In recent communications, Red Hat Emerging Technologies group has shared Red Hat’s involvement and passion to help in the sustainable computing area. One of the main projects in which this implication is relevant is KEPLER: Kubernetes-based Efficient Power Level Exporter.
In brief, Kepler is a metrics exporter that uses eBPF to collect energy-related system stats and export them. This allows Kepler to provide granular power consumption data for Kubernetes Pods, Namespaces, and Nodes. By making use of different energy sources, such as Running Average Power Limit (RAPL), Advanced Configuration and Power Interface (ACPI), Redfish based BMC, NVIDIA Management Library (NVML) when available, or trained models for specific hardware otherwise, Kepler can perform a power ratio modeling to compute specific contributions to the overall power consumption.
After all this community effort, Kepler graduated earlier this year to the CNCF Sandbox maturity level, which is the entry point for early stage projects. Check the CNCF project metrics page for more information.
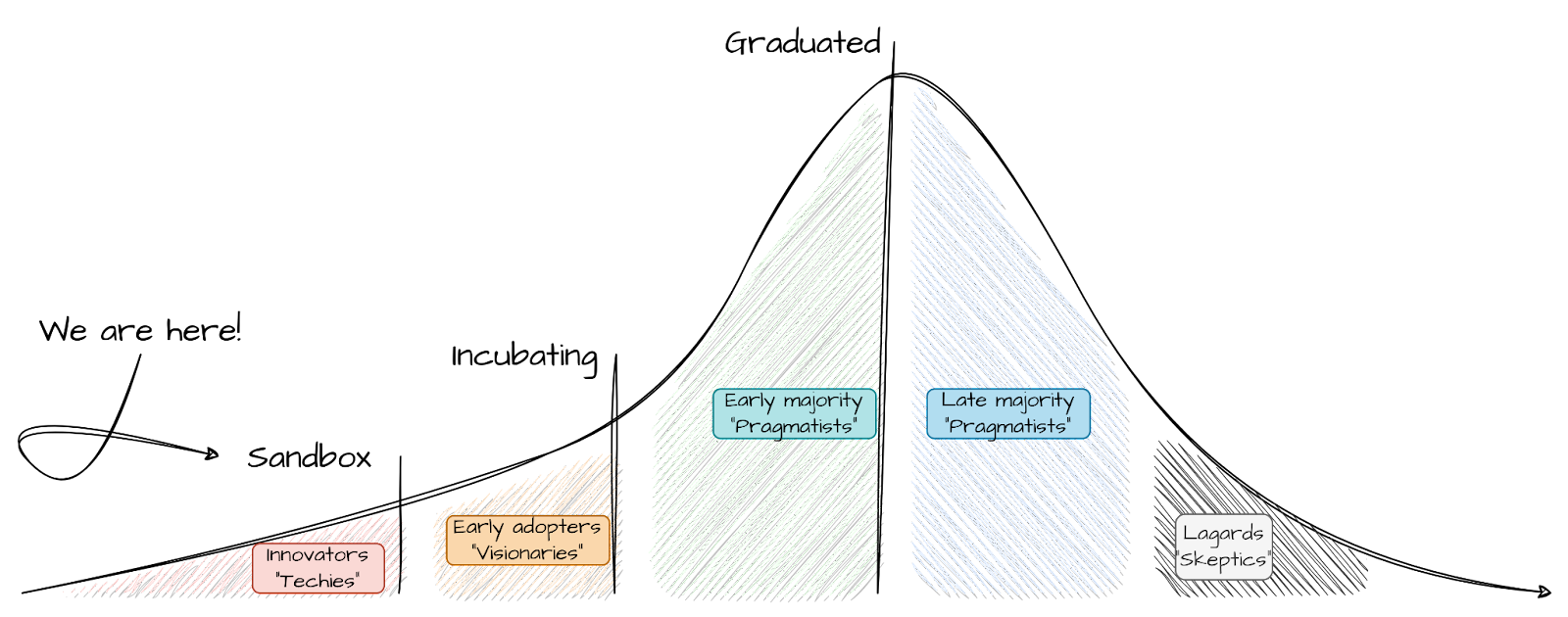
Being the first goal of this category to encourage public visibility, it seems to be right about time to start enabling all the “innovators” and “techies“ using OpenShift by providing a developer preview of Kepler inside OpenShift: power monitoring for Red Hat OpenShift.
