Do something today that gets you closer to your long term goal”
(https://www.ansiblejunky.com/blog/ansible-101-standards/)
Network Configuration management
Speaking of generic use-cases, network configuration management is probably at the top of the charts. In this case, what would be the benchmark to determine the time/cost savings our automated strategy is generating?
If you are only pushing configs to your network devices, time savings can be derived from the time it would have taken you to configure each device manually. You can argue that manually applying a configuration to a network device can take just a couple of minutes. And while this is true, time savings can still be considerable if you are making a change across a large number of devices.
However, applying a configuration change to a network device is the least time intensive task of a larger process network operators follow to actually make changes to networks. Some of the best practices you see in the field when making changes consider:
- Notifying users before changes start, and once they are completed, highlighting the results of the execution via email, a chat messaging application or any other preferred method.
- Documenting the changes, the steps followed and making sure all logs during execution are captured. This is typically submitted to a ticketing system users can search through.
- Creating network configuration backups before any changes are made.
- Taking a snapshot of the network to compare its state before and after the changes are performed. In other words, validating actual operational information such as: interface stats, routing tables, hardware resource utilization, or the state of connected devices to determine the health of the network.
- Testing the changes.
- If a new network protocol is set up, can you exchange information with it?
- If new ACLs are applied, can users still access the network?
- If a new network interface is brought up, can you actually run traffic through it?
- Having a Plan B in mind. If things don’t go as expected, you might want to bring the network to its previous state. Rollback changes, restore original configs or other strategies might apply here.

All these steps are why config changes typically take hours during a maintenance window and not just a couple of minutes. Running all these unattended as an automated workflow would be an absolute game changer, and that’s what network automation is really about for some.
Code examples
Network configuration management is only one of the workflows you can automate. What if you are turning up a couple of new devices/routers in a datacenter?
You are probably going to start with Zero Touch Provisioning (ZTP) to provide a software image to boot with and an initial config to these devices, to then make a provisioning callback to Ansible to configure services, validate that everything is in order and verify it is working properly.
Let’s look at a couple of examples on how you can approach data validation and functional testing to automate your Methods of Procedure.
Operational data validation
What would you validate when setting up a new router? Maybe that it has the correct Link Layer Discovery Protocol ( LLDP) neighbor on each interface to validate cabling is correct. Or if you are setting up routing protocols, you can check that all sessions are up and running, and that the device is learning routes/prefixes from its peers (or link information). Creating these types of checks is now simpler in Ansible with the new parsing module. Let’s see it in action.
Data collection and parsing
The first step is to collect data from your network devices and to produce a JSON document with this information that we can work with.
The next example shows how to loop over a series of popular CLI commands that provide information about the state of a network element.
- name: Parse list of commands
include_tasks: validate_commands.yml
loop:
- show version
- show interfaces
- show lldp neighbors
- show ip bgp summary
- show ip ospf neighbor
loop_control:
loop_var: commandhttps://github.com/nleiva/ansible-networking/blob/master/validate.yml
For each CLI command, a JSON representation is produced by taking advantage of one of the parsers available (pyATS in this case). This structured output is stored in a dictionary (`my_dict`) as part of the tasks executed inside the loop (`validate_commands.yml`).
- name: Fetch {{ command }} and parse it with pyATS
ansible.utils.cli_parse:
command: "{{ command }}"
parser:
name: ansible.netcommon.pyats
register: output
ignore_errors: true
- name: Create custom dictionary with command outputs
set_fact:
my_dict: "{{ my_dict | combine({command: output['parsed']}) }}"https://github.com/nleiva/ansible-networking/blob/master/validate_commands.yml
Data validation
With this information stored in a dictionary (`my_dict`), a list of checks can be run to help determine the health of a particular device or maybe the network.
For example, if OSPF is the internal routing protocol, we can check all OSPF sessions are operational, which would allow this network element to learn about other devices, and the topology of the network.
