
InstructLab is a community-driven project designed to simplify the process of contributing to and enhancing large language models (LLMs) through synthetic data generation. This initiative addresses several challenges faced by developers, such as the complexity of contributing to LLMs, the issue of model sprawl caused by forked models and the lack of direct community governance. Supported by Red Hat and IBM Research, InstructLab leverages novel synthetic data-based alignment tuning methods to improve model performance and accessibility. Here we'll talk about the current issue and technical challenges encountered when fine-tuning models traditionally and the approach that InstructLab takes to solve these problems.
The challenge: Low-quality data and inefficient use of computational resources
As the competition in the LLM space intensifies, the approach seems to be to build increasingly massive models trained from vast amounts of information from the public internet. However, large parts of the internet include redundant information or non-natural language data that does not contribute to the model's core functionality.
For instance, 80% of tokens used to train the LLM GPT-3, upon which later versions are built, originates from Common Crawl, which includes an enormous array of web pages. This dataset is known to contain a mix of high-quality text, low-quality text, scripts and other non-natural language data. It is estimated that a significant fraction of the data may be non-useful or low-quality content. (Common Crawl Analysis)
The result of this wide net of uncurated data is an inefficient use of computational resources, leading to high training costs that increase costs for consumers of these models down the line, as well as creating challenges in implementing these models in local environments.