While all the info is already available upstream, let’s deep dive into what has been keeping us busy in the last few months to help our users experiment with Kepler and imagine how it can guide them to understand how power consumption is distributed across their cluster. Throughout this article, we will show how to use the Kepler operator to install Kepler and visualize power consumption metrics in the OpenShift console. But first, we will explain some of the magic underneath so it’s easier to understand the contents and extension of this developer preview, as well as how to contribute to this exciting project for further advances.
What’s in the power monitoring box
Kepler is a large project nurtured by constant community contributions based on cutting-edge research. This means that the number of features that Kepler brings grows every day with different maturity levels. Like in every exciting journey, we will take one step at a time.
As outlined before, Kepler is able to combine both measurements and estimates from machine learning (ML) models to provide useful, high-granularity metrics. We will first only focus on providing support for the metrics exposure of direct measurements and ratios, while the community advances in validating the models and tuning them to different footprints and architectures. If you are curious about this work and want to contribute, you can dive into the Kepler model server features in both kepler-model-server and kepler-model-db public repositories.
For now, let’s focus on the value added by this developer preview.
Kepler operator
The Kepler operator aims to be the first point of contact for any OpenShift administrator interested in using Kepler. Its goal is to provide a streamlined solution for those who want to monitor the power usage of their workloads by simplifying Kepler’s deployment and management into an OpenShift cluster. Its setup and configuration are simplified by adding a tailored Custom Resource Definition (CRD). This operator also facilitates day-2 operations, such as upgrading, uninstalling, and redeploying. Overall, the Kepler operator helps to guide and ensure appropriate platform usage patterns. Its source code is located under the kepler-operator repository.
The Kepler exporter managed by the operator is the heart of power monitoring, and it uses eBPF to gather and export metrics related to power usage. This may seem a bit overwhelming, so let’s look a bit more in detail at how the Kepler exporter operates.
eBPF in Kepler
eBPF is getting a lot of attention lately. That’s not a surprise because it can be used to extend the capabilities of the Linux kernel in a safe and efficient way without requiring it to change its source code or load additional modules. In brief, one of the most useful functionalities eBPF provides is the ability to hook a function to a particular event. When such an event occurs, an action defined in that function is executed.
In this way, Kepler uses eBPF to extract utilization metrics and combine them with real-time power consumption metrics from the node components. As outlined previously, several APIs are available for this: RAPL, ACPI, or NVML to name a few.
All in all, by having on the one hand the real-time power consumption metrics from the native APIs and, on the other hand, the utilization done by each process, the next step is to compute a ratio to extract a process contribution to the overall picture. Just like that, Kepler made the utopian thought of monitoring container-level energy consumption a reality. All this information is made available to the end user as Prometheus metrics, which is pretty convenient.

Available metrics
You may be wondering what this data looks like. Kepler exposes a high variety of metrics representing the energy utilization broken down by contributors, allowing users to understand where the power consumption is coming from. But where to get started? Since all Kepler Prometheus metrics start with the kepler_ prefix, and are defined by following the Prometheus metrics guide, after reading the linked docs, users can easily discover the metrics that are relevant for them.
In order to extract the energy consumption within a container, the best way to get started is by visualizing kepler_container_joules_total, a very useful counter that provides the aggregated energy consumption. This is indeed the most performant way of gathering information, as it relieves the burden of combining complex queries into a single metric. If you are interested in power consumption rather than in energy, just compute the rate() over time of those joules, to get the power in watts. The same information is also available at the node level, under the kepler_node_core_joules_total counter.
