
 Automatic speech recognition with NVIDIA Riva ASR
Automatic speech recognition with NVIDIA Riva ASR
This blog post will help you build a cloud-native artificial intelligence (AI) platform made up of a Red Hat OpenShift cluster with NVIDIA vGPU on VMware vSphere at Equinix Metal. You will get a working setup for testing and development even if you don’t have suitable hardware in your lab. It focuses on an automated, reproducible way of deploying Red Hat OpenShift clusters with NVIDIA Virtual GPUs (vGPUs) using Ansible, but also includes links to the manual procedures this automation is based on.
Why?
My team at Red Hat was looking for a way to run NVIDIA AI Enterprise workloads on Red Hat OpenShift for development and verification. NVIDIA AI Enterprise offers highly optimized tools for building and running artificial intelligence (AI) and machine learning (ML) applications to help you get a better return on investment on your GPUs, while OpenShift provides an enterprise-grade platform that enables modern application architectures and full MLOps environments.
Our goal is to make sure that NVIDIA AI Enterprise can be deployed seamlessly on any supported OpenShift cluster. This means, first and foremost, bare metal, but let’s leave that for another blog post. As it turns out, many Red Hat customers have legacy infrastructure, and want to modernize their applications without moving away from that infrastructure (not at the first stage, at least). A popular vendor in brownfield deployments of OpenShift is VMware. Red Hat has always worked hard to make OpenShift Container Platform run seamlessly on VMware vSphere, with full integration of compute, network and storage. Support of hardware accelerators such as GPU is an extra level of integration. In particular, the integration with NVIDIA virtual GPU (vGPU) allows leveraging the power of GPUs for containerized AI/ML applications in OpenShift environments running on VMware vSphere.
The Ingredients
Here are the steps and components that make up the solution:
-
A bare metal server with a supported NVIDIA GPU model
-
A VMware vSphere cluster (ESXi and vCenter), version 7.0 Update 2 or later
-
The NVIDIA vGPU host driver for VMware — installed and configured
-
Virtual machines with an attached vGPU device, set up as OpenShift worker nodes
-
A Red Hat OpenShift cluster
-
An instance of the NVIDIA GPU operator with the vGPU guest driver
Equinix Metal
We first need a bare metal machine with a supported NVIDIA GPU model.
To try our hand at vGPU, we are looking at publicly available, on-demand servers. Luckily, Equinix Metal offers a machine type that has an NVIDIA V100 GPU. And not just one GPU, but two of them! The server specification at the time of writing:
| Parameter | Value |
|---|---|
| Plan Slug | g2.large.x86 |
| CPU | 2 x Intel Xeon Gold 6126 |
| Cores | 24 cores @ 2.60 GHz |
| Boot | 1 x 150 GB SSD |
| Storage | 2 x 480 GB SSD |
| Memory | 192 GB RAM |
| GPU | 2 x NVIDIA V100 |
| Network | 2 x 10 Gbps |
Unfortunately though, it’s available only in the Dallas metro (DA). You may also need to contact Equinix to make this type available in your Equinix project.
Make a note of the following variables that will be used for automated provisioning:
-
equinix_metal_api_key— can be managed under Personal API Keys in the Personal Setting of your Equinix user at https://console.equinix.com/. -
equinix_metal_project_id— the ID of an existing Equinix Metal project.
In addition, decide on the following:
-
equinix_metal_hostname_prefix— a prefix to help you to tell apart the machines that belong to different VMware clusters or different users in a shared Equinix project. -
equinix_metal_facility— must be in the DA metro, as already mentioned.
Write these variables to a YAML file, e.g. vgpu-on-vmware.yml.
VMware vSphere
Now that we have a suitable server, we need to provision it with VMware ESXi, and after that install VMware vCenter. The GitHub repository at https://github.com/equinix/terraform-metal-vsphere by Equinix contains a Terraform script that automates the entire process, producing a ready-to-use VMware vSphere cluster at the end. The Multi-node vSphere with vSan support guide describes in detail what the script does, and how to run it.