What we’ve been seeing are an increasing number of models with fewer parameters where the quality and the relevance of data are more critical than sheer quantity. Models with more precise and intentional data curation are able to perform better, require less computing resources and provide higher quality results.
InstructLab's solution: Refining synthetic data generation
What’s unique about InstructLab is the ability to generate large amounts of data to be used for training, with only a small seed dataset to begin with. It utilizes the Large-scale Alignment for chatBots (LAB) methodology, which enhances LLMs with minimal human-generated data and computational overhead. This provides a user-friendly way for individuals to contribute relevant data, which is then enhanced using synthetic data generation with a model to assist during the generation process.
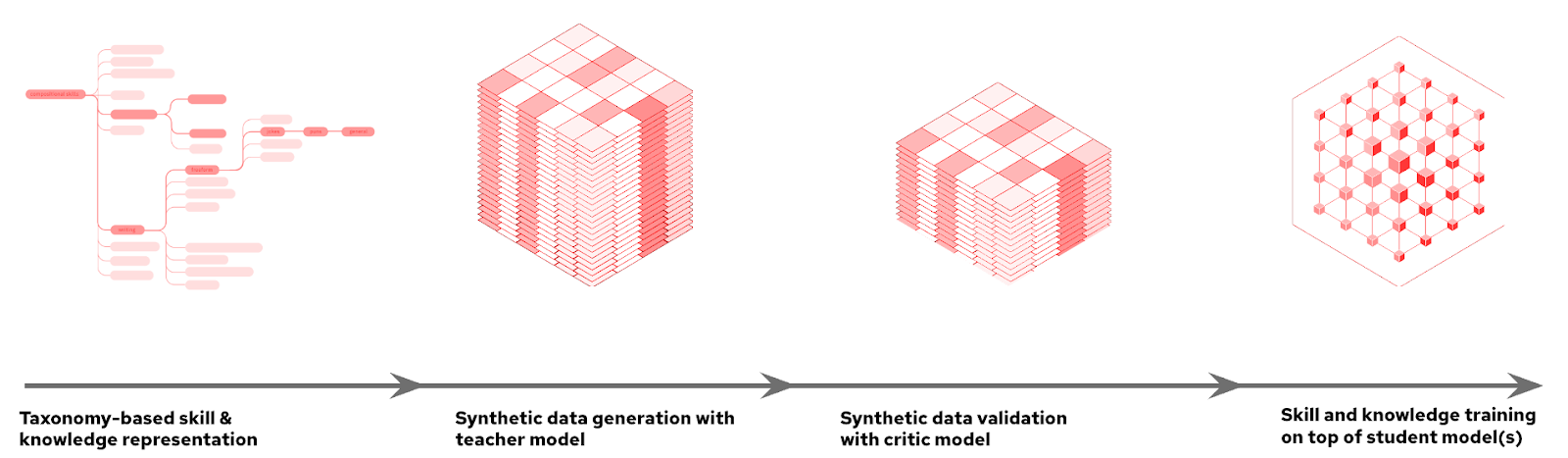
Key features of InstructLab's approach:
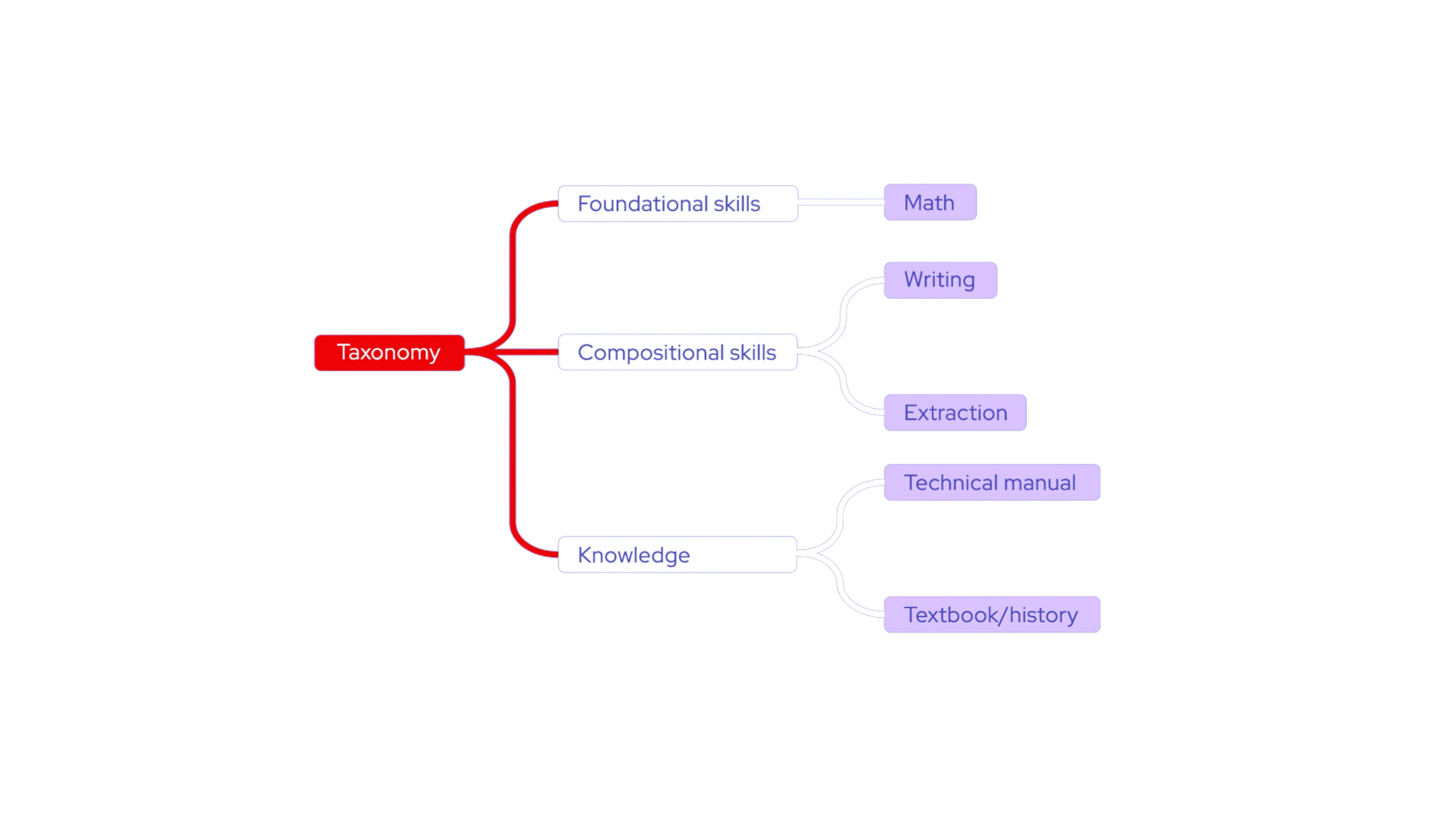
Taxonomy-driven data curation
The journey begins with the creation of a taxonomy—a hierarchical structure that organizes various skills and knowledge areas. This taxonomy serves as a roadmap for curating initial human-generated examples, which act as seed data for the synthetic data generation process. This data is organized in a structure that makes it simple to explore the model's existing knowledge and find gaps where you can contribute, reducing redundant unorganized information. At the same time, it allows for the specific targeting of a model to a use case or specific needs, using only easily formatted YAML files in question-and-answer pair format.
