
Red Hat OpenStack Services on OpenShift is OpenStack—but it’s not just the same old OpenStack you're familiar with. Yes, it's the next version of Red Hat OpenStack Platform that maintains a trusted and stable cloud infrastructure with APIs based on the latest upstream Antelope release. However, there is much more to it! In this article, I show you how Red Hat OpenStack Services on OpenShift is set to redefine your cloud experience.
Red Hat OpenStack Services on OpenShift introduces a modern, cloud-native framework designed to revolutionize how you deploy, manage, monitor, and update your cloud infrastructure. It's a well-deserved upgrade, transforming Red Hat OpenStack Platform into an efficient and user-friendly platform for cloud infrastructure as a service.
Red Hat OpenStack Services on OpenShift is deployed on top of Red Hat OpenShift, leveraging it as versatile infrastructure. You can deploy and manage Red Hat OpenStack Services on OpenShift, which is, to an extent, an application running on top of OpenShift.
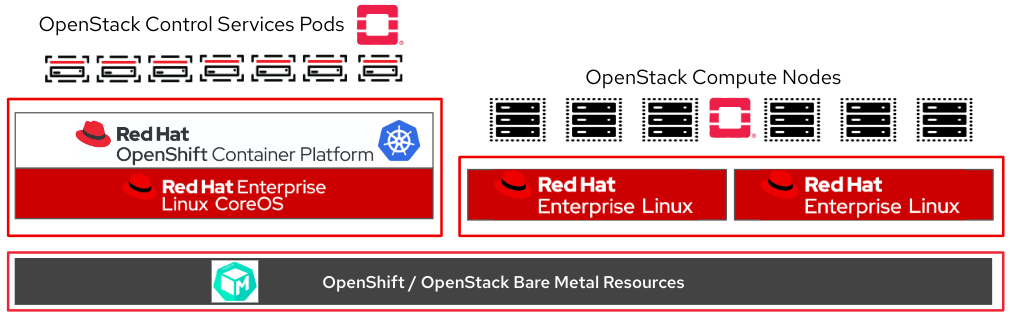
The new Red Hat OpenStack Services on OpenShift architecture has two main components:
- Control plane: Runs on top of OpenShift in pods. Managed by a set of dedicated operators
- External data plane: Multiple sets of virtualization or bare metal (ironic) hosts external to the OpenShift cluster (not managed by Kubernetes or OpenShift)
All the functions required for the creation of the Red Hat OpenStack Services on OpenShift configuration, for both the control plane and data plane, are based on CRD. This means that they are extensions to the Kubernetes API, manifested as Kubernetes operators. Like all Kubernetes constructs, they're configured by declarative YAML.
To enable Red Hat OpenStack Services on OpenShift functions, you create a catalog resource (CR) in OpenShift. For example:
piVersion: operators.coreos.com/v1alpha1
kind: CatalogSource
metadata:
name: cs-redhat-operator-index
namespace: openshift-marketplace
spec:
image: example.com/admin/redhat-operator-index:v4.16 # custom catalog image for relevant operators needed for the RHOSO deployment
---
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
name: openstack
namespace: openstack-operators
---
apiVersion: operators.coreos.com/v1alpha1
kind: Subscription
metadata:
name: openstack-operator
namespace: openstack-operators
spec:
name: openstack-operator
channel: alpha
source: openstack-operator-index
sourceNamespace: openstack-operatorsIn just a few minutes, with only that much configuration, you end up with this:
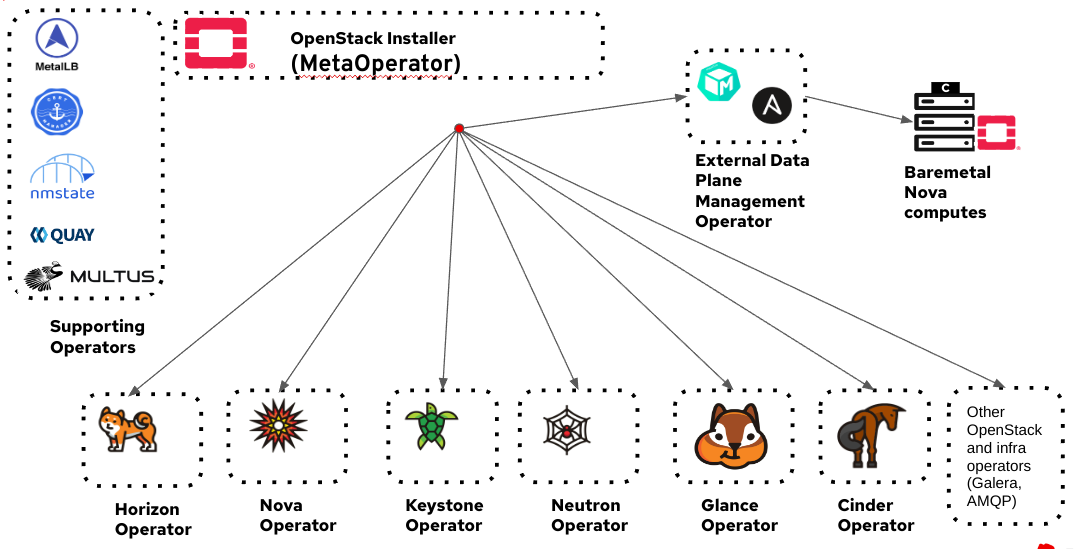
In addition to supporting infrastructure operators supplied by OpenShift (the left side of the diagram), by applying the CR above you get all the components needed to support a Red Hat OpenStack Services on OpenShift environment in minutes.
The control plane and data plane deployments follow a similar pattern, but with more options. With the new architecture, a Red Hat OpenStack Services on OpenShift deployment can be done in minutes, as opposed to hours. That's from the creation of the networking through the creation of the control plane and data plane. Deployment times vary, but that's mostly dependent upon the specifics of the data plane configuration.