Now, if you are interested in understanding contributions from all the named APIs that add up to end in those total joules, Kepler provides a breakdown of the energy consumption. From DRAM to RAPL and NVIDIA GPU, all metrics are available at a query distance. Last but not least, Kepler also provides hardware information such as node metadata like the node CPU architecture, or CPU cycles.
Bare metal vs virtual machines
The described data sources and APIs are available on bare metal clusters when appropriate permissions are granted but, in virtual machines, those system power metrics are normally not available. In these cases, directly measuring power consumption is not an option. The estimation modeling provided by the Kepler model server and Kepler DB looks very promising to close the circle for all use cases in the future.
Bear in mind that, today, when the mentioned APIs are not available, Kepler falls back to an estimator which applies a simple pre-trained model tuned for a particular example setup and might not coincide with your particular VM/hardware. See more details of the pre-trained models here.
Using power monitoring developer preview
Let’s get to it and see how to install power monitoring developer preview in an OpenShift cluster.
The following steps have been reproduced on OpenShift 4.13. Given that power monitoring is in Developer Preview, users should expect substantial changes before General Availability.
Enabling and configuring monitoring for user-defined projects
Before deploying Kepler, make sure that monitoring for user-defined projects is enabled by following the instructions provided in the OpenShift Container Platform documentation. In summary, just adding the “enableUserWorkload: true“ to a ConfigMap will do the trick. To check if it’s enabled, the user-workload-monitoring pods should be ready when typing:
oc -n openshift-user-workload-monitoring get pod
In any case, readers are recommended to check the latest outlined documentation.
Installing Kepler
Installation of the Kepler operator is done using the Operator Hub in the OpenShift Container Platform web console.
