
Public cloud usage is increasing daily, with many organizations adopting public clouds for their workloads, this trend often results in the creation of numerous resources that go unused or are forgotten to be deleted, leading to cost leakage and resource quota issues. This article will focus on identifying and pruning unused resources, ensuring they remain within the resource quota, and mitigating cost leakage.
We have implemented several pruning policies in the cloud governance automation framework. During resource monitoring, we found that most of the cost leakage comes from available volumes, unused NAT gateways, and unattached Public IPv4 addresses (Starting from February 2024, public IPv4 addresses will be chargeable whether they are used or not). Without automation, it is unreliable and impossible to control these unused resources effectively.
Getting started
Our team conducts extensive scale testing of OpenShift Clusters on the public clouds. During this, we observed that instances of terraform fail during resource deletion. Consequently, these resources persist in the cloud, incurring ongoing charges. Given that this process is ongoing and involves multiple team members, we developed a framework called Cloud Governance. This framework implements policies aimed at pruning unused resources in a fully automated way.
Policies
Currently, our primary focus is on AWS due to high user usage on this cloud platform but we also support other public clouds and plan to enhance it. We have implemented several policies using Cloud Governance to manage and prune resources effectively.
Policies offered by Cloud Governance include:
- Idle Instance
- Monitor the idle instances based on the instance metrics for the last 7 days.
- CPU Percent < 2%
- Network < 5KiB
- Monitor the idle instances based on the instance metrics for the last 7 days.
- Unattached volume
- Identify and remove the available EBS volumes.
- Unattached IP
- Identify the unattached public IPv4 addresses.
- Unused NatGateway
- Identify the unused NatGateway by monitoring the active connection count.
- Idle Database
- Identify the unused database by verifying the last number of connections.
- Zombie Snapshots
- Identify the snapshots, which are abandoned by the AMI.
- Zombie cluster resources
- Identify the non-live cluster resource and delete those resources by resolving dependency. We are scanning more than 20 cluster resources.
- Ebs, Snapshots, AMI, Load Balancer
- VPC, Subnets, Route tables, DHCP, Internet Gateway, NatGateway, Network Interface, ElasticIp, Network ACL, Security Group, VPC Endpoint
- S3
- IAM User, IAM Role
- Identify the non-live cluster resource and delete those resources by resolving dependency. We are scanning more than 20 cluster resources.
- S3 Inactive
- Identify the empty s3 buckets, causing the resource quota issues.
- Empty Roles
- Identify the empty roles that do not have any attached policies to them.
Each policy offers its benefits, aimed at preventing cost leakage and ensuring compliance with resource quotas.
For detailed information on each policy, please refer to our README.md documentation in the GitHub repository.