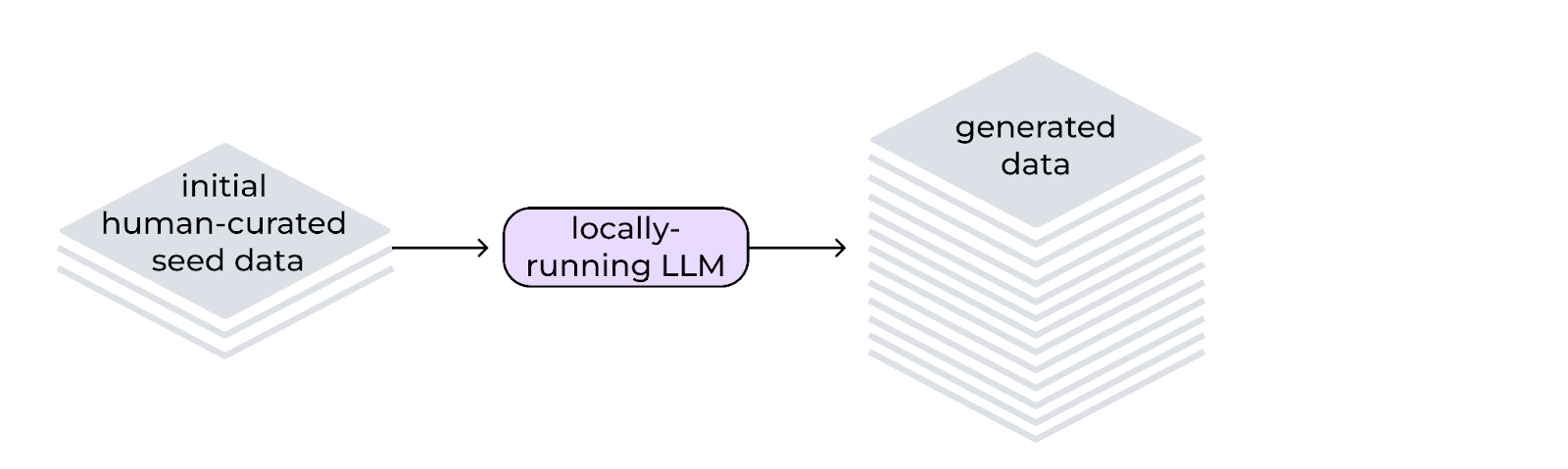
Synthetic data generation process
From the foundational seed data, InstructLab leverages a teacher model to generate new examples during the data generation process. What’s important to note is that this process isn’t using knowledge stored by the teacher model, instead using particular prompt templates that dramatically expand the dataset while making sure that the new examples maintain the structure and intent of the original human-curated data. The LAB methodology uses two specific synthetic data generators:
- Skills Synthetic Data Generator (Skills-SDG): Uses prompt templates for instruction generation, evaluation, response generation and final pair evaluation
- Knowledge-SDG: Generates instruction data for domains not covered by the teacher model, using external knowledge sources to ground generated data
Fortunately, this significantly reduces the need for large amounts of manually annotated data. Using the small, unique and human-generated examples as a reference allows the curation of hundreds, thousands or millions of question-and-answer pairs to influence the model’s weights and biases.