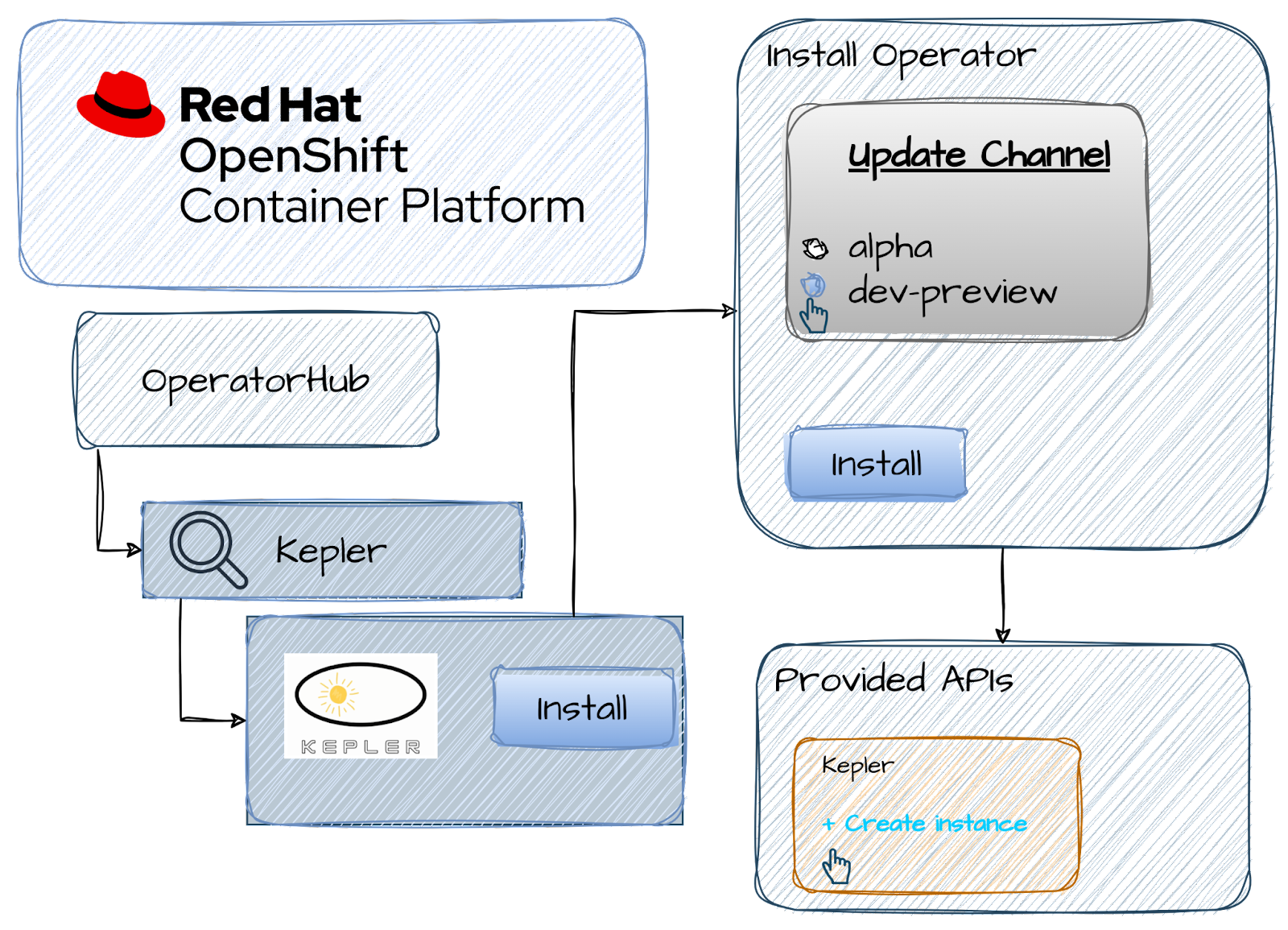
- Navigate to the OperatorHub: From the OpenShift dashboard, click on the "Operators" tab in the left-hand sidebar. Search for the Kepler Operator in the OperatorHub, you will find the Kepler Operator community version.
- Install: Click on the operator card to view details about it. This will provide you with information about the operator, including its description, version, and maintainers. This also contains links to the documentation and FAQ. Take your time to carefully navigate through the assets provided. Once you are done, click Install to configure the operator.
- Once in the ”Install Operator” dialog, choose Update Channel as dev-preview (instead of alpha). Leave the rest of the settings to default and click Install.
- Wait for the installation to complete. Once the "Installing Operator" dialog is done, you should be able to click on “View Operator” to inspect the Kepler Operator details. Also, note that Kepler Operator should now be listed in the "Installed Operators" sub-menu.
- Now, we are ready to tell the operator to deploy Kepler by creating an instance of the Kepler Custom Resource Definition (CRD). Navigate to the Kepler tab under the brand new Kepler operator, and click on Create Kepler. This will finally create a Kepler exporter DaemonSet. A message showing when the DaemonSet is ready will be available at the bottom.
This will also make a couple of dashboards available in the OpenShift Console to finally achieve our final goal: monitoring power in the Red Hat OpenShift console!
Visualizing power monitoring in the OCP console
OpenShift users can now access a Dev Preview of power monitoring for Red Hat OpenShift via the Web Console. By installing the newly-released Kepler Operator, as described in the section above, users can make use of two dashboards under the Observe>Dashboards UI - both providing different levels of details around power consumption metrics for a single cluster: (1) Power Monitoring / Overview and (2) Power Monitoring / Namespace.