One way to do this is by iterating over the OSPF neighbors in the dictionary (`my_dict`). A warning message is sent to the user if any of the OSPF sessions are not operational. A `json_query`will help Ansible read the information of each individual OSPF neighbor. For more details on this, check out “5 tips to read and process JSON data in Ansible”.
- name: Create OSPF neighbors dictionary
set_fact:
ospf_neighbors: "{{ my_dict['show ip ospf neighbor'] | community.general.json_query('interfaces.*.neighbors') }}"Ansible will print out a WARNING message only if the state of an OSPF neighbor isn’t FULL, i.e. `info.value.state is not a match ("FULL.*")`. In this case, `info` is the dictionary item produced for each OSPF neighbor item inside the loop.
- name: Print out a WARNING if OSPF state is not FULL
debug:
msg: "WARNING: Neighbor {{ info.key }}, with address {{ info.value.address }} is in state {{ info.value.state[0:4] }}"
vars:
info: "{{ lookup('dict', item) }}"
when: info.value.state is not match("FULL.*")The outcome is a custom generated message with information about any OSPF neighbor that isn’t operational.
TASK [Print out a WARNING if OSPF state is not FULL] ************************************************************************************************************
ok: [localhost] => {
"msg": "WARNING: Neighbor 203.0.113.2, with address 192.0.2.2 is in state INIT"
}
Instead of a log message, this could be part of a PASS/FAIL checklist to determine the success of a maintenance window, for example.
Functional Testing
Some questions that might arise after deployment:
- If routing protocol sessions are up, does it mean the network device can forward traffic now? It depends.
- Can users still access this device or the network? It depends.
- If two links are added between a couple of devices, can any of these links be used? It depends.
There is probably no better way than testing to provide a more definitive answer to any of these questions. Can testing be automated as well? Absolutely!
Let’s take a look at testing link fault tolerance, for example. Imagine we have two new links between router1 and router2 as in the picture:
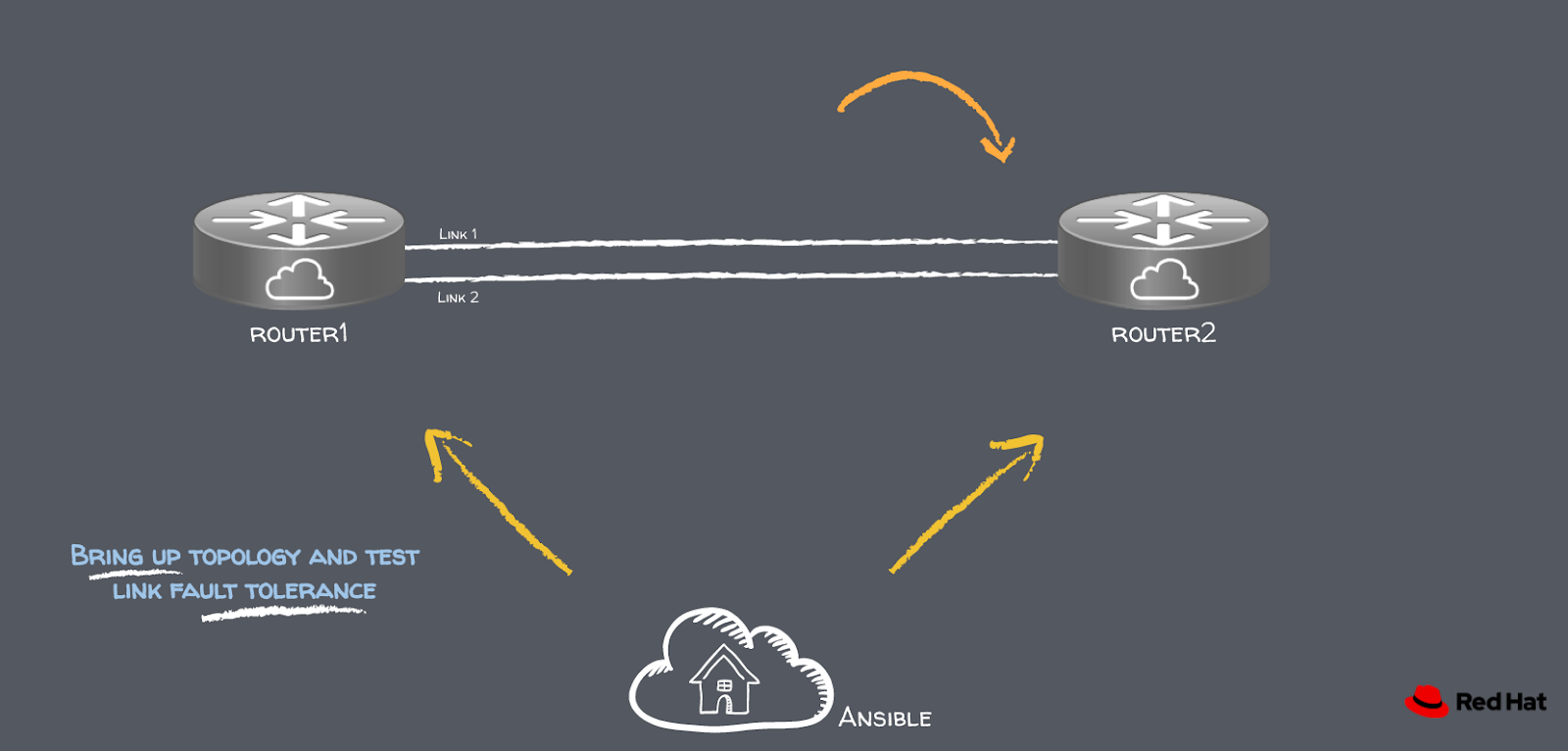
One common approach to test links is to simply ping across them. In this case though, we have two, and we would like to make sure each one works independently of one another to verify redundancy. Therefore, to confirm link fault tolerance a series of tests must be run.
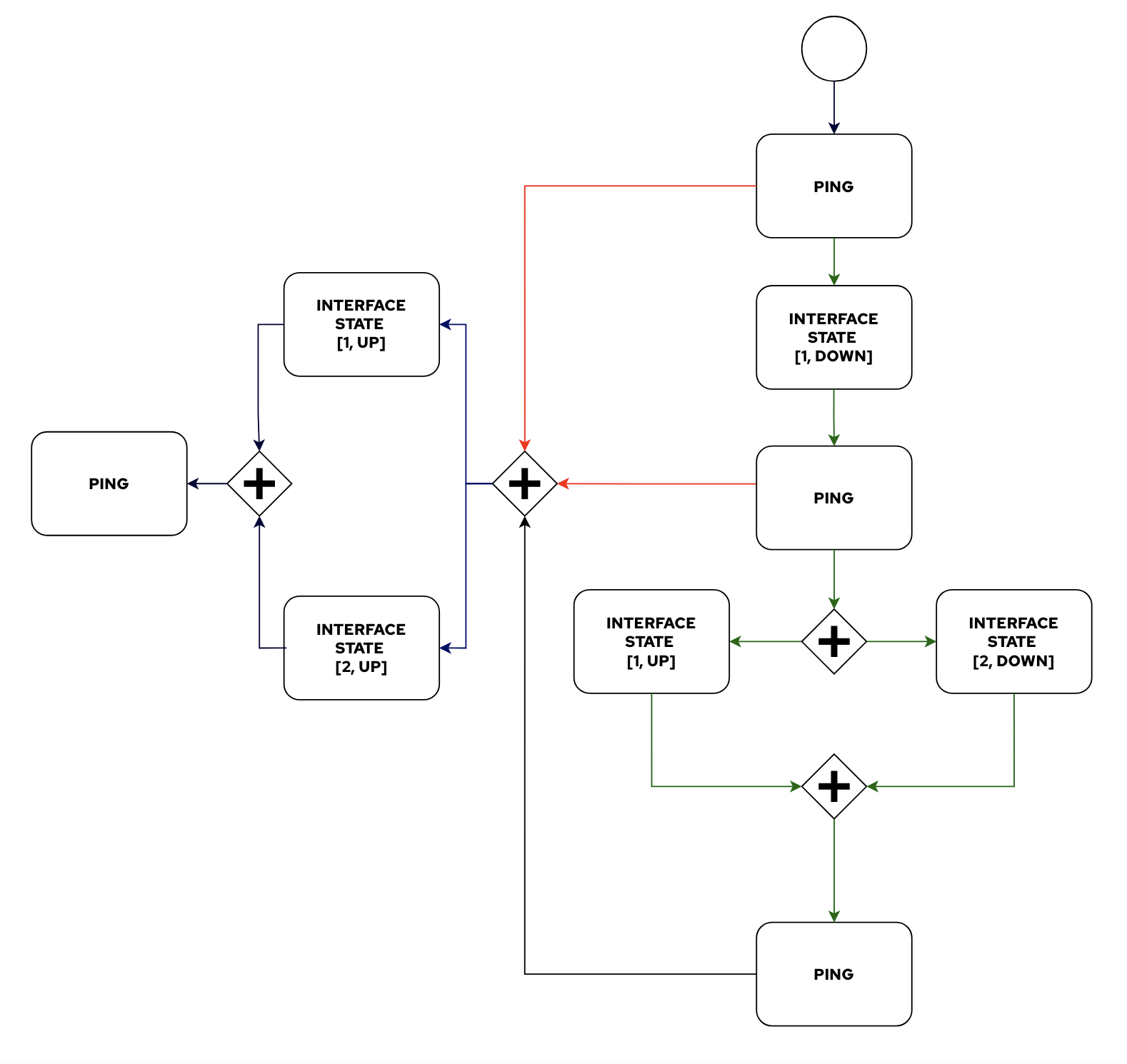
As different actions need to be executed, this process is more suited for a workflow rather than a single long playbook. A workflow can send ping requests across these links as we bring interfaces up and down.
Think of something like:
- Run a PING between routers with all links available.
- Bring down LINK 1, run a PING again. Bring LINK 1 back up.
- Bring down LINK 2, run a PING again. Bring LINK 2 back up.
- Run a PING again to double check everything is working properly.
- If any of the previous steps fails, try to recover both links and notify the user.
While this may sound like a lot of code to write, most of the actions are reusable units of work, such as bringing an interface up or down and executing a ping.
