
This is the first part of a blog series dedicated to explaining what this new tool is, and how the OpenShift PerfScale (Performance and Scalability) team uses it to perform scalability tests in OpenShift.
Wait, what is this kube-burner thing?
Kube-burner is a tool designed to stress different OpenShift components basically by coordinating the creation and deletion of k8s resources. Along this blog series we’ll talk about how to use it in OpenShift 4.
It’s worth saying that kube-burner have been designed to be compatible with vanilla kubernetes and other distributions, since all it needs is a Kubernetes API.
Kube-burner is a static compiled binary written in Golang, and makes an extensive usage of the client-go library to interact with the API.
$ kube-burner -h
Kube-burner 🔥
Tool aimed at stressing a kubernetes cluster by creating or deleting lots of objects.
Usage:
kube-burner [command]
Available Commands:
check-alerts Evaluate alerts for the given time range
completion Generates completion scripts for bash shell
destroy Destroy old namespaces labeled with the given UUID.
help Help about any command
index Index metrics from the given time range
init Launch benchmark
version Print the version number of kube-burner
Flags:
-h, --help help for kube-burner
--log-level string Allowed values: debug, info, warn, error, fatal (default "info")
Use "kube-burner [command] --help" for more information about a command.
The configuration kube-burner uses is described in YAML configuration files, these files describe the different actions to perform in the cluster, Prometheus metrics to collect and Prometheus expressions to evaluate (AKA alerting).
For example, a simple configuration file can look like:
---
global:
writeToFile: true
metricsDirectory: collected-metrics
jobs:
- name: kube-burner-job
jobIterations: 5
qps: 20
burst: 40
namespacedIterations: true
cleanup: true
namespace: kube-burner-job-ns
jobPause: 1s
objects:
- objectTemplate: objectTemplates/deployment.yml
replicas: 1
Creating or deleting thousands of objects
As mentioned previously the main feature of Kube-burner is the ability to create or delete thousands of objects defined in a configuration file. These objects are created/deleted using a combination of loops+goroutines.
Within kube-burner exists the concept of jobIterations, which means the number of rounds a job will be executed, that is to say it will create as N-iterations of the objects described in the objects list.
Additionally, all declared objects in the list have the parameter replicas, which is configures the number of replicas of that object kube-burner will create in each iteration.
It’s important to note that kube-burner is able to perform namespaced iterations, meaning that each iteration will create a new namespace with the objects declared in the config. Otherwise, if this option is set to false all objects will be created within the same namespace.
The name of the namespaces that kube-burner will create is given by the parameter namespace, and in case of enabling the namespacedIterations parameter, it will append the number of the iteration after it. For example, let’s say we have a configuration like the following:
jobs:
- name: breaking-k8s
jobIterations: 2
namespace: breaking-k8s
namespacedIterations: true
objects:
- objectTemplate: resource.yml
replicas: 2
With this configuration. Kube-burner will create 2 namespaces named breaking-k8s-1 and breaking-k8s-2 with two replicas of the object declared in resource.yml
One of the best features kube-burner provides is the capability of configuring the rate the objects are created or deleted, this feature is determined by the parameters QPS and Burst (Which behaves similarly to k8s QPS and Burst parameters).
Kube-burner allows the user to pass variables to the object templates adding the parameters inputVars to the object, these variables are rendered using the default go-template library, so we can make use of the features this templating language provides:
kind: Pod
apiVersion: v1
metadata:
name: {{.JobName}}-{{.Iteration}}
labels:
name: {{.JobName}}
spec:
nodeSelector: {{ .nodeSelector}}
containers:
- name: {{.JobName}}
image: {{.containerImage}}
ports:
- containerPort: {{.containerPort}}
protocol: TCP
imagePullPolicy: IfNotPresent
securityContext:
privileged: {{.privileged}}