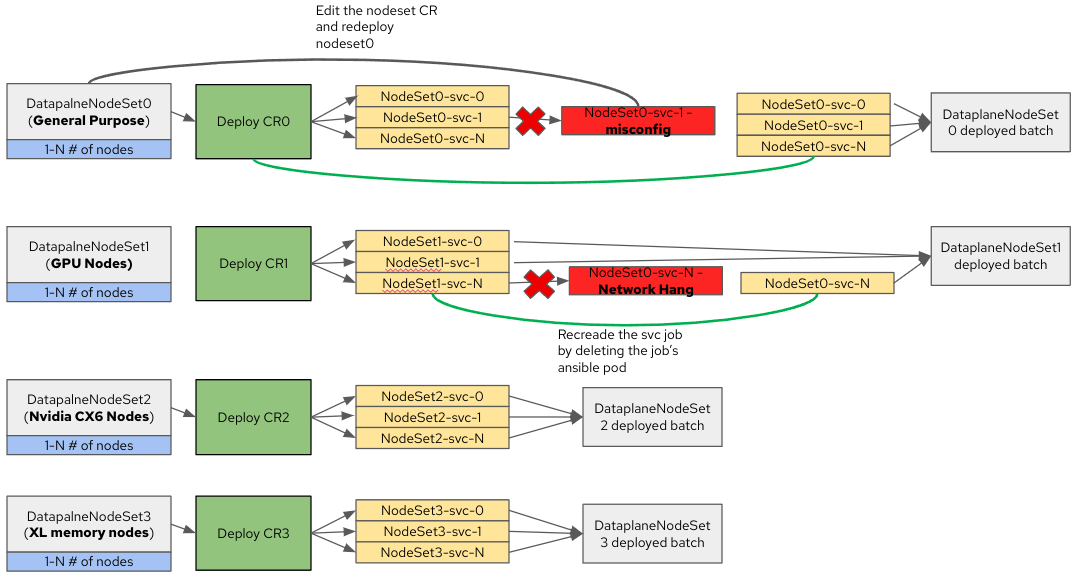
Red Hat OpenStack Services on OpenShift has a brand new deployment mechanism, called external data plane management (EDPM), to set up the openstack data plane.
External data plane management
There are several reasons to keep the OpenStack data plane external to OpenShift. For example:
- Enables the path from Red Hat OpenStack Platform (based on TripleO Director) to Red Hat OpenStack Services on OpenShift as an in-place upgrade without the need to migrate workloads
- Maintains the long lifecycle of 5 years for Red Hat OpenStack Services on OpenShift
- Keeps infra churn to a minimum. Even when the OpenShift cluster is periodically upgraded to retain support, the Red Hat OpenStack Services on OpenShift workloads are unaffected
The new data plane architecture is modular with three primary components:
- Data plane node set (DPNS): The main CR, in which you set up the data plane configuration, including:
- Node inventory
- A set of data plane services
- Environment variables, such as container image overrides, Bash commands, subscription registration, NTP data, DNS, and so on
- Network and storage configuration
- Data plane service (DPS): A CR pointing to a specific configuration and an Ansible playbook that executes the configuration on the node inventory you have in the DPNS.
Red Hat ships a set of default services to configure a basic deployment, but additional custom services can be added by the administrator, and included in the DPNS for a given set of nodes. Services are executed in serial. For example, a custom service to install a bunch of agents on the nodes probably needs to be placed after the network configuration takes place. - Deployment: The deployment CR is the "trigger" in which you specify the DPNS you want to group into a deployment. Once created, it triggers all of the DPS in order as Kubernetes jobs running in pods for each DPNS.
As you see in the diagram above, you can create multiple DPNS, and you can execute them in parallel. This creates a highly scalable deployment mechanism in a true parallel manner.
For example, if you want to deploy 100 nodes, then you can create 10 DPNS and execute them in parallel, as long as you have the resources to support the number of parallel jobs you can scale a deployment linearly.
For example, if your 100 nodes are homogeneous, then by creating the same 10 DPNS you're creating a micro failure domain around each one of the DPNS. As seen in the diagram above, a failure in one of the DPNS deployments is limited to that DPNS and does not cause a cascading failure. Even if several DPNS fail, you still end up with a working environment, and you could tend to the failure cause after the fact.
And that’s not even the best part! For a 10 DPNS homogeneous deployment, the time it takes for a single DPNS to deploy is the same time it takes all 10 to deploy for a true parallel and fully isolated modular deployment. Ready to give it a try? For more info, have a look at:
Über den Autor