The problem is that NVIDIA vGPU requires ESXi 7.0 Update 2 or later, while Equinix doesn’t offer this version for the server type we’re interested in. ESXi 7.0 is also very tricky to install on Equinix using iPXE (believe me, I tried).
The solution is to provision ESXi 6.5 and then upgrade to a newer version. There’s even a GitHub repository for automating that. Now we just need to combine the two flows, so that ESXi is upgraded to the required version right before a vCenter installation starts. This is exactly what the fork at https://github.com/empovit/equinix-metal-vsphere/tree/stable ("stable" branch) does, and it’s the one we'll be using in our solution.
Compared to the original Terraform script, it has two additional parameters, as explained in Upgrading ESXi version:
-
update_esxi— whether ESXi should be updated, is already set totruein our case -
esxi_update_filename— specifies the desired ESXi patch name. Available patches for each version can be found on the VMware ESXi Patch Tracker page.
For security reasons, the ESXi servers of a vSphere cluster won’t be accessible on the public Internet, and will be hidden behind a bastion host. The bastion host plays another important role — as the vCenter Server Installer for Linux requires either SUSE or Ubuntu, running it in an unattended mode on the bastion (Ubuntu) will let you use any operating system to run the automation scripts (i.e. as the Ansible control node).
For this stage of deployment, you will need access to a licensed or evaluation version of VMware vSphere. Upload a vCenter Server Installer ISO file to S3-compatible object storage, along with other artifacts as described in Upload files to your Object Store. Specify the location of the S3 bucket, and filename of the vCenter ISO in the YAML configuration file:
s3_url(e.g. https://s3.amazonaws.com, or any S3-compatible object storage server)s3_buckets3_access_keys3_secret_keyvcenter_iso_name(e.g. VMware-VCSA-all-7.0.3-20150588.iso)
NVIDIA vGPU
Next, we’ll need to install and configure the vGPU software.
The NVIDIA vGPU host driver comes packaged as a vSphere Installation Bundle (VIB). You need a license to access vGPU host driver files through the NVIDIA licensing portal. Download the Complete vGPU package for vSphere 7.0 and extract the host driver ZIP archive /Host_Drivers/NVD-VGPU_<version>.zip. Save the extracted file to the S3 bucket, and add the corresponding value to the YAML configuration:
vib_filename(e.g. NVD-AIE_510.47.03-1OEM.702.0.0.17630552_19298122.zip)
Installation of the vGPU host driver involves moving each ESXi host to the maintenance mode, which in turn requires shutting down all VMs running on the host, and reverting these steps after the installation has finished, as described in the Virtual GPU Software User Guide by NVIDIA.
The procedure also requires rebooting the ESXi hosts. Therefore, we are going to enable the automatic start of the vCenter Server Appliance (VCSA) virtual machines deployed as part of vSphere, so that the vCenter API stays available for the later steps of the automation.
Deployment of the driver VIB is just the first step towards a working vGPU. We also need to change the default graphics type. Now, configuring the host graphics can be challenging. Each of the mentioned steps uses a CLI tool, an API call, a dedicated Ansible module, a Python library, or a combination of methods — depending on what’s available or easier to understand. Sometimes it's the lack of documentation that made me choose one method over the other. Configuring the host graphics is a good example, as I could find only one way of doing it programmatically — using the pyVmomi library, although the same operation in the vCenter GUI is very straightforward.
Red Hat OpenShift
For the manual steps for deploying OpenShift with vGPU on VMware vSphere, check out OpenShift Container Platform on VMware vSphere with NVIDIA vGPUs.
To deploy a Red Hat OpenShift cluster automatically, we will be using the Assisted Installer for OpenShift. Here are the steps for a Single-Node OpenShift (SNO):
-
Create a cluster definition at https://console.redhat.com/openshift/assisted-installer/clusters/.
-
Generate an ISO image and download it into the datastore of the VMware cluster.
-
Create a VM that boots into the ISO image and configure it for vGPU.
-
Add a vGPU profile to the VM.
-
Start cluster installation and wait for it to finish.