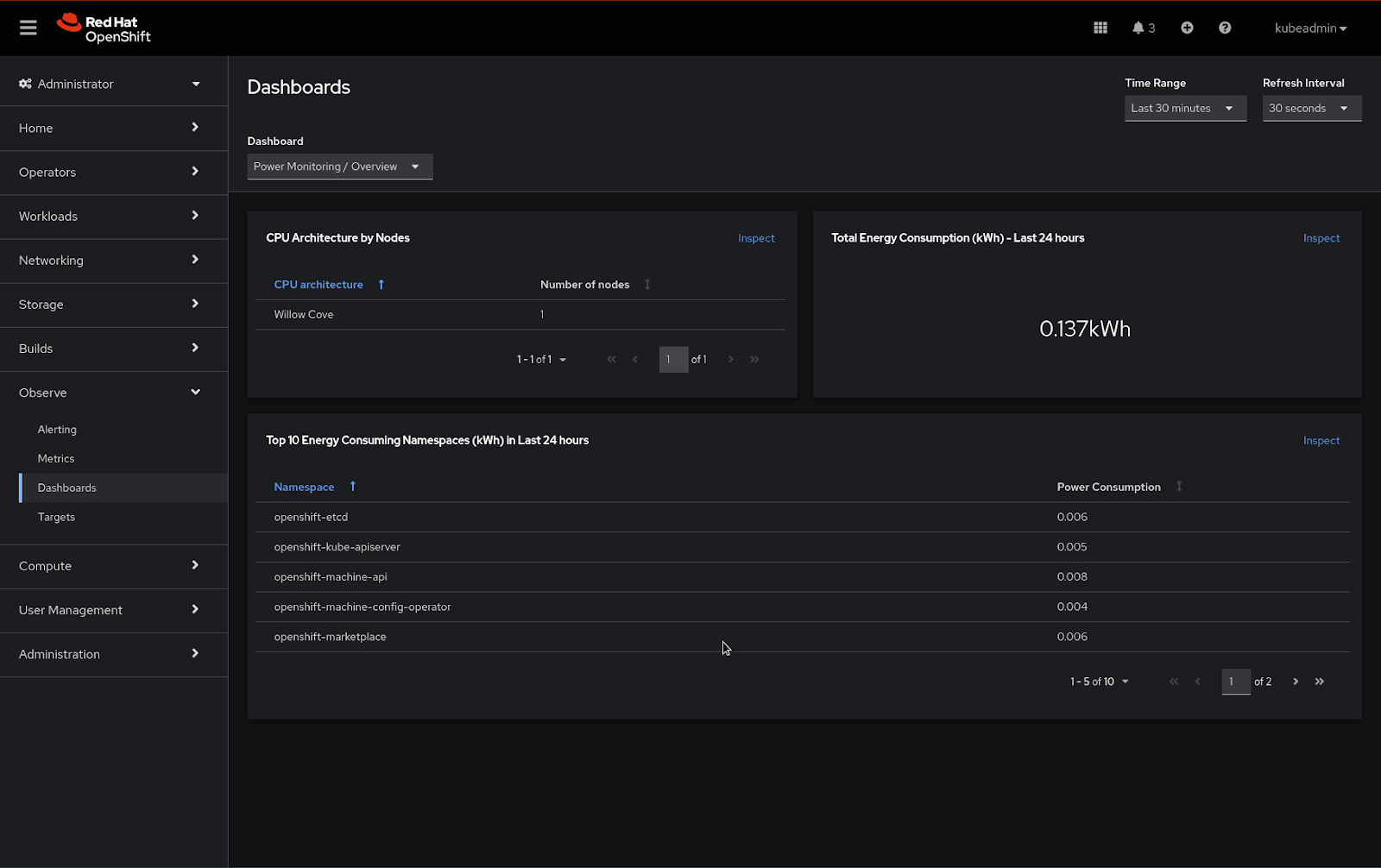
What information can you visualize? The (1) Power Monitoring / Overview dashboard provides you with a snapshot of the total energy consumption experienced by your cluster in the last 24 hours (measured in kilowatt-hour), including an indication of the selected CPU architecture and total monitored nodes. In this view, you can also visualize a table depicting the amount of power consumed by the top 10 namespaces in your cluster in the last 24 hours. This feature allows you to effectively take any action required to mitigate excessive consumption, without needing to necessarily investigate every namespace separately.
In combination with this first overview, users can also make use of the (2) Power Monitoring / Namespace dashboard. This view provides you with the possibility to drill down by namespace and pod. Specifically, you will be able to visualize key power consumption metrics, such as consumption in DRAM, PKG, GPU, and others by namespace - allowing you to investigate key peaks and more easily identify the primary root causes of high consumption.