Action/ Not Action
There are two options to run policies in cloud governance: dry run yes/no.
“dry run=yes” means that cloud governance is collecting the policies' data without taking any actions. “dry run=no” means that cloud governance is collecting the policies' data and taking action based on the DAYS_TO_TAKE_ACTION environment variable, which is set to a default of 7 days. This configuration enables deletion and monitoring periods to be customized, ensuring resource management flexibility.
Skip Resource Deletion
There is an option to skip policy monitoring for dedicated resources by adding special tags such as 'Policy=Not_Delete' or 'Policy=skip' to the dedicated resource. By adding this tag, the cloud governance framework will skip the tagged resource. This provides more control over unused resources that may be needed in the long run.
Auto-Tagging
Tags serve as metadata for resources in the cloud and play a crucial role in managing Public Clouds. They facilitate various functionalities such as resource management, cost management, automation, and access control.
To emphasize the importance of tagging, we have implemented two policies aimed at automatically tagging resources created by users.
- tag_cluster_resources
- tag_non_cluster_resources.
In this process, we utilize cloud-trail to identify the IAM user associated with each resource. It's worth noting that as we've developed this framework for internal use, we've structured the IAM users to correspond with their email IDs. This approach enables us to easily identify users and their respective resources. Additionally, we leverage the LDAP directory to retrieve user details. By auto-tagging the resources and activating the tags in cost allocation, we can identify cost usage by different tags.
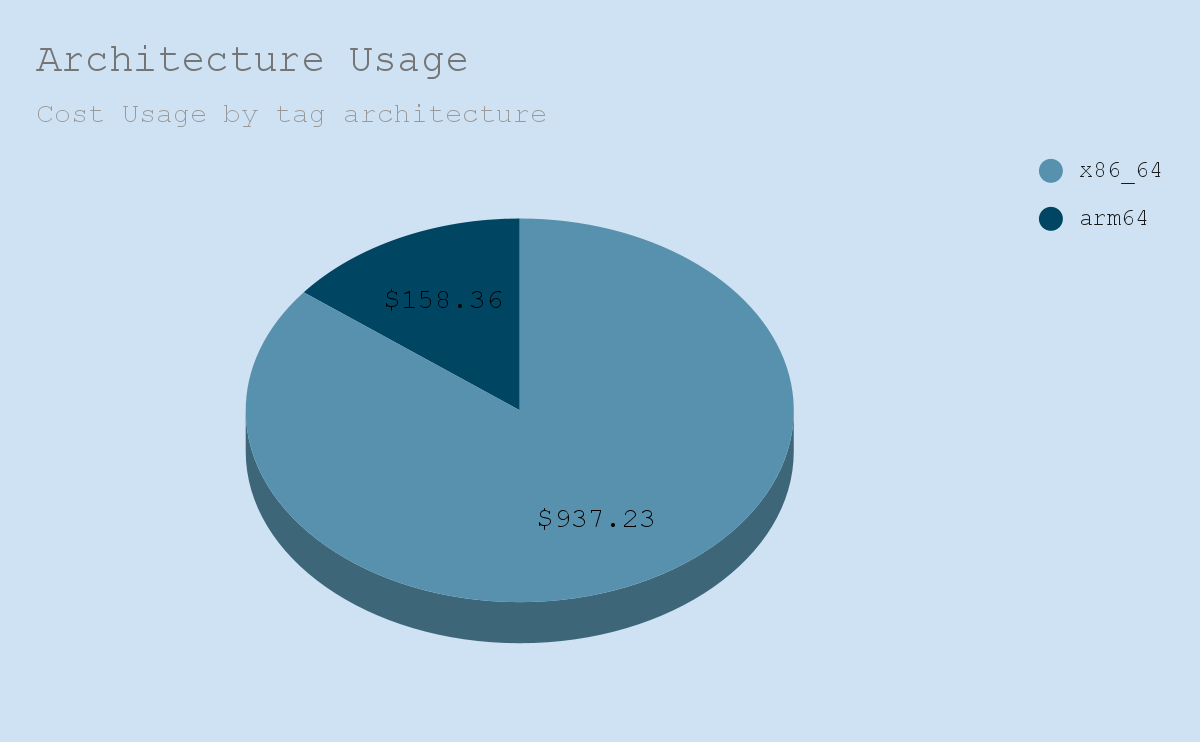
Alerting
We utilize a dynamic alerting mechanism, leveraging the Postfix emailing service, to notify users before deleting resources. This ensures that we monitor unused resources and prompt action, allowing users to either proceed with deletion or skip it by adding the 'Policy=skip' tag. Additionally, we leverage the auto-tagging feature to identify the user associated with each resource.
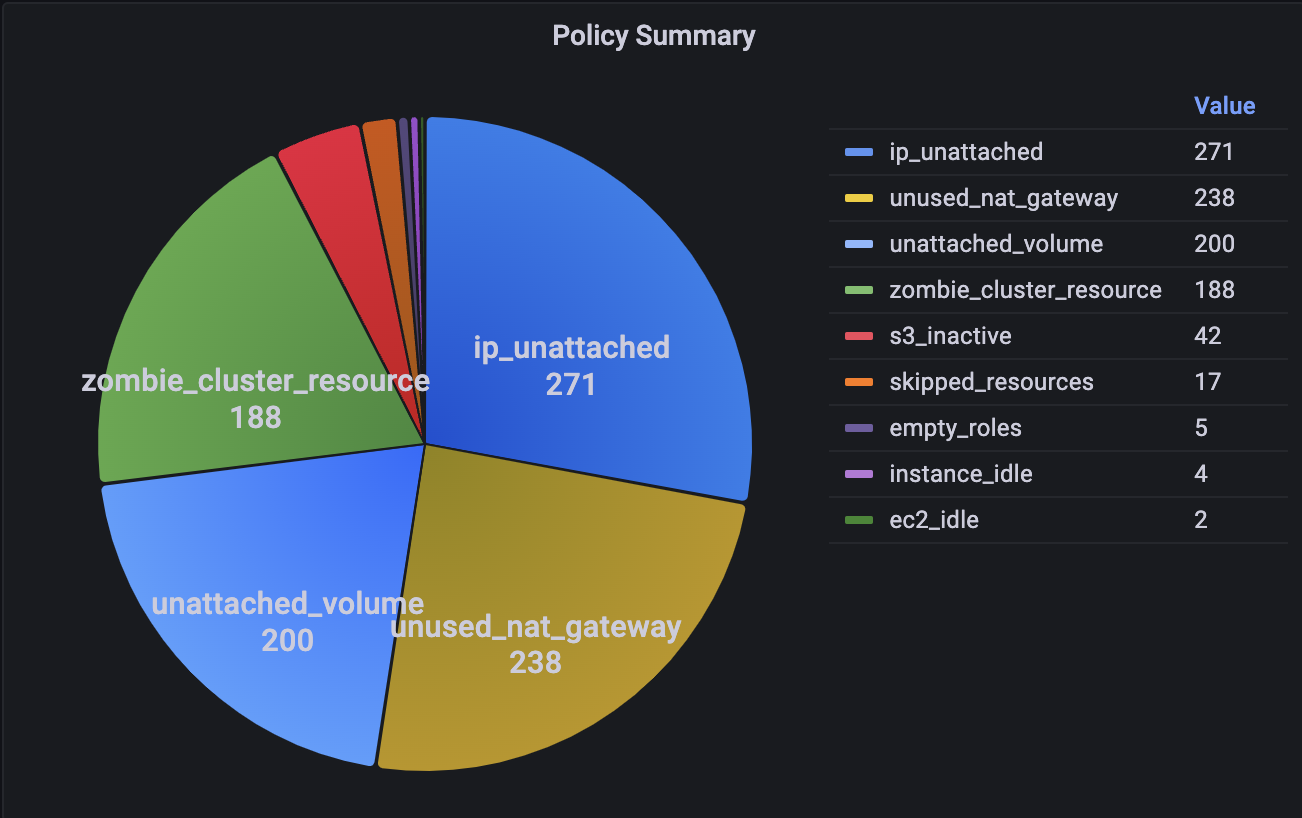
Grafana policies result reports
Estimated Yearly Savings