This automation uses an Ansible collection based on the excellent (although not officially supported) aicli tool — a convenient wrapper around the Assisted Installer’s Python binding.
The settings that control OpenShift installation are:
-
pull_secret_path— path to a pull secret file, downloaded from https://console.redhat.com/openshift/install/pull-secret, e.g. ~/pull-secret.txt -
ocm_offline_token— an OpenShift offline token used to authenticate against the Assisted Installer API, obtained at https://console.redhat.com/openshift/token. -
openshift_cluster_name— a name for your OpenShift cluster, e.g. vgpu-sno-on-equinix -
openshift_base_domain— base DNS domain, e.g. redhat.com -
openshift_version— a version supported by the Assisted Installer, e.g. "4.10"
Optionally, your /etc/hosts file can be automatically updated with DNS entries for your new cluster. An alternative would be to use an external DNS service:
update_etc_hosts: true
Size of the vGPU slice allocated to the SNO node running in a VM is defined by
vgpu_profile: "grid_v100dx-32c"
By default, the vCenter and OpenShift will have public IP addresses. If you want the vCenter appliance and OpenShift node(s) deployed to private networks without public access on the Internet, run the installation playbook with
use_private_networks: true
Keep in mind that in this case you'll have to connect to the cluster via the bastion server, or open a VPN connection. Luckily, a L2TP/IPsec VPN will be already set up for you. Use the information printed by the automation script to configure a L2TP/IPsec VPN client for your platform.
NVIDIA GPU Operator
The last piece is the NVIDIA GPU Operator, which makes the underlying GPUs of a compute node available to containerized workloads. In our case, it’s the slice of the NVIDIA vGPU that will be exposed to OpenShift pods.
A prerequisite for running the GPU operator is the Node Feature Discovery (NFD) Operator, which detects hardware features and system configuration at a node level. After installing the NFD Operator and creating a NodeFeatureDiscovery instance, we can move on to installing the NVIDIA GPU Operator and creating an instance of ClusterPolicy.
A vGPU-enabled ClusterPolicy requires a license and access to NGC, therefore the following settings are mandatory:
-
ngc_api_key— can be obtained at https://ngc.nvidia.com/setup/api-key -
ngc_email— your NGC registration email address -
nls_client_token— an NVIDIA License System token that gives access to NVIDIA vGPU packages
Putting It All Together
You can find Ansible playbooks that are referred to in the post at https://github.com/empovit/openshift-on-vmware-with-vgpu under the Apache-2.0 license. Ansible 2.9 or later is required.
-
Clone the repository into a directory on your local machine and change to it.
-
Carefully read the documentation in the repository.
-
Select a temp directory that will store the Terraform state, logs, credentials and SSH keys for connecting to vCenter and the OpenShift cluster, and a kubeconfig file for the cluster. (
local_temp_dir, e.g.~/sno-vgpu). -
Copy the location of the YAML configuration file you’ve been populating.
Now run:
ansible-galaxy install -r requirements.yml
ansible-playbook sno.yml -e "@/path/to/vgpu-on-vmware.yml” -e local_temp_dir=~/sno-vgpu
The playbook starts on the control node (localhost) with the provisioning of Equinix servers, one of which is then dynamically added to the Ansible inventory. Therefore there’s no need in an inventory file.
Follow messages on the screen for important connection information, such as the location of the cluster’s kubeconfig file. In case of private VM networks, some of the files will be saved to the bastion and not your local machine.
Tearing a setup down is as simple as running
ansible-playbook destroy.yml -e "@/path/to/vgpu-on-vmware.yml” -e local_temp_dir=~/sno-vgpu
A few points to keep in mind:
-
Currently, the playbooks can deploy only Single-Node OpenShift (SNO).
-
The building blocks, e.g. the VMware vSphere deployment, have a lot more knobs than the Ansible playbooks expose. We’ve taken a slightly opinionated approach to simplify stuff — using reasonable defaults and hiding details that aren’t relevant for our use case. For the full list of configuration options, see the playbook, inventory, and role variables in the repository.
-
We are constantly working to remove limitations and improve the code.
