
In August 2023, Red Hat released a new Red Hat Insights feature called Update Risks. This is the story of how the Insights Update Risks machine learning (ML) feature was developed and how you can approach your artificial intelligence/machine learning (AI/ML) project infused with lessons learned by the Insights team along the way.
Should you head on blindly to AI/ML?
Want a short answer? It's no. I can list a few main reasons why AI/ML projects fail while explaining how Red Hat developed Insights Update Risks for Red Hat OpenShift.
What type of AI/ML should you use? Generally speaking, there are two types of AI/ML:
- Predictive: Predict something that will happen with a certain precision (e.g., picture recognition, spike detection, etc.).
- Generative: Generate suggestions based on user input (e.g., ChatGPT, Bard and others).
I'll start with the complexity of a computational problem. Many AI/ML projects fail due to a "let's throw all the data we have in AI and get an answer" tendency. AI/ML tries, in a way, to simulate complex thinking and enrich it with the power of mass data processing. Would you ask a person to read through all available data in an attempt to find the answer to the well-known question, “What is the answer to the meaning of life, universe and everything?” Much like the famous 42 answer, you'll be presented with a result that begs more questions.
One problem with such thinking is the sheer computational problem of processing the dataset, but assuming you possess all the computational power you need, the "depth of the problem" presents another problem.
Hence, lesson learned and advice number 1: Narrow down the scope.
Ask yourself the major problems your customers face. Pick your fights. See what data you have available to support potential solutions to these problems. Some very basic statistics can help, like sorting the number of support requests filed for certain problem areas. You can, after some minimal investment, decompose these areas into smaller problems that are already solvable via AI/ML at scale.
In our case, from all the troubles installing, maintaining and running OpenShift clusters, updates seemed like a very promising field. The challenge of updating any Kubernetes clusters, especially moving between major versions of the platform, can be illustrated by companies choosing to do a parallel cloud migration (at the cost of additional hardware and infrastructure required) rather than updating the platform itself. Many factors influence successful updates, and you, as a user, expect your workloads to perform and behave in the same way as they did before the update. Such hurdles can be overcome by simply providing a checklist of potential roadblocks, such as existing or potential infrastructure problems, workload issues, or a combination of multiple factors.
Focusing on updates also allows the Insights team to define data areas to look at since there's a finite list of tasks to perform and success/failure metrics to be collected and processed.
Lesson number 2? Let's call it out and explain it later. Statistics is an exact science.
Machine learning models trade-off between model precision, accuracy, recall and computational time. So, how do we test a predictive model?
The best approach to scoring predictive models is to count real outcomes and predicted outcomes. For binary classification, you would have a 2-by-2 matrix (called a confusion or error matrix).
Imagine you are developing an at-home diagnostic test for a disease. You have a group of 1000 people, all of whom have taken a very precise blood test at the hospital and tried your new diagnostic test at home. Based on the hospital exam, you know 900 people are not sick (tested negative), while 100 are sick (tested positive).
For each study participant, you will know if they are actually sick and what the experimental test showed, so you have four different combinations:
Person(is_sick=True, is_predicted_sick=False) - 30 people (False Negative aka FN) Person(is_sick=True, is_predicted_sick=True) - 70 people (True Positive aka TP) Person(is_sick=False, is_predicted_sick=False) - 890 people (True Negative aka TN) Person(is_sick=False, is_predicted_sick=True) - 10 people (False Positive aka FP)
Remember that negative/positive does not refer to how happy/sad a certain outcome is (being sick is hardly a positive thing to brighten up your day), but you are using a medical (and coincidentally statistical) term when trying to diagnose an outlier.
You can present this result as a confusion matrix:

True negative and true positive are the correctly predicted outcomes, while false positive and false negative are mistakes the test made. In statistics, incorrectly diagnosing a patient as sick is called a Type I error, while telling a sick patient they are not ill is a Type II error. A goal of any study is to try to minimize both of these:

If you had a 100% accurate diagnostic tool, you would see this result:

However, real-world data and diagnostic tools are less than perfect, so you try to minimize both types of errors (false positives and false negatives). But how do you define which one is the most important?
Sensitivity and Specificity
One of the most common ways to evaluate a diagnostic test in medicine is using sensitivity and specificity metrics.
In many countries, at-home diagnostic tests are required to put clinical performance information in the instruction manual, so I'll use a COVID-19 test as an example, since you probably have one lying around at home somewhere.
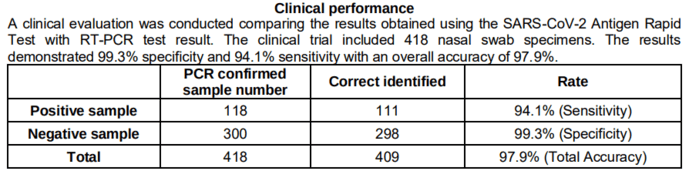
I'll convert this data into a confusion matrix:

Sensitivity is how many positives the test is able to pick up out of total positives; specificity is the same but for negatives.


