
Managing capacity and overcommitment in Red Hat OpenShift can seem complex, but understanding a few key concepts makes it simpler. Here’s a breakdown of what you need to know about pod requests, limits, and best practices for setting them, along with how each topic contributes to effective capacity management and overcommitment.
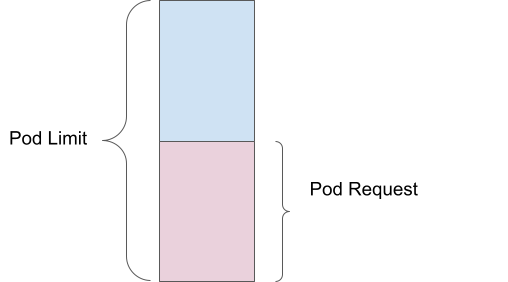
Pod request
A pod request is the amount of compute resources (such as memory or CPU) that you specify as the minimum required for your container to run. For example, if you set a memory request of 1 Gi, then the scheduler ensures that at least 1 Gi of memory is available for your pod before placing it on a node.
Capacity management benefit: Ensures that essential resources are reserved for each pod, preventing resource shortages and ensuring that all pods have the minimum resources they need to operate effectively.
Pod limit
A pod limit, on the other hand, is the maximum amount of resources that your pod can use. If you set a memory limit of 2 Gi, then the pod can use up to 2 Gi of memory, but no more. This is enforced by the kernel through cgroups, which helps prevent any single pod from consuming too many resources and affecting other pods.
Capacity management benefit: Protects against resource overuse by individual pods, ensuring fair distribution of resources across all running pods.
Overcommitment
Overcommitment happens when the limit exceeds the request. For instance, if a pod has a memory request of 1 Gi and a limit of 2 Gi, it is scheduled based on the 1 Gi request but can use up to 2 Gi. This means the pod is overcommitted by 200%, as it can use twice the amount of memory it was guaranteed.
Capacity management benefit: Allows for more efficient utilization of cluster resources by enabling pods to use additional resources when available, without guaranteeing those resources
Consequences of not setting requests and limits
Requests and limits help your Red Hat OpenShift instance run efficiently and predictably. When you don't define them, there are consequences.
No guaranteed resources
If you don’t set resource requests, then the scheduler doesn't guarantee any specific amount of CPU or memory for your pods. This can lead to poor performance or even pod failure when the node is under heavy load.
No upper bound on resource usage
Without limits, a container can use as much CPU and memory as it needs. This could lead to resource starvation, where one container uses all available resources, causing other containers to fail or be evicted.
Capacity management benefit: Setting both requests and limits ensures balanced resource allocation, preventing both under-provisioning (resource starvation) and over-provisioning (resource hogging).
Best practices for setting requests and limits
In general, there are 5 best practices to follow when setting requests and limits:
- Always set memory and CPU requests
- Avoid setting CPU limits, because it can lead to throttling
- Monitor your workload. Set requests based on average usage over time
- Set memory limits to a scale factor of the request
- Use Vertical Pod Autoscaler (VPA) to tune and adjust these values over time
Capacity management benefit: These practices ensure that each pod gets the resources it needs while avoiding over-allocation, leading to efficient resource utilization and improved cluster performance.
Using Vertical Pod Autoscaler (VPA) for right-sizing
The Vertical Pod Autoscaler (VPA) component of Red Hat OpenShift adjusts the amount of CPU and memory assigned to a pod when the pod requires more resources. When using VPA, keep this guidance in mind:
- Install and configure VPA in Recommendation mode only
- Run real-world load simulations on your pods
- Observe the recommended values, and adjust the pod resources accordingly
Why Recommendation mode only?
If you set VPA to Automatic mode, pods are restarted to adjust to the recommended values. In-place VPA (without restarts) is in alpha, as of Red Hat OpenShift 4.16.
Adjusting watch time for recommenders
VPA supports custom recommenders, allowing you to set watch times to 1 day, 1 week, or 1 month, based on your needs. For more details, read Automatically adjust pod resource levels with the vertical pod autoscaler.
Capacity management benefit: VPA helps by dynamically adjusting resource requests and limits based on actual usage patterns. This ensures optimal resource allocation, and minimizes overcommitment.