NVIDIA Riva Speech Services
Now we can deploy and run NVIDIA AI Enterprise applications. The GPU-accelerated NVIDIA Riva SDK for building speech AI applications is a good test for the capabilities of our OpenShift setup. For instance, Riva-based automatic speech recognition (ASR) can be used to transcribe conversations with customers in a call center, or automatically generate subtitles in a video conference call.
The NVIDIA Riva server comes as a Helm chart that has to be downloaded from NGC. Keep in mind though that the Helm chart can’t run "as is” on our OpenShift setup. This is due to the stringent OpenShift security and the need for an additional piece of infrastructure. There are multiple ways to overcome the limitations, but for the sake of simplicity we’ll apply the following customizations without modifying either the OpenShift cluster or the Helm chart:
-
Force
modelDeployVolumeandartifactDeployVolumeto useemptyDirinstead of a host path. -
Use
NodePortinstead ofLoadBalanceras the service type.
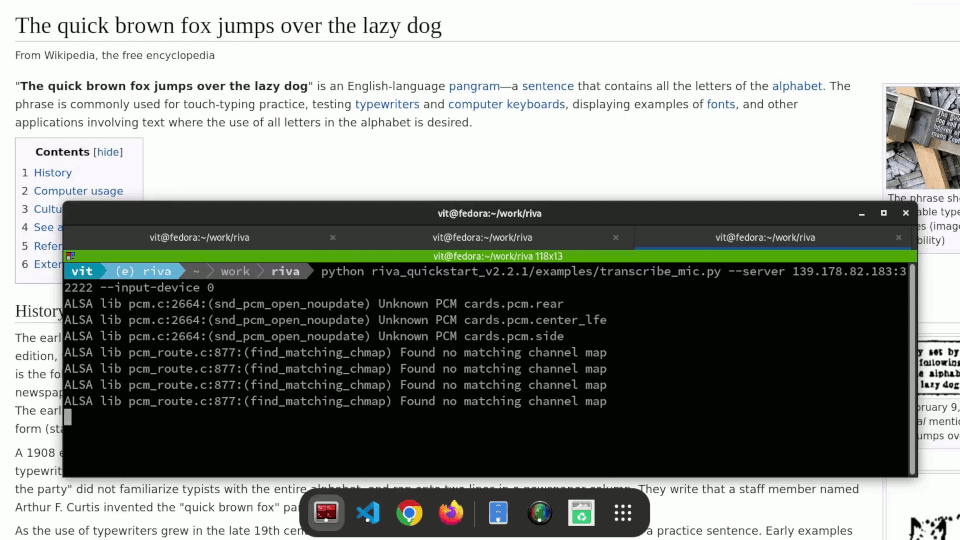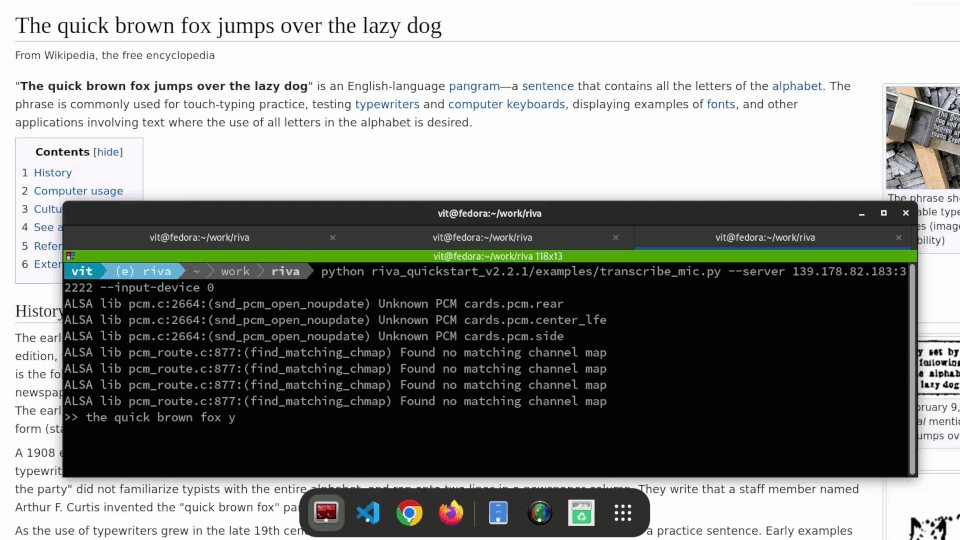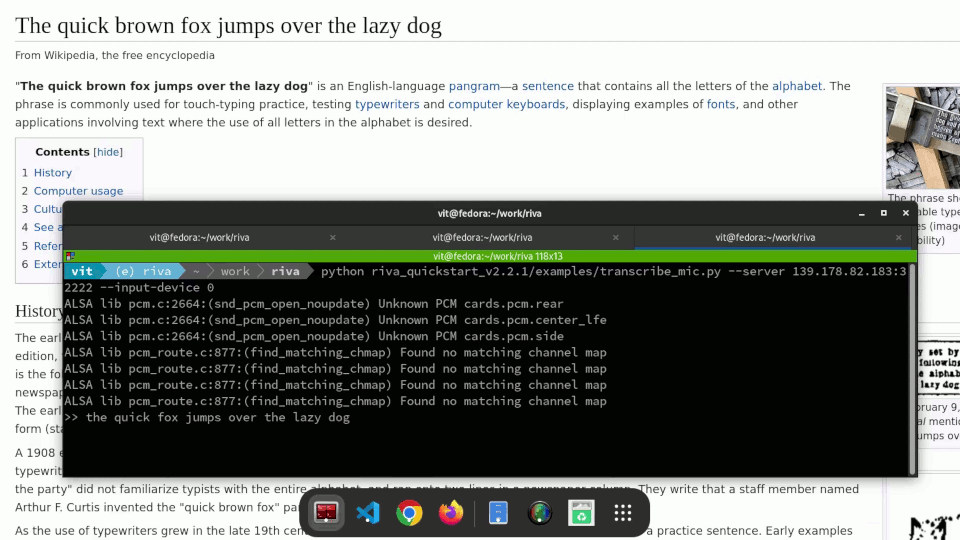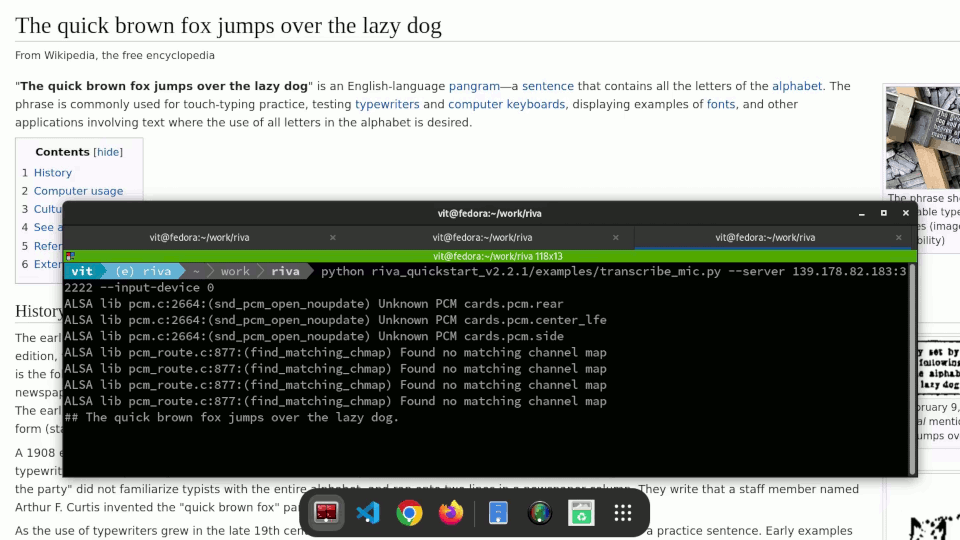
We have an automation script for that, of course. The Ansible playbook at https://github.com/empovit/riva-deployment automates the whole process from spinning up a GPU-enabled OpenShift cluster on Equinix Metal to deploying a Riva server to it. What’s left is just to run the Riva client, talk into the microphone, and watch your speech automatically transcribed in real time.