Apart from the variables manually injected by inputVars, there are other variables that are always available to be used in all objectTemplates such as Iteration, Replica, JobName and UUID.
Collecting & indexing metrics
In addition to creating or deleting objects, kube-burner has a metric collection mechanism which leverages Prometheus to collect metrics. These metrics are defined in expressions provided by a metric-profile configuration file. They can be collected for benchmark time range using as start and end markers the duration of the benchmark itself, kube-burner CLI also provides an index subcommand that allows us to collect & index metrics for a specific time range without requiring to launch any benchmark.
For example, the following metric profile can be useful to collect some etcd related metrics:
metrics:
- query: histogram_quantile(0.99, rate(etcd_disk_backend_commit_duration_seconds_bucket[2m]))
metricName: 99thEtcdDiskBackendCommitDurationSeconds
- query: histogram_quantile(0.99, rate(etcd_disk_wal_fsync_duration_seconds_bucket[2m]))
metricName: 99thEtcdDiskWalFsyncDurationSeconds
- query: histogram_quantile(0.99, rate(etcd_network_peer_round_trip_time_seconds_bucket[5m]))
metricName: 99thEtcdRoundTripTimeSeconds
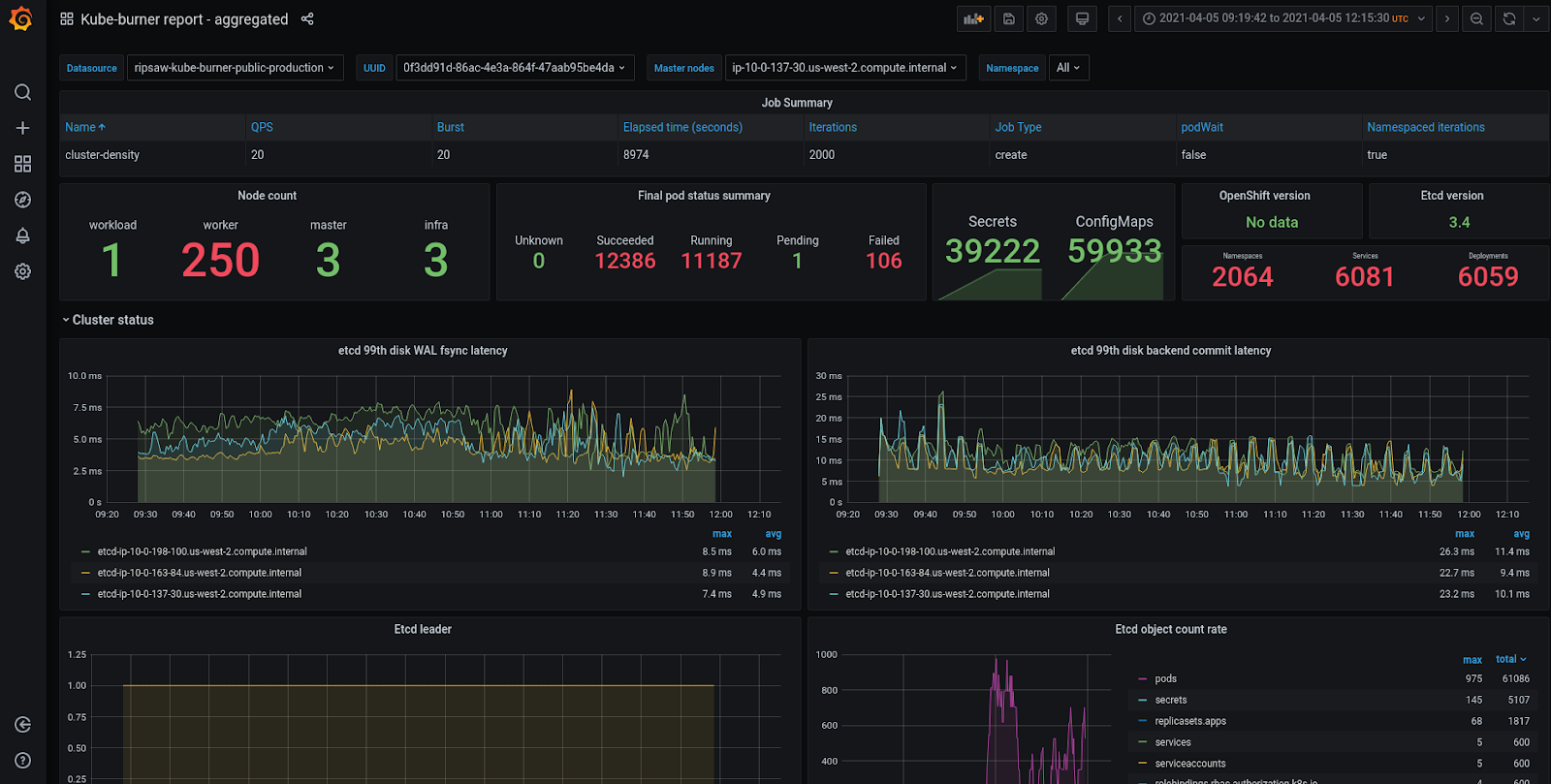
These metrics can be written to disk (In form of json file) or indexed to an external database, at the moment ElasticSearch is the only supported one. We, the OpenShift PerfScale team, are currently using grafana to represent these metrics we collect as shown in the screenshot below.
Alerting
Kube-burner includes an alert mechanism able to evaluate Prometheus expressions after the end of the latest Kube-burner's job. Similar to other features, these expressions are described in a YAML configuration file.
- expr: avg_over_time(histogram_quantile(0.99, rate(etcd_disk_wal_fsync_duration_seconds_bucket[2m]))[5m:]) > 0.01
description: 5 minutes avg. etcd fsync latency on {{$labels.pod}} higher than 10ms {{$value}}
severity: error
- expr: avg_over_time(histogram_quantile(0.99, rate(etcd_network_peer_round_trip_time_seconds_bucket[5m]))[5m:]) > 0.1
description: 5 minutes avg. etcd network peer round trip on {{$labels.pod}} higher than 100ms {{$value}}
severity: error
The code snippet below contains two alerts. Their prometheus expressions are configured by the expr field, the description field is used to raise a description of the alert once it raises. Last but not least, severity configures how kube-burner will behave in case of triggering an alert.
Kube-burner does not use Prometheus alerting system, as it uses its own expressions to evaluate metrics (those expressions could include prometheus alerts as well).
Apart from evaluating alerts raised during the duration of the benchmark, kube-burner has a specific check-alerts CLI option that allows to evaluate these expressions during a given time-range.
$ kube-burner check-alerts -u https://prometheus.url.com -t ${token} -a alert-profile.yml
INFO[2020-12-10 11:47:23] Setting log level to info INFO[2020-12-10 11:47:23] 👽 Initializing prometheus client
INFO[2020-12-10 11:47:24] 🔔 Initializing alert manager INFO[2020-12-10 11:47:24] Evaluating expression: 'avg_over_time(histogram_quantile(0.99, rate(etcd_disk_wal_fsync_duration_seconds_bucket[2m]))[5m:]) > 0.01'
ERRO[2020-12-10 11:47:24] Alert triggered at 2020-12-10 11:01:53 +0100 CET: '5 minutes avg. etcd fsync latency on etcd-ip-10-0-213-209.us-west-2.compute.internal higher than 10ms 0.010281314285714311' INFO[2020-12-10 11:47:24] Evaluating expression: 'avg_over_time(histogram_quantile(0.99, rate(etcd_network_peer_round_trip_time_seconds_bucket[5m]))[5m:]) > 0.1'
Starting with kube-burner
In addition to the above, kube-burner also has other cool features such as object verification, golang pprof collecting , pod’s startup phase latency calculations and many more… we’ll talk about some of these features in future blog entries.
As mentioned above, Kube-burner is distributed as a binary, pre-compiled binaries for several architectures are available in the releases section of the project’s repository (https://github.com/cloud-bulldozer/kube-burner/releases).
In case you you want to run kube-burner on top of a k8s pod there’re also container images available with the latest Kube-burner bits hosted in quay https://quay.io/repository/cloud-bulldozer/kube-burner
You can find extensive documentation in it’s readthedocs site
Über den Autor

