New generative AI (gen AI) training results were recently released by MLCommons in MLPerf Training v4.0. Red Hat, in collaboration with Supermicro, published outstanding MLPerf v4.0 Training results for fine-tuning of large language model (LLM) llama-2-70b with LoRA.
LoRA (Low-Rank Adaptation of LLMs) is a cost-saving parameter-efficient fine tuning method that can save many hours of training time and reduce compute requirements. LoRA allows you to fine tune a large model for your specific use case while updating only a small subset of parameters. Red Hat’s llama2-70b with LoRA submission on Supermicro hardware demonstrates the delivery of better performance, within 3.5% to 8.6% of submissions on similar hardware, while providing an improved developer, user and DevOps experience.
LLM fine tuning is becoming a key enterprise workload as companies incorporate AI technology into their businesses. As enterprises begin training models for their specific business needs, they discover the power and cost savings of fine tuning an existing model rather than training a new model from scratch. In MLPerf v4.0, a new benchmark, llama-2-70b with LoRA, was introduced to enable companies to compare fine tuning performance across different architectures and software stacks.
Red Hat and Supermicro’s submission to the closed division of MLPerf training v4.0 demonstrates the power of using Red Hat Enterprise Linux (RHEL) 9.4 to run these benchmarks. The closed division does not allow competing companies to change the algorithm or the math in the model, allowing for fair comparisons between various vendors' hardware and software stacks. All code submissions for MLPerf Training v4.0 are here.
The Supermicro GPU A+ Server, the AS-8125GS-TNHR-1, has flexible GPU support and configuration options: with active and passive GPUs, and dual-root or single-root configurations for up to 10 double-width, full-length GPUs. Furthermore, the dual-root configuration features directly attached eight GPUs without PLX switches to achieve the lowest latency possible and improve performance, which is hugely beneficial for demanding workloads.
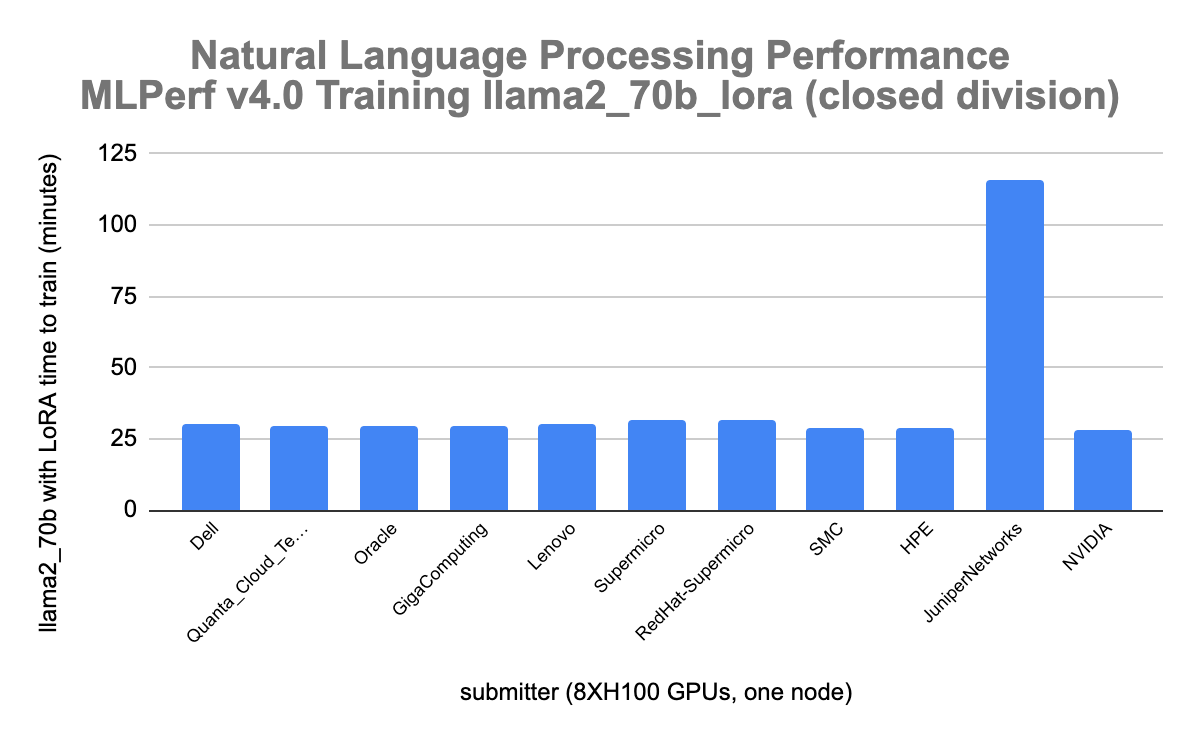
The graph below shows the Red Hat - Supermicro natural language processing fine tuning performance which was within 8.5 percent, 31.611 minutes (Red Hat - Supermicro) vs 29.022 minutes (HPE), of submissions on similar hardware (8xH100). The Nvidia EOS result was 11.53 faster (28.16 minutes). Juniper Networks was 114.39% slower than the Red Hat - Supermicro result.
Wrap up
Red Hat collaborated with Supermicro on this MLPerf Training 4.0 submission. These results for fine tuning of the LLM llama-2.70b with LoRA (quantized low-rank adaption) allow customers to compare solutions provided by hardware manufacturers and software vendors. As shown in the graph above, Red Hat software stack with Supermicro hardware and 8XH100 Nvidia GPUs provides similar performance to the other leading competitors in this round of MLPerf Training v4.0.
These results were obtained on RHEL 9.4. Check out Red Hat Enterprise Linux AI (RHEL AI) and the RHEL AI developer preview.
저자 소개