System reserved resources in Red Hat OpenShift
A resource can be designated as system reserved. This means that Red Hat OpenShift allocates a portion of node resources (CPU and memory) for system-level processes, like the kubelet and container runtime. There are many benefits to this:
- Ensures dedicated resources for system processes, preventing contention with application workloads
- Improves node stability and performance by avoiding resource starvation for essential system services
- Maintains reliable operation and predictable performance of the cluster
You can enable automatic resource allocation for nodes by following the instructions for self-managed OpenShift clusters in the OpenShift documentation. A managed OpenShift instance, like Red Hat OpenShift Service on AWS (ROSA), manages these for you.
Capacity management benefit: Allocating resources for system processes ensures that essential services run smoothly, preventing disruptions in application performance due to system-level resource contention.
Cluster autoscaler
A cluster autoscaler automatically adds or removes nodes as needed. This works in conjunction with the Horizontal Pod Autoscaler (HPA). For more details, read OpenShift Cluster Autoscaler guide and OpenShift documentation on autoscaling.
Capacity management benefit: The cluster autoscaler ensures that your cluster has the right number of nodes to handle the current workload, automatically scaling up or down as needed. This helps maintain optimal resource utilization and cost efficiency.
ClusterResourceOverride operator (CRO)
The ClusterResourceOverride operator helps optimize resource allocation to ensure efficient and balanced usage across the cluster.
Example Configuration:
- Requested CPU: 100 millicores (0.1 cores)
- Requested Memory: 200 MiB (Megabytes)
- CPU Limit: 200 millicores (0.2 cores)
- Memory Limit: 400 MiB
Overrides:
- CPU Request Override: 50% of what is requested
- Memory Request Override: 75% of what is requested
- CPU Limit Override: 2 times the request
- Memory Limit Override: 2 times the request
Adjusted resources:
- Requested CPU: 100 millicores × 50% = 50 millicores (0.05 cores)
- Requested Memory: 200 MiB × 75% = 150 MiB
- CPU Limit: 50 millicores × 2 = 100 millicores (0.1 cores)
- Memory Limit: 150 MiB × 2 = 300 MiB
For more details, read Cluster-level overcommit using the Cluster Resource Override Operator.
Capacity management benefit: By overriding default resource requests and limits, you can ensure that resources are allocated efficiently, preventing both underutilization and overcommitment.
Scalability envelope
I think of the scalability envelope as a higher-dimensional cube. If you stay within the envelope, your performance Service Level Objectives (SLO) are met, and your Red Hat OpenShift cluster functions smoothly. As you move along one dimension, your capacity along other dimensions decreases. You can use the OpenShift dashboard to monitor your Green zone (where you are safely within the comfort zone for scaling your cluster objects) and Red zone (beyond which, you should not scale the cluster objects).
For more details, read Node metrics dashboard.
Capacity management benefit: Understanding and operating within the scalability envelope helps ensure that your cluster performs reliably under varying loads, preventing resource bottlenecks and ensuring consistent performance.
Pod autoscaling
There are several methods of autoscaling pods on Red Hat OpenShift. We've already discussed Vertical Pod Autoscaling (VPA), but there are other strategies as well.
Horizontal Pod Autoscaling (HPA)
HPA scales pods horizontally by adding more replicas. This is useful for stateless applications in production environments, improving application performance and uptime by handling load better and avoiding Out Of Memory (OOM) kills. For more details, read Automatically scaling pods with the horizontal pod autoscaler.
Custom Metric Autoscaler
This scales your pods based on user-defined metrics, suitable for various environments including production, testing, and development. It improves application uptime and performance by monitoring and scaling based on specific pressure points. For more details, read Custom Metrics Autoscaler operator. overview.
Capacity management benefit: Autoscaling based on workload demand ensures that your applications always have the necessary resources to handle varying loads, enhancing both performance and resource efficiency.
OpenShift scheduler
The LowNodeUtilization profile of OpenShift's scheduler spreads pods evenly across nodes to achieve low resource usage for each node. Benefits include:
- Cost efficiency in cloud environments, achieved by minimizing the number of nodes needed
- Improved resource allocation across the cluster
- Energy efficiency in data centers
- Enhanced performance from preventing node overload
- Prevention of resource starvation by balancing workloads
For more details, read Scheduling pods using a scheduler profile.
Capacity management benefit: By ensuring even resource distribution, the scheduler helps avoid hotspots and underutilized nodes, leading to a more balanced and efficient cluster.