In a workflow this would look something similar to:
On the other hand, in terms of playbooks or tasks to run, we only need the following two:
PING
- name: Test reachability to {{ dest_ip }}
ios_ping:
dest: "{{ dest_ip }}"
count: 2INTERFACE STATE
- name: Modify {{ interface }}
ios_interfaces:
config:
- name: "{{ interface }}"
enabled: "{{ state }}"Hopefully this highlights how a couple of lines of YAML can go a long way to automate something we do manually today.
Conclusions
Network automation use-cases can come from within your organization, without the need to look at what others might be doing somewhere else.
A good way to translate network automation into business value is by taking existing processes and automating them to make them more consistent and faster to run. This is a step towards getting buy-in from your peers or management to adopt automation as a business-critical practice. If your current Methods of Procedure (MOP) are a series of steps to follow in a Word document, then you are in front of a great opportunity to take advantage of automation.
Automation is more than just one action or script, it is rather a collection of building blocks that need to be orchestrated together. In many cases, these building blocks are portions of your existing MOP’s: Take advantage of your knowledge of them to automate it!
Where to go next?
If you want to learn more about the Red Hat Ansible Automation Platform and network automation, you can check out these resources:
关于作者









产品
工具
试用购买与出售
沟通
关于红帽
我们是世界领先的企业开源解决方案供应商,提供包括 Linux、云、容器和 Kubernetes。我们致力于提供经过安全强化的解决方案,从核心数据中心到网络边缘,让企业能够更轻松地跨平台和环境运营。