Diane Feddema is a Principal Software Engineer at Red Hat Inc in the Performance and Scale Team with a focus on AI/ML applications. She has submitted official results in multiple rounds of MLCommons MLPerf Inference and Training, dating back to the initial MLPerf rounds. Diane Leads performance analysis and visualization for MLPerf benchmark submissions and collaborates with Red Hat Hardware Partners in creating joint MLPerf benchmark submissions.
Diane has a BS and MS in Computer Science and is presently co-chair of the Best Practices group of the MLPerf consortium.

Nikola Nikolov is AI/HPC solutions engineer from Supermicro. Nikola received PhD in Nuclear Physics from the University of Knoxville, Tennessee focused on large-scale HPC computations in Nuclear Astrophysics at Oak Ridge National Laboratory under National Nuclear Security Administration (NNSA) Stewardship grant.
Before joining the industry, he spent last years in academics designing experiments with CERN Isolde collaboration and Cosmic Neutrino Detection with Los Alamos National Laboratory.
Prior to Supermicro, Nikola worked at KLA+ Inc. (former KLA-Tencor) as Big Data and ML developer in semiconductor industry. He designed HBase, Big-Table, and Data Lake infrastructures for Anomaly Detection and Failure Predictive analysis of semiconductor equipment. These Big-Data systems have been implemented successfully by major chip manufacturing companies like TSMC, Samsung, and SK Hynix.
Nikola has published both Peer-Reviewed academic articles in top scientific journals like Physical Review Letters and Nature, as well as engineering papers in Big Data management.
In the last 8 years he have focused mainly on public and hybrid cloud solutions with AWS and Google Cloud Platform. In Supermciro, Nikola works mostly into designing cutting edge AI/HPC infrastructure solutions as well as validating AI/HPC systems via MLPerf and HPC benchmarking.
유사한 검색 결과
Why the future of AI depends on a portable, open PyTorch ecosystem
Scaling Earth and space AI models with Red Hat AI Inference Server and Red Hat OpenShift AI
Technically Speaking | Build a production-ready AI toolbox
Technically Speaking | Platform engineering for AI agents
채널별 검색

오토메이션
기술, 팀, 인프라를 위한 IT 자동화 최신 동향

인공지능
고객이 어디서나 AI 워크로드를 실행할 수 있도록 지원하는 플랫폼 업데이트

오픈 하이브리드 클라우드
하이브리드 클라우드로 더욱 유연한 미래를 구축하는 방법을 알아보세요

보안
환경과 기술 전반에 걸쳐 리스크를 감소하는 방법에 대한 최신 정보

엣지 컴퓨팅
엣지에서의 운영을 단순화하는 플랫폼 업데이트

인프라
세계적으로 인정받은 기업용 Linux 플랫폼에 대한 최신 정보

애플리케이션
복잡한 애플리케이션에 대한 솔루션 더 보기
가상화
온프레미스와 클라우드 환경에서 워크로드를 유연하게 운영하기 위한 엔터프라이즈 가상화의 미래