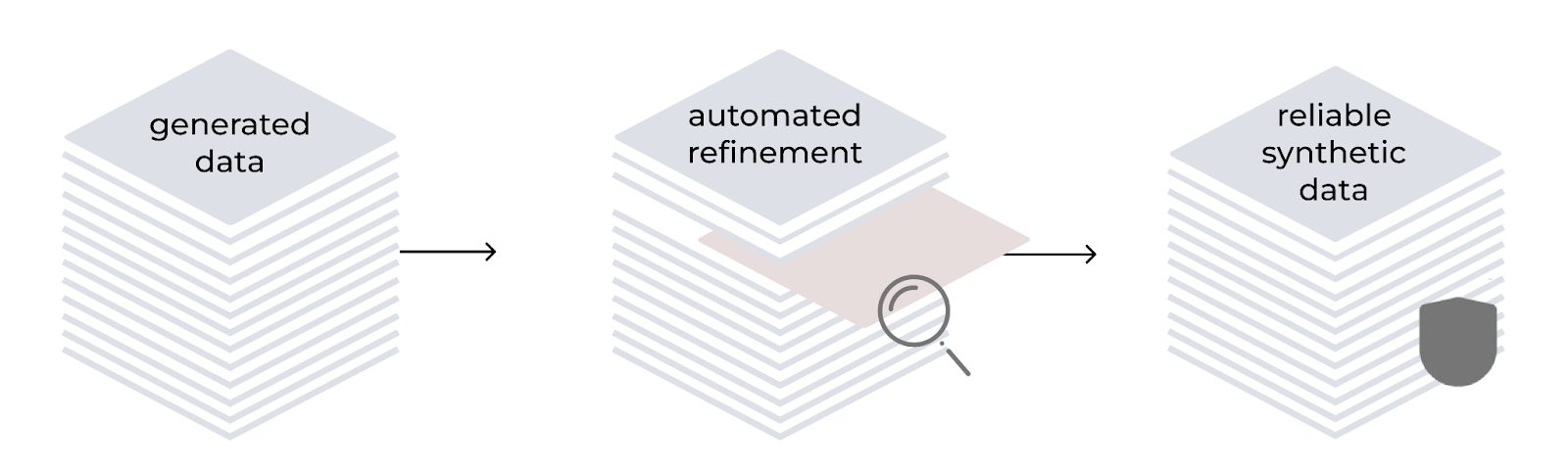
Automated refinement
The LAB method incorporates an automated refinement process to improve the quality and reliability of synthetically generated training data. Guided by a hierarchical taxonomy, it uses the model as both a generator and evaluator. The process includes instruction generation, content filtering, response generation and pair evaluation using a 3-point rating system. For knowledge-based tasks, generated content is grounded in reliable source documents, addressing potential inaccuracies in specialized domains.
Multiphase tuning framework
InstructLab implements a multiphase training process to incrementally improve the model's performance. This phased approach helps maintain training stability and a replay buffer of the data prevents catastrophic forgetting, allowing the model to continuously learn and improve. The generated synthetic data is utilized in a two-phase tuning process:
- Knowledge tuning: Integrates new factual information, divided into training on short responses followed by long responses and foundational skills
- Skills tuning: Enhances the model's ability to apply knowledge across various tasks and contexts, focusing on compositional skills
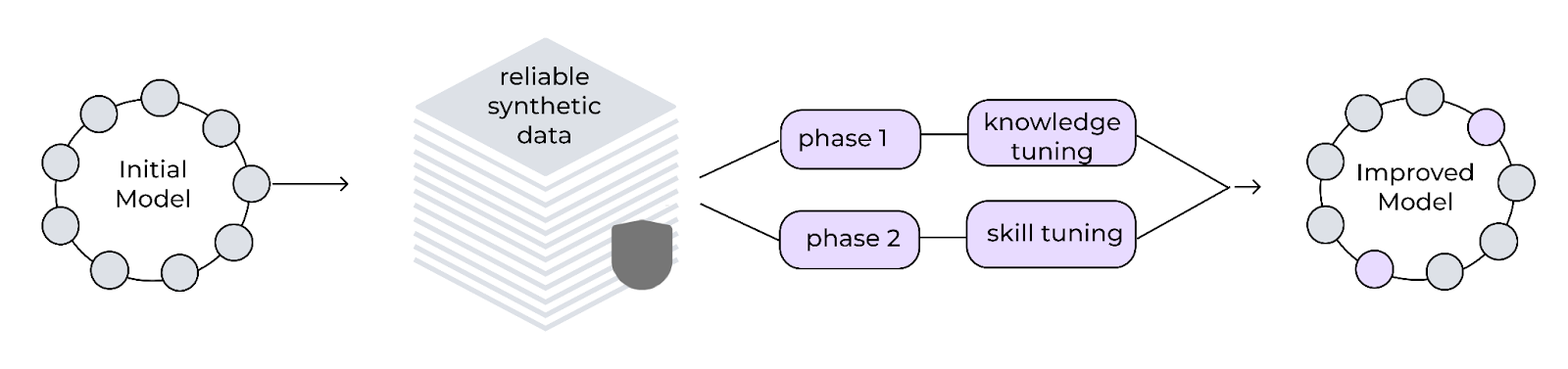
The framework uses small learning rates, extended warm-up periods and a large effective batch size for stability.