OpenShift descheduler
The AffinityAndTaints profile evicts pods that violate inter-pod anti-affinity, node affinity, and node taints. Benefits include:
- Correcting suboptimal pod placement
- Enforcing node affinities and anti-affinities
- Responding to node taint changes to ensure only compatible pods remain on the node
For more details, read Evicting pods using the descheduler
Capacity management benefit: The descheduler helps maintain optimal pod placement over time, adapting to changes in the cluster and ensuring efficient use of resources while respecting affinity and taint constraints.
By following these best practices and using the tools available in OpenShift, you can effectively manage capacity and overcommitment, ensuring your applications run smoothly and efficiently.
Red Hat Advanced Cluster Management Right Sizing
Red Hat Advanced Cluster Management for Kubernetes — Right Sizing is now available as an enhanced developer preview. The goal of RHACM Right Sizing is to provide platform engineering teams with CPU and memory-based namespace level recommendations. RHACM Right Sizing is currently powered by Prometheus recording rules, allowing you to apply maximum and peak value logic across different aggregation periods (1, 2, 5, 10, 30, 60, and 90 days).
The benefits of using RHACM Right Sizing include:
- Identify the biggest resource offenders (for example, areas that cause underutilization)
- Promote transparency across your organization and trigger relevant conversations
- Improve fleet management through RHACM, allowing for cost efficiency and resource optimization no matter how many managed clusters you need to deploy
- A simplified user navigation provided in a dedicated Grafana dashboard - as part of the RHACM console
Capacity management benefit: RHACM Right Sizing capabilities allow platform engineers to access CPU and memory-based right sizing recommendations displayed in a dedicated Grafana dashboard - part of the Red Hat Advanced Cluster Management for Kubernetes console, allowing users to access key recommendations based on various aggregation periods, including longer time frames - as utilization varies over time. Those recommendations thus result to be user-friendly and easily consumable (see Figures below).
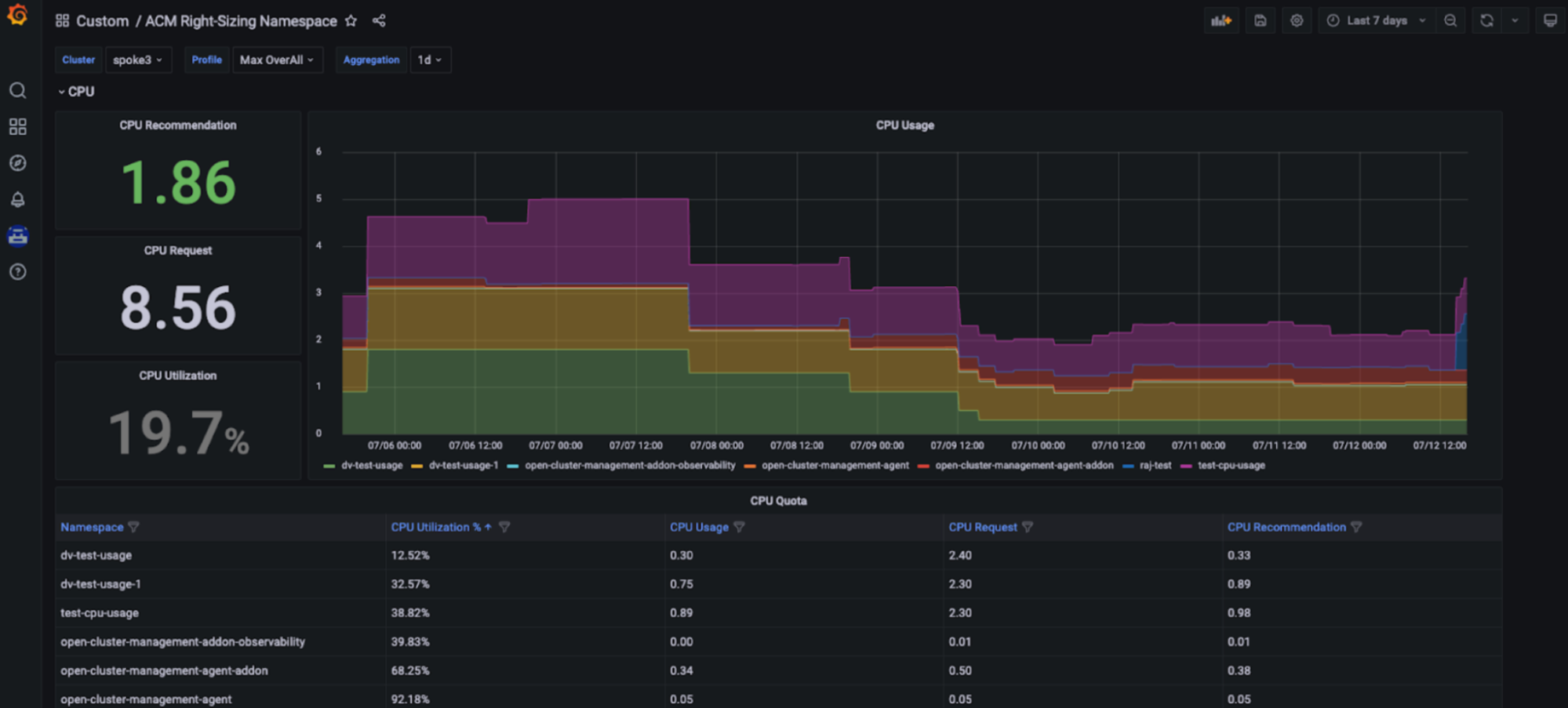
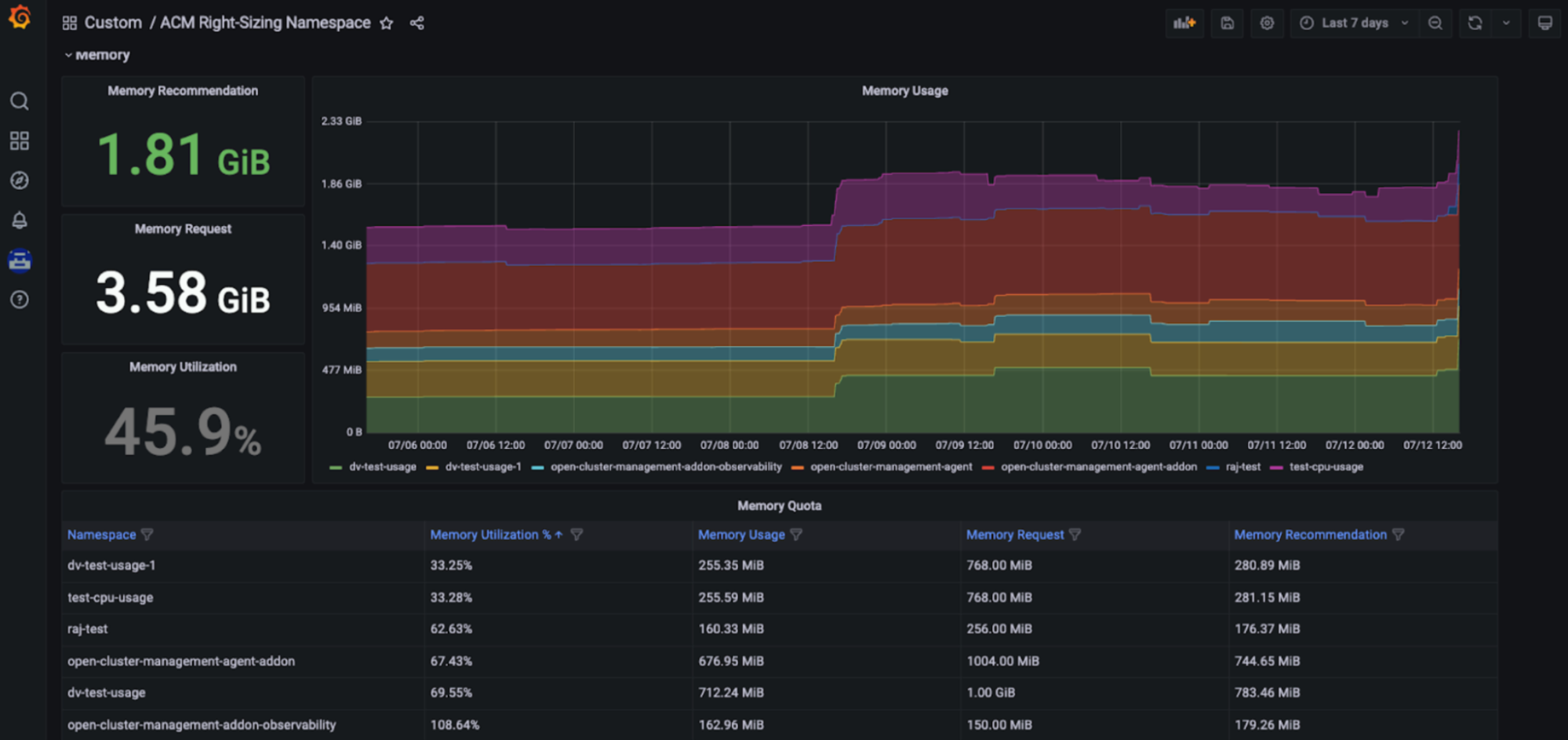
How to set it up
For more details on prerequisites and installation steps, take a look at our dedicated blog. The following GitHub repo can also be consulted. As we work towards a technology preview release, we are also evaluating providing recommendations at different levels. Unlike the Insights Cost Management Resource optimization feature (see below) RHACM right sizing is a solution that does not require sharing analytics data with Red Hat.