If sensitivity and specificity work so well, why did you need to invent 20 more metrics?
This approach works well if the number of positive and negative cases in the dataset is similar and you care about predicting both positives and negatives, which is not true for the Update Risk Predictions feature.
Update Risk Predictions
Now look at some December 2022 external clusters update attempts:

As you see, there are 20 times more Red Hat OpenShift update successes than failures, which is good but makes our job a bit more difficult. We don’t care much about predicting which clusters will update correctly, but we really want to catch early symptoms if the cluster is in bad shape for an update.
Precision and Recall
We should focus on how both error types compare with correctly predicting whether a cluster update would fail. The right metrics for that are called precision and recall (recall is another name for sensitivity; I guess that's why they called it a confusion matrix).
This is how one of the models we tested performed:


Why are these numbers so much lower than those we've seen for diagnostic tests? Medical tests search for the presence of antibodies or other indicators that a disease is present, while we are trying to predict if a cluster update will fail in the future.
There are multiple reasons updates fail:
- Customer infrastructure issues, such as the network/DNS going down during the update.
- Conflicting customer-specific configurations we did not account for when developing and testing Red Hat OpenShift.
- Product bugs.
- Conflicting customer-specific configurations we detect and surface, but customers ignore (alerts, Insights recommendations, etc.).
- Health issues on the cluster, as seen through alerts and cluster operator conditions.
We can predict update failures caused only by the last two. When examining health data from clusters right before a failed update attempt, we found that at least 20% of cluster updates failed without having a single alert in Red Hat OpenShift namespaces or a sad cluster operator before starting the update.
There is also no guarantee that a cluster firing a specific alert would fail. We also found that each alert and failed operator condition we examined were present in both failed and succeeded updates, some were just more prevalent in failed than in succeeded. We saw clusters with Kubernetes API issues right before the update miraculously updating (possibly admins detected the problem and fixed it during the update, so it ultimately succeeded), as well as supposedly healthy clusters failing to update for unknown reasons.
As you can see, finding an ML-driven solution that is explainable and can detect anomalies accurately is no easy task. We've so far spoken only about the data science process itself, but what about the backing infrastructure?
Who is powering our AI/ML backing infrastructure?
Machine learning is not easy. As demonstrated earlier, figuring the model itself out is quite a tedious task. On top of that, the whole process requires integrating multiple tools to cover the entire path from development to delivery and execution of models in production.
Building up backing infrastructure for data analytics, processing, supervised training, inference and other activities takes a lot of time on its own, and for organizations just starting with AI/ML, a steep learning curve awaits. Having a skilled science infrastructure team can cut time to market.
Insights has partnered with the Red Hat OpenShift AI team to bring this feature to the market. While the OpenShift team took care of tool configuration, scaling and performance, the Insights team, in collaboration with IBM Research, focused on data science and model training.
You can learn more about the toolset we utilized in this article.
Lesson number 3: There's no need to reinvent the wheel.
Based on the development of Insights AI/ML projects, OpenShift AI (formerly known as Red Hat OpenShift Data Science) provides a tested and hardened collection of tools and integrations, allowing you to trim down the time to delivery of your AI/ML projects. Using OpenShift AI enables you to leave the necessary infrastructure operations to someone with experience, while on Day 0 you can jump into a Jupyter notebook and start prototyping.
Wrap up
Using AI/ML opens new potential for our Insights features—if we ask the right questions! Following the pattern of narrowing down the scope and asking the right questions with the correct data, we can deliver functionality that differentiates our platform and combines our own experience with great machine learning techniques. As a result, we provide you with a product feature that we hope results in a better experience with Red Hat OpenShift.
We welcome any feedback that can help improve our products. Please send your questions and suggestions to insights@redhat.com or directly using the feedback button on console.redhat.com.
关于作者

Red Hat software engineer focused on AI/ML within the Observability team for Red Hat OpenShift, using remote health data to improve the product and user experience.

Red Hatter since 2010, Dosek's professional career started with virtualization technologies and transformed via variety of roles at Red Hat through to hybrid cloud. His focus is at improving product experience with assistance of Red Hat Insights.








产品
工具
试用购买与出售
沟通
关于红帽
我们是世界领先的企业开源解决方案供应商,提供包括 Linux、云、容器和 Kubernetes。我们致力于提供经过安全强化的解决方案,从核心数据中心到网络边缘,让企业能够更轻松地跨平台和环境运营。