Example:
python riva_quickstart_v2.2.1/examples/transcribe_mic.py --server --server 147.28.142.251:32222 --input-device 9
Troubleshooting
Be patient, deploying a vSphere cluster takes time! Installing an SNO takes another 30-40 minutes.
We are aware of an issue that may cause upgrading ESXi from 6.5 to 7.0, and installing vCenter to fail. If you’re seeing failures of this Ansible task, try re-running the playbook:
TASK [vsphere : Install vSphere on Equinix Metal using Terraform]
If it still isn't working, run the Terraform script manually using the generated Terraform variable file, usually <temp_directory>/terraform.tfvars, for better diagnostics. Example:
terraform apply -var-file=~/sno-vgpu/terraform.tfvars
Then just re-run the Ansible playbook, as the Terraform part is idempotent.
For more troubleshooting tips, see the Troubleshooting document in the repository.
Conclusion
Red Hat OpenShift not only provides an enterprise-grade platform with enhanced security, monitoring, etc., but also gives containerized applications access to hardware accelerators such as NVIDIA GPUs.
Although bare metal beats virtualization in terms of performance, we can still see use-cases for the latter. And thanks to OpenShift and NVIDIA vGPU, anybody who wants to develop and run a modern AI/ML application doesn’t have to abandon their legacy infrastructure. Then, when ready for the transition, they can deploy the exact same application on bare metal and enjoy the improved performance.
We have demonstrated how to deploy an OpenShift cluster that benefits from an underlying NVIDIA GPU on VMware vSphere, and presented a full automation — using Ansible — of this otherwise tedious and error-prone installation and configuration process.
Über den Autor

Mehr davon
Nach Thema durchsuchen

Automatisierung
Das Neueste zum Thema IT-Automatisierung für Technologien, Teams und Umgebungen

Künstliche Intelligenz
Erfahren Sie das Neueste von den Plattformen, die es Kunden ermöglichen, KI-Workloads beliebig auszuführen

Open Hybrid Cloud
Erfahren Sie, wie wir eine flexiblere Zukunft mit Hybrid Clouds schaffen.

Sicherheit
Erfahren Sie, wie wir Risiken in verschiedenen Umgebungen und Technologien reduzieren

Edge Computing
Erfahren Sie das Neueste von den Plattformen, die die Operations am Edge vereinfachen

Infrastruktur
Erfahren Sie das Neueste von der weltweit führenden Linux-Plattform für Unternehmen

Anwendungen
Entdecken Sie unsere Lösungen für komplexe Herausforderungen bei Anwendungen

Original Shows
Interessantes von den Experten, die die Technologien in Unternehmen mitgestalten
Produkte
- Red Hat Enterprise Linux
- Red Hat OpenShift
- Red Hat Ansible Automation Platform
- Cloud-Services
- Alle Produkte anzeigen
Tools
- Training & Zertifizierung
- Eigenes Konto
- Kundensupport
- Für Entwickler
- Partner finden
- Red Hat Ecosystem Catalog
- Mehrwert von Red Hat berechnen
- Dokumentation
Testen, kaufen und verkaufen
Kommunizieren
Über Red Hat
Als weltweit größter Anbieter von Open-Source-Software-Lösungen für Unternehmen stellen wir Linux-, Cloud-, Container- und Kubernetes-Technologien bereit. Wir bieten robuste Lösungen, die es Unternehmen erleichtern, plattform- und umgebungsübergreifend zu arbeiten – vom Rechenzentrum bis zum Netzwerkrand.
Wählen Sie eine Sprache
Red Hat legal and privacy links
- Über Red Hat
- Jobs bei Red Hat
- Veranstaltungen
- Standorte
- Red Hat kontaktieren
- Red Hat Blog
- Diversität, Gleichberechtigung und Inklusion
- Cool Stuff Store
- Red Hat Summit