Resource optimization for OpenShift using Red Hat Insights cost management
Definition
Red Hat Insights cost management is our SaaS solution providing a single pane of glass for all your cloud and OpenShift spending, including on-premise.
Resource Optimization for OpenShift, part of Red Hat Insights cost management, has recently reached general availability. The goal of the resource optimization feature in Red Hat Insights is to provide development teams with specific, actionable, CPU and memory recommendations. This feature is powered by the Kruize open source project.
Benefits
Resource optimization for OpenShift provides developers with container-level recommendations, including containers, deployments, deploymentconfigs, statefulsets and replicasets.
Two sets of recommendations are generated:
- Cost recommendations. Look at these recommendations when you want to save money, or to maximize the usage of your clusters by adjusting the namespace quotas, node sizes or number of nodes
- Performance recommendations. Check these recommendations when your top priority is making your applications as performant as hardware can make them
Currently, both types of recommendations are generated in three time frames: based on 24-hours of observation, based on 7 days of observation and based on 15 days of observation.
Resource optimization for OpenShift recommendations generated by Red Hat Insights cost management can help you to save money and make your application perform best, and you can see these recommendations in context, along with the monetary cost of the workload.
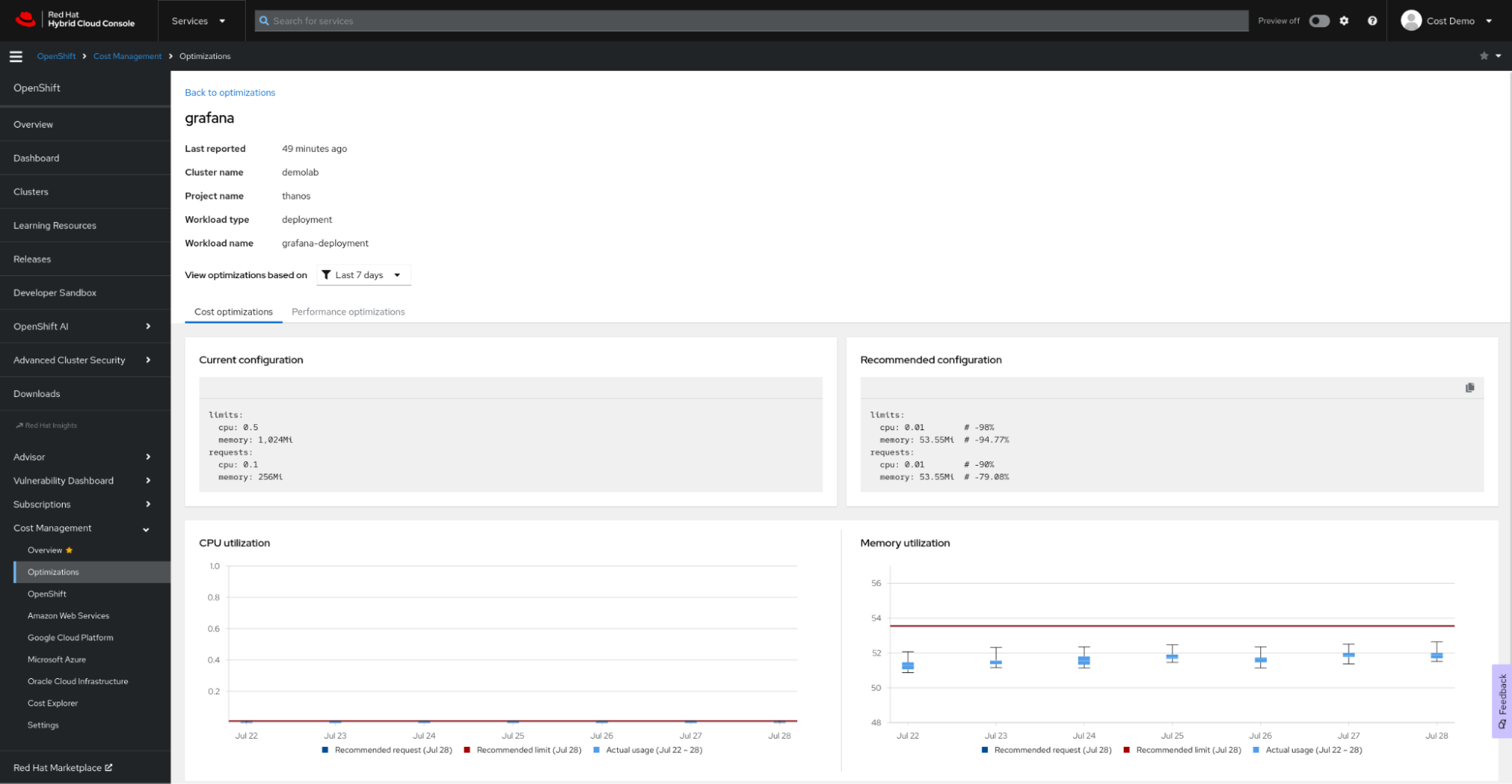
How to set it up
The resource optimization for OpenShift recommendations are one more feature of Red Hat Insights cost management. Follow the Red Hat Insights cost management cheat sheet to set it up, and use our rich Cost Management API to create your own dashboard in your preferred business intelligence or visualization tool, such as Microsoft Excel, Power BI or Grafana. There’s no need for complex configuration or allocating expensive resources for processing: the Cost Management Metrics Operator will submit your usage data to the Red Hat Hybrid Cloud Console for analysis and generate the cost and resource insights for you (if your clusters are not connected to the Internet, check our disconnected mode documentation).
Sugli autori