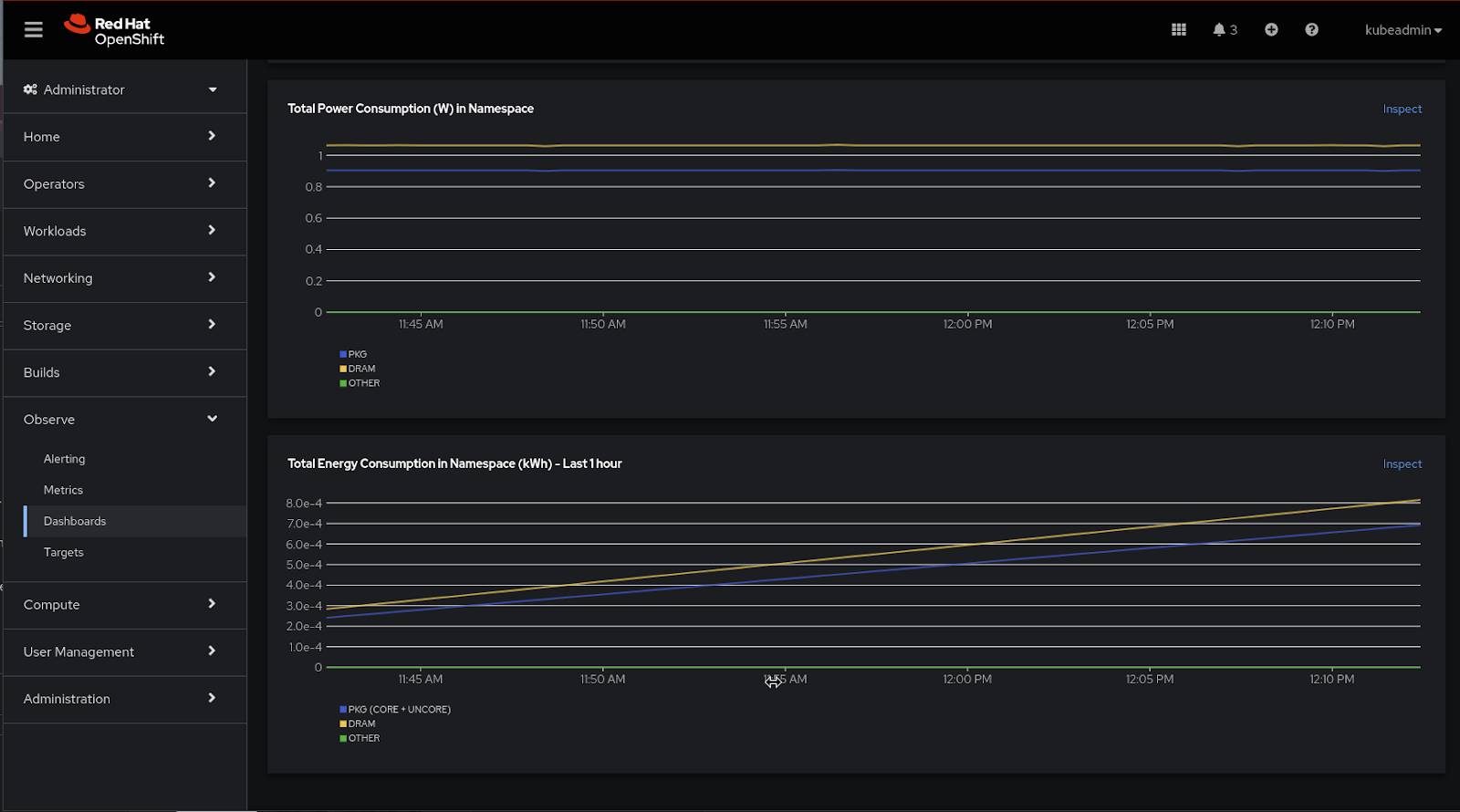
We are looking forward to receiving your feedback on the ease of navigation and the charts you find the most valuable for your use case.
Remove power monitoring
When you are done, if you want to remove the kepler, delete the kepler instance and the operator like any other package. Don’t forget to also follow the instructions on disabling monitoring for user-defined projects if you don’t further need it.