How to run Policy
$ podman run
-e policy="unattached_volume"
-e dry_run="yes"
-e AWS_ACCESS_KEY="$AWS_ACCESS_KEY"
-e AWS_SECRET_ACCESS_KEY="$AWS_SECRET_ACCESS_KEY"
-e AWS_DEFAULT_REGION="us-east-2"
quay.io/ebattat/cloud-governance:latest

Conclusion
By implementing this framework, we can continuously monitor resources and remove unused ones by pruning them. Each policy can run in two modes: dry_run=yes will not take any action, while dry_run=no will take action on the resource. Users can then review the policy results and take appropriate action.
References
关于作者


Almost 4 years at Red Hat in the Performance & Scale group. Brings strong technical skills and extensive knowledge in cloud technologies, particularly in building and managing performance benchmark frameworks across various cloud platforms (AWS, Azure, GCP, IBM Cloud).

I started at Red Hat as an intern in January 2022, to manage the public clouds. My main focus is on monitoring and reducing the cloud costs by running automation scripts. I bring expertise in Linux, AWS, Azure, OpenShift, Terraform and other open source technologies.
更多此类内容








产品
工具
试用购买与出售
沟通
关于红帽
我们是世界领先的企业开源解决方案供应商,提供包括 Linux、云、容器和 Kubernetes。我们致力于提供经过安全强化的解决方案,从核心数据中心到网络边缘,让企业能够更轻松地跨平台和环境运营。