Iterative improvement cycle
The synthetic data generation process is designed to be iterative. As new contributions are made to the taxonomy, they can be used to generate additional synthetic data, which further enhances the model. This continuous cycle of improvement helps make sure that the model remains up-to-date and relevant.
InstructLab results and significance
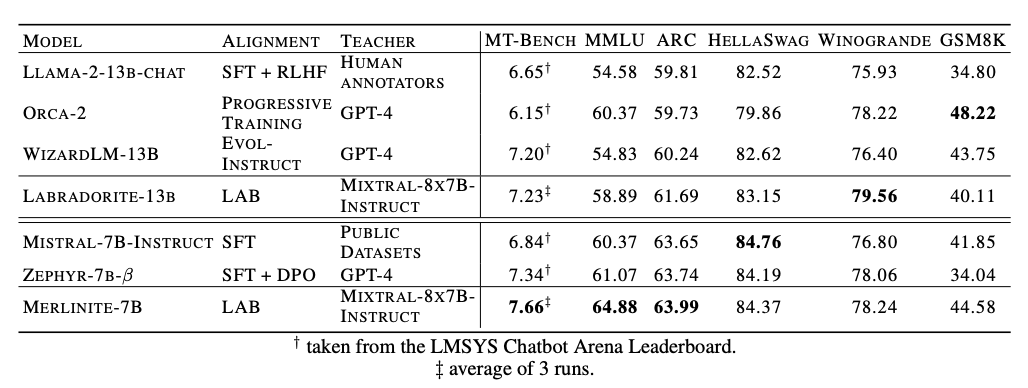
The significance of InstructLab lies in its ability to achieve state-of-the-art performance using publicly available teacher models instead of relying on proprietary models. In benchmarks, the InstructLab methodology has shown promising results. For example, when applied to Llama-2-13b (resulting in Labradorite-13b) and Mistral-7B (resulting in Merlinite-7B), the LAB-trained models outperformed current best models fine-tuned on their respective base models in terms of MT-Bench scores. They also maintained strong performance across other metrics, including MMLU (testing multitask language understanding), ARC (evaluating reasoning capabilities) and HellaSwag (assessing common sense inference), among others.
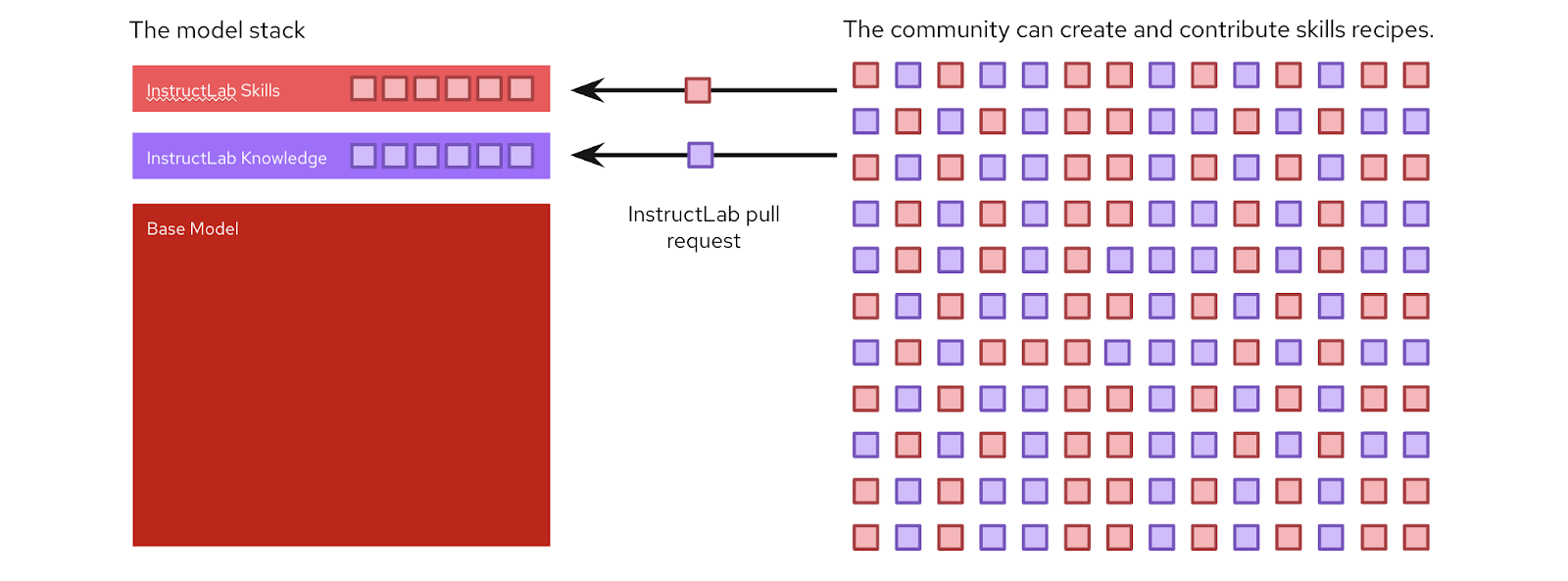
Community-based collaboration and accessibility
One of the significant benefits of InstructLab is its open source nature, and the goal of democratizing generative AI in a way that brings everyone together when shaping the future of models. The command line interface (CLI) is designed to run on common hardware, such as personal laptops, lowering the barrier to entry for developers and contributors. In addition, the InstructLab project encourages community involvement by allowing members to contribute new knowledge or skills to a main model built regularly and released on Hugging Face, feel free to check out the latest model here.
InstructLab's synthetic data generation process, built on the LAB methodology, represents a significant advancement in the field of generative AI. By efficiently enhancing LLMs with new capabilities and knowledge domains, InstructLab is paving the way for a more collaborative and effective approach to AI development. If you’d like to learn more about the project, we recommend visiting instructlab.ai or checking out this getting started guide to try out InstructLab on your machine!
À propos des auteurs