Mehr davon
Nach Thema durchsuchen

Automatisierung
Das Neueste zum Thema IT-Automatisierung für Technologien, Teams und Umgebungen

Künstliche Intelligenz
Erfahren Sie das Neueste von den Plattformen, die es Kunden ermöglichen, KI-Workloads beliebig auszuführen

Open Hybrid Cloud
Erfahren Sie, wie wir eine flexiblere Zukunft mit Hybrid Clouds schaffen.

Sicherheit
Erfahren Sie, wie wir Risiken in verschiedenen Umgebungen und Technologien reduzieren

Edge Computing
Erfahren Sie das Neueste von den Plattformen, die die Operations am Edge vereinfachen

Infrastruktur
Erfahren Sie das Neueste von der weltweit führenden Linux-Plattform für Unternehmen

Anwendungen
Entdecken Sie unsere Lösungen für komplexe Herausforderungen bei Anwendungen

Original Shows
Interessantes von den Experten, die die Technologien in Unternehmen mitgestalten
Produkte
- Red Hat Enterprise Linux
- Red Hat OpenShift
- Red Hat Ansible Automation Platform
- Cloud-Services
- Alle Produkte anzeigen
Tools
- Training & Zertifizierung
- Eigenes Konto
- Kundensupport
- Für Entwickler
- Partner finden
- Red Hat Ecosystem Catalog
- Mehrwert von Red Hat berechnen
- Dokumentation
Testen, kaufen und verkaufen
Kommunizieren
Über Red Hat
Als weltweit größter Anbieter von Open-Source-Software-Lösungen für Unternehmen stellen wir Linux-, Cloud-, Container- und Kubernetes-Technologien bereit. Wir bieten robuste Lösungen, die es Unternehmen erleichtern, plattform- und umgebungsübergreifend zu arbeiten – vom Rechenzentrum bis zum Netzwerkrand.
Wählen Sie eine Sprache
Red Hat legal and privacy links
- Über Red Hat
- Jobs bei Red Hat
- Veranstaltungen
- Standorte
- Red Hat kontaktieren
- Red Hat Blog
- Diversität, Gleichberechtigung und Inklusion
- Cool Stuff Store
- Red Hat Summit