For advanced users: Creating your own dashboards
But that’s not all. The community also provides instructions and scripts to deploy a community Grafana dashboard to play around and create your own dashboards. Check the community documentation if you are interested.
Providing Feedback
Although power monitoring for Red Hat OpenShift is currently in an experimental stage and is expected to undergo substantial changes in the upcoming weeks and months, we value and welcome any feedback regarding this new project. Community members can share their feedback by initiating issues in the kepler-operator or kepler, as well as by joining the CNCF slack #kepler-project channel. For OpenShift customers, we encourage you to raise questions and provide feedback through your account teams, and we would be more than happy to arrange meetings to discuss power monitoring for Red Hat OpenShift and our future strategies.
Please bear in mind that, as a developer preview feature, we are not currently accepting support cases.
What comes next?
Our plan is to continue with the productization activities while listening to feedback from the community. We are working to provide a great experience for our users by upgrading the operator capacity level with lifecycle improvements and deep insights but, this time, in the form of a Red Hat operator apart from the already available community one for future releases. We plan to also integrate power monitoring with the rest of the Red Hat OpenShift Observability ecosystem including further dashboard customization in the OpenShift console and OpenTelemetry support. Of course, we expect lots of contributions from the community too, so stay tuned for much more!
Acknowledgments
We really want to acknowledge and thank the upstream community that is pushing to get this project to become a reality, collaborating with all companies contributing, but also everyone involved here at Red Hat, from the Emerging Technologies group to the Power Monitoring and User Interface teams under the Observability portfolio and those in the field contributing by gathering early feedback and work with our customers.
Further reading and links
- Technically Speaking (E21): Cloud native sustainability with Kepler
- Introducing Kepler: Efficient power monitoring for Kubernetes - Red Hat Emerging Technologies
- Sustainability, the cloud native way - Red Hat Emerging Technologies
- How the Kepler project is working to advance environmentally-conscious efforts
À propos de l'auteur

Jose is a Senior Product Manager at Red Hat OpenShift, with a focus on Observability and Sustainability. His work is deeply related to manage the OpenTelemetry, distributed tracing and power monitoring products in Red Hat OpenShift.
His expertise has been built from previous gigs as a Software Architect, Tech Lead and Product Owner in the telecommunications industry, all the way from the software programming trenches where agile ways of working, a sound CI platform, best testing practices with observability at the center have presented themselves as the main principles that drive every modern successful project.
With a heavy scientific background on physics and a PhD in Computational Materials Engineering, curiousity, openness and a pragmatic view are always expected. Beyond the boardroom, he is a C++ enthusiast and a creative force, contributing symphonic and electronic touches as a keyboardist in metal bands, when he is not playing videogames or lowering lap times at his simracing cockpit.
Plus de résultats similaires
AI in telco – the catalyst for scaling digital business
Simplify Red Hat Enterprise Linux provisioning in image builder with new Red Hat Lightspeed security and management integrations
Can Kubernetes Help People Find Love? | Compiler
Scaling For Complexity With Container Adoption | Code Comments
Parcourir par canal

Automatisation
Les dernières nouveautés en matière d'automatisation informatique pour les technologies, les équipes et les environnements

Intelligence artificielle
Actualité sur les plateformes qui permettent aux clients d'exécuter des charges de travail d'IA sur tout type d'environnement

Cloud hybride ouvert
Découvrez comment créer un avenir flexible grâce au cloud hybride

Sécurité
Les dernières actualités sur la façon dont nous réduisons les risques dans tous les environnements et technologies

Edge computing
Actualité sur les plateformes qui simplifient les opérations en périphérie

Infrastructure
Les dernières nouveautés sur la plateforme Linux d'entreprise leader au monde

Applications
À l’intérieur de nos solutions aux défis d’application les plus difficiles
Virtualisation
L'avenir de la virtualisation d'entreprise pour vos charges de travail sur site ou sur le cloud