Vanessa is a Senior Product Manager in the Observability group at Red Hat, focusing on both OpenShift Analytics and Observability UI. She is particularly interested in turning observability signals into answers. She loves to combine her passions: data and languages.

Pau Garcia Quiles joined Red Hat in 2021 as Principal Product Manager. He has 20 years of experience in IT in various roles, both as a vendor and as a customer, systems administrator, software developer and project manager. He has been involved in open source for more than 15 years, most notably as a Debian maintainer, KDE developer and Uyuni developer.
Altri risultati simili a questo
Ricerca per canale

Automazione
Novità sull'automazione IT di tecnologie, team e ambienti

Intelligenza artificiale
Aggiornamenti sulle piattaforme che consentono alle aziende di eseguire carichi di lavoro IA ovunque

Hybrid cloud open source
Scopri come affrontare il futuro in modo più agile grazie al cloud ibrido

Sicurezza
Le ultime novità sulle nostre soluzioni per ridurre i rischi nelle tecnologie e negli ambienti

Edge computing
Aggiornamenti sulle piattaforme che semplificano l'operatività edge

Infrastruttura
Le ultime novità sulla piattaforma Linux aziendale leader a livello mondiale

Applicazioni
Approfondimenti sulle nostre soluzioni alle sfide applicative più difficili

Serie originali
Raccontiamo le interessanti storie di leader e creatori di tecnologie pensate per le aziende
Prodotti
- Red Hat Enterprise Linux
- Red Hat OpenShift
- Red Hat Ansible Automation Platform
- Servizi cloud
- Scopri tutti i prodotti
Strumenti
- Formazione e certificazioni
- Il mio account
- Supporto clienti
- Risorse per sviluppatori
- Trova un partner
- Red Hat Ecosystem Catalog
- Calcola il valore delle soluzioni Red Hat
- Documentazione
Prova, acquista, vendi
Comunica
- Contatta l'ufficio vendite
- Contatta l'assistenza clienti
- Contatta un esperto della formazione
- Social media
Informazioni su Red Hat
Red Hat è leader mondiale nella fornitura di soluzioni open source per le aziende, tra cui Linux, Kubernetes, container e soluzioni cloud. Le nostre soluzioni open source, rese sicure per un uso aziendale, consentono di operare su più piattaforme e ambienti, dal datacenter centrale all'edge della rete.
Seleziona la tua lingua
Red Hat legal and privacy links
- Informazioni su Red Hat
- Opportunità di lavoro
- Eventi
- Sedi
- Contattaci
- Blog di Red Hat
- Diversità, equità e inclusione
- Cool Stuff Store
- Red Hat Summit