Nach Thema durchsuchen

Automatisierung
Das Neueste zum Thema IT-Automatisierung für Technologien, Teams und Umgebungen

Künstliche Intelligenz
Erfahren Sie das Neueste von den Plattformen, die es Kunden ermöglichen, KI-Workloads beliebig auszuführen

Open Hybrid Cloud
Erfahren Sie, wie wir eine flexiblere Zukunft mit Hybrid Clouds schaffen.

Sicherheit
Erfahren Sie, wie wir Risiken in verschiedenen Umgebungen und Technologien reduzieren

Edge Computing
Erfahren Sie das Neueste von den Plattformen, die die Operations am Edge vereinfachen

Infrastruktur
Erfahren Sie das Neueste von der weltweit führenden Linux-Plattform für Unternehmen

Anwendungen
Entdecken Sie unsere Lösungen für komplexe Herausforderungen bei Anwendungen

Original Shows
Interessantes von den Experten, die die Technologien in Unternehmen mitgestalten
Produkte
- Red Hat Enterprise Linux
- Red Hat OpenShift
- Red Hat Ansible Automation Platform
- Cloud-Services
- Alle Produkte anzeigen
Tools
- Training & Zertifizierung
- Eigenes Konto
- Kundensupport
- Für Entwickler
- Partner finden
- Red Hat Ecosystem Catalog
- Mehrwert von Red Hat berechnen
- Dokumentation
Testen, kaufen und verkaufen
Kommunizieren
Über Red Hat
Als weltweit größter Anbieter von Open-Source-Software-Lösungen für Unternehmen stellen wir Linux-, Cloud-, Container- und Kubernetes-Technologien bereit. Wir bieten robuste Lösungen, die es Unternehmen erleichtern, plattform- und umgebungsübergreifend zu arbeiten – vom Rechenzentrum bis zum Netzwerkrand.
Wählen Sie eine Sprache
Red Hat legal and privacy links
- Über Red Hat
- Jobs bei Red Hat
- Veranstaltungen
- Standorte
- Red Hat kontaktieren
- Red Hat Blog
- Diversität, Gleichberechtigung und Inklusion
- Cool Stuff Store
- Red Hat Summit