Cedric Clyburn (@cedricclyburn), Senior Developer Advocate at Red Hat, is an enthusiastic software technologist with a background in Kubernetes, DevOps, and container tools. He has experience speaking and organizing conferences including DevNexus, WeAreDevelopers, The Linux Foundation, KCD NYC, and more. Cedric loves all things open-source, and works to make developer's lives easier! Based out of New York.

Legare Kerrison is an intern on the developer advocacy team, focusing on providing developers with resources for Red Hat products, with an emphasis on Podman and Instructlab.
Contenu similaire
Parcourir par canal

Automatisation
Les dernières nouveautés en matière d'automatisation informatique pour les technologies, les équipes et les environnements

Intelligence artificielle
Actualité sur les plateformes qui permettent aux clients d'exécuter des charges de travail d'IA sur tout type d'environnement

Cloud hybride ouvert
Découvrez comment créer un avenir flexible grâce au cloud hybride

Sécurité
Les dernières actualités sur la façon dont nous réduisons les risques dans tous les environnements et technologies

Edge computing
Actualité sur les plateformes qui simplifient les opérations en périphérie

Infrastructure
Les dernières nouveautés sur la plateforme Linux d'entreprise leader au monde

Applications
À l’intérieur de nos solutions aux défis d’application les plus difficiles

Programmes originaux
Histoires passionnantes de créateurs et de leaders de technologies d'entreprise
Produits
- Red Hat Enterprise Linux
- Red Hat OpenShift
- Red Hat Ansible Automation Platform
- Services cloud
- Voir tous les produits
Outils
- Formation et certification
- Mon compte
- Assistance client
- Ressources développeurs
- Rechercher un partenaire
- Red Hat Ecosystem Catalog
- Calculateur de valeur Red Hat
- Documentation
Essayer, acheter et vendre
Communication
- Contacter le service commercial
- Contactez notre service clientèle
- Contacter le service de formation
- Réseaux sociaux
À propos de Red Hat
Premier éditeur mondial de solutions Open Source pour les entreprises, nous fournissons des technologies Linux, cloud, de conteneurs et Kubernetes. Nous proposons des solutions stables qui aident les entreprises à jongler avec les divers environnements et plateformes, du cœur du datacenter à la périphérie du réseau.
Sélectionner une langue
Red Hat legal and privacy links
- À propos de Red Hat
- Carrières
- Événements
- Bureaux
- Contacter Red Hat
- Lire le blog Red Hat
- Diversité, équité et inclusion
- Cool Stuff Store
- Red Hat Summit