
In this blog, we want to outline the behavior of HPA based on memory using a simple Quarkus application.
Overview
The Horizontal Pod Autoscaler based on memory automatically scales the number of pods in a replication controller, deployment, replica set, or stateful set based on observed memory utilization. For more information, please visit here.
HPA in Openshift is implemented using three steps:
- Grab the resource metric : runtime -> cAdvisor -> kubelet-> Prometheus -> Prometheus adapter -> HPA
- Calculate the desired number of replicas based on the memory consumption:
desiredReplicas = ceil[currentReplicas * ( currentMetricValue / desiredMetricValue )]
For example, if the current metric value is 200MB and the desired value is 100MB, the number of replicas will be doubled, since 200.0 / 100.0 = 2.0 - Scale based on desired Replicas count

It's so easy to create HPA via the OpenShift console. Just login as Kubeadmin. Go to workload and click Horizontal Pod Autoscaler and create:

Use Case for HPA Based on Memory
The HPA memory-based scaling is good for when:
- You have incoming tasks that can be distributed over a number of worker nodes ( for example, HTTP connects work items).
- Adding more workers reduces the memory-burden on other workers
Use Case for Stateless Application
The below YAML file describes that if memory percentage is >=60% then spin up pods based on desire Replicas count between 2 to 10 pods:
Let’s say how we set the HAP- based memory use in the OpenShift cluster here:
minReplicas: 2
maxReplicas: 10
targetAverageUtilization: 60
Assumptions for below use case: Memory use percentage increases 30% for every additional 100 requests. The load balancer balances the traffic to each pod as the below example indicates:
100 request = 30% memory utilization , 300 request = 90% memory utilization
Before we get into the use case, I want to make sure we all understand the concept of request and limit in OpenShift.
When you specify the resource request for containers in a pod, the scheduler uses this information to decide which node to place the pod on. When you specify a resource limit for a container, the kubelet enforces those limits so that the running container is not allowed to use more of that resource than the limit you set. The kubelet also reserves at least the request amount of that system resource specifically for that container to use.
The HPA based on memory scale based on request value example targetAverageUtilozation:60 means scale when memory use is 60% of the requested value, as shown in Figure 1:

Figure 1: Request and Limit
When the app(MyAPP) is initially deployed, it receives 200 requests that are equally distributed to replica pods (refer to YAML). Based on our assumptions above, 200 requests will yield memory use of 30% in each pod, as shown in Figure 2:
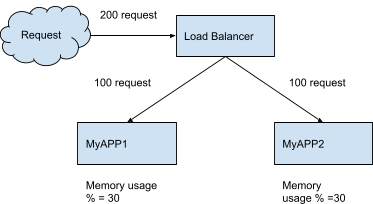
Figure 2: Stateless Application
desiredReplicas= 2
currentMetricValue = 30
desiredMetricValue = 60
After initial deployment and due to the popularity of the app, application traffic increases to 600 requests. The load balancer will try to balance the traffic equally to all pods, which will result in 300 requests to each pod, and average memory use will increase to 90%. This is more than the desired memory use of 60%, so HPA will scale 4 new pods {desiredReplicas = ceil [currentReplicas * ( currentMetricValue / desiredMetricValue )] , shown in Figure 3:

Figure 3: Scaling Stateless Applications
desiredReplicas= 6
currentMetricValue = 90
desiredMetricValue = 60
Example: How to Scale Quarkus Applications Based on Memory Use
Step 1: Create a new Quarkus project
We’ll use a Maven plug-in to scaffold a new project with the following command:
$ mvn io.quarkus:quarkus-maven-plugin:1.11.1.Final:create \
-DprojectGroupId=org.acme \
-DprojectArtifactId=quarkus-hpa \
-DprojectVersion=1.0.0-SNAPSHOT \
-DclassName="org.acme.GreeterResource" \
-Dextensions="openshift"
This command generates a quarkus-hpa directory that includes a new Quarkus project. When you open the GreeterResource.java class file in src/main/java/org/acme, you will see a simple RESTful API implementation in the hello() method. Append the following new fill() method to put dummy data(i.e 1MB) into the memory of the Quarkus runtime continuously:
@GET
@Path("fill/{index}")
@Produces(MediaType.TEXT_PLAIN)
public String fill(@PathParam("index") String index) throws Exception {
HashMap<String, String> mem = new HashMap<String, String>();
char[] chars = new char[2 * 1024 * 1024];
Arrays.fill(chars, 'f');
mem.put(Math.random() + "", new String(chars));
System.out.println("Added " + index + "MB");
return "Added " + index + "MB \n";
}
You can then use the OpenShift extension and Maven plug-in to deploy the application to your remote OpenShift cluster. Append the following configurations to your Quarkus project's application.properties file:
# OpenShift extension configration
quarkus.container-image.build=true
quarkus.kubernetes-client.trust-certs=true
quarkus.kubernetes.deployment-target=openshift
quarkus.kubernetes.deploy=true
quarkus.openshift.expose=true
# Container Resources Management
quarkus.openshift.resources.requests.memory=128Mi
quarkus.openshift.resources.requests.cpu=250m
quarkus.openshift.resources.limits.memory=256Mi
quarkus.openshift.resources.limits.cpu=1000m
Note: We will set request.memory lower than the usual memory resource so HPA will be able to scale the pod (Quarkus app) up in a short time (up to 2 mins).
Step 2: Build and deploy the Quarkus application
To log in to the OpenShift cluster, you have to install the oc command-line interface and use the oc login. Installation options for the CLI will vary depending on your operating system.
Assuming you have oc installed, execute the following command in your Quarkus project home directory:
$ oc new-project hpa-quarkus-demo
$ mvn clean package -DskipTests
This command creates a new project in the remote OpenShift cluster. The Quarks application will be packaged and deployed to OpenShift. The output should end with BUILD SUCCESS.
Using the oc annotate command, add the load-balancing algorithm to the route. This roundrobin annotation will rebalance the network traffic to all running pods automatically:
$ oc annotate route quarkus-hpa haproxy.router.openshift.io/balance=roundrobin
Step 3: Create a horizontal pod autoscaler object for memory use
Now, let’s go to the Developer console in the OpenShift cluster and then navigate the Topology view. You will see that your Quarkus application has been deployed. Click on Actions to add the Horizontal Pod Autoscaler, as shown in Figure 6:

Figure 6: The Quarkus application in the Topology view.
You should see the configuration page, as shown in Figure 2. Then, set 10 in Maximum Pods and 60 in Memory Utilization. Click on the Save button, as shown in Figure 7:
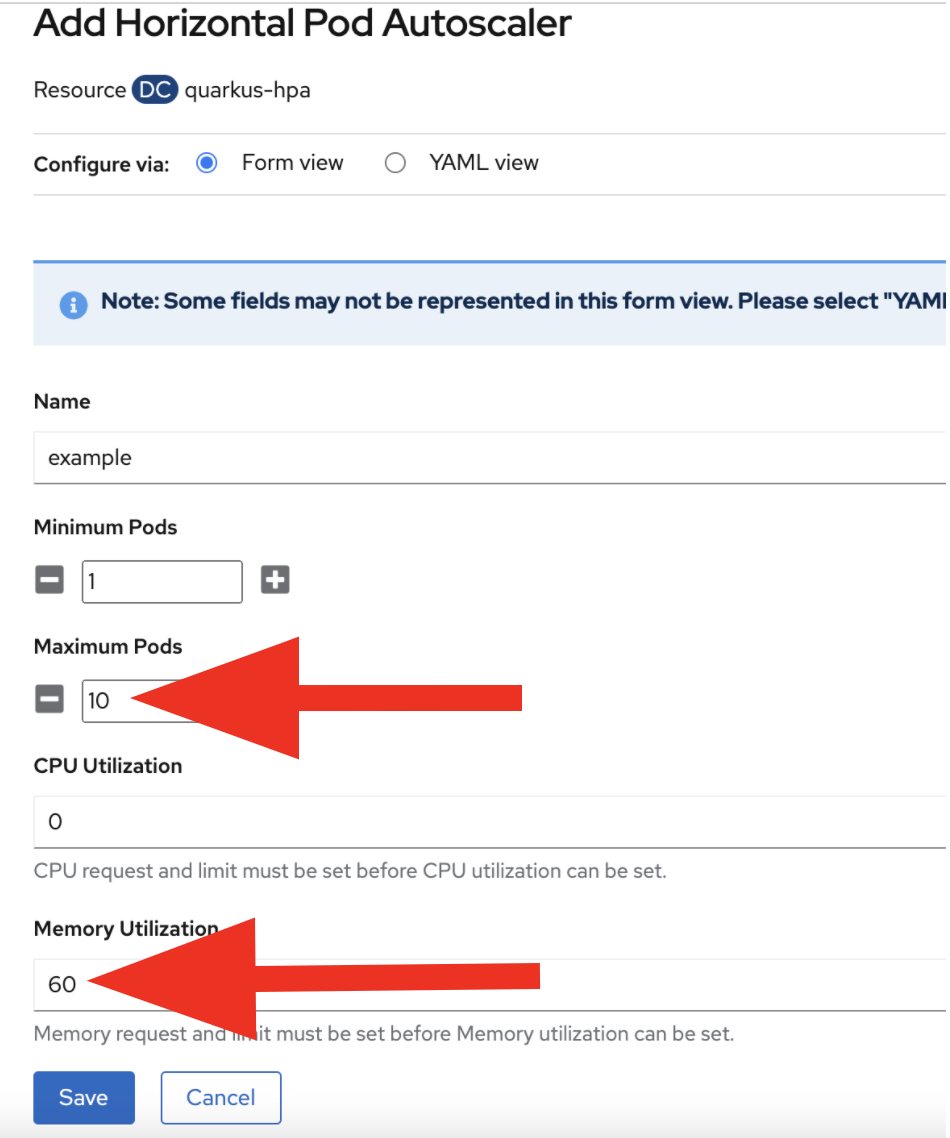
Figure 7: Add Horizontal Pod Autoscaler
Next, return to the local environment, then execute the following curl command to invoke the fill() method:
$ for ((i = 1; i <= 100; i++ )); do curl http://YOUR_APP_ROUTE_URL/hello/fill/$i ; sleep 2 ; done
Great! Go back to the Topology view, then you will see that the Quarkus application is starting to scale out(i.e. 3 pods). It usually takes minutes to scale out, as shown in Figure 8:

Figure 8: Scaling Pods
When you click on View logs, you will see how OpenShift rebalances the network traffic to multiple Quarkus pods automatically, as shown in Figure 9:

Figure 9: Rebalancing Network Traffic
When you navigate Administrator > Monitoring > Dashboards, you can open the Grafana dashboard to keep tracking the request memory use of the Quarkus pods as well as the number of scaling pods along with Prometheus metrics, as shown in Figure 10.

Figure 10: Grafana Dashboard
The increased pods will be decreased to one pod once the average memory use goes down below 60 percent. It usually takes longer than the increased time because HPA makes sure that the pod is really not needed so that shortens periods of inactivity.
Here is the video link to the Quarkus application demo with HPA.
Caveats
Most applications use a dynamic memory management library for resource allocation. Such applications may not ever release unused memory back to the operating system until the application is finished. For example, consider a C program using the glibc library functions malloc() and free() to acquire and release memory for the application's use. When a malloc() call is made, glibc will acquire a block of memory from the operating system for use by the program. It will then divide up the block and return pieces of memory to callers of malloc(). However, when the application calls free(), the glibc library may not be able to release the memory back to the operating system, because a part of it may still be in use by the application. Over time, memory fragmentation may occur as a result of many malloc() and free() calls. Due to this fragmentation, the application may be using very little memory from the perspective of the dynamic memory management library while actually holding a much higher amount of memory from the operating system. This "high watermark" usage pattern means that HPA memory-based scaling may be less effective for these types of applications where the metrics show a high amount of usage for an application that once used a lot of memory but has since released it.
Conclusion
HPA based on memory is a great tool to prevent pods from being killed by Out of Memory (OOM ). It is important to note that HPA based on memory is not a silver bullet to solve your application scaling problem since the benefit of HPA memory-based scaling is highly dependent on the nature of your application.
{{cta('1ba92822-e866-48f0-8a92-ade9f0c3b6ca','justifycenter')}}
저자 소개

채널별 검색

오토메이션
기술, 팀, 인프라를 위한 IT 자동화 최신 동향

인공지능
고객이 어디서나 AI 워크로드를 실행할 수 있도록 지원하는 플랫폼 업데이트

오픈 하이브리드 클라우드
하이브리드 클라우드로 더욱 유연한 미래를 구축하는 방법을 알아보세요

보안
환경과 기술 전반에 걸쳐 리스크를 감소하는 방법에 대한 최신 정보

엣지 컴퓨팅
엣지에서의 운영을 단순화하는 플랫폼 업데이트

인프라
세계적으로 인정받은 기업용 Linux 플랫폼에 대한 최신 정보

애플리케이션
복잡한 애플리케이션에 대한 솔루션 더 보기

오리지널 쇼
엔터프라이즈 기술 분야의 제작자와 리더가 전하는 흥미로운 스토리
제품
- Red Hat Enterprise Linux
- Red Hat OpenShift Enterprise
- Red Hat Ansible Automation Platform
- 클라우드 서비스
- 모든 제품 보기
툴
체험, 구매 & 영업
커뮤니케이션
Red Hat 소개
Red Hat은 Linux, 클라우드, 컨테이너, 쿠버네티스 등을 포함한 글로벌 엔터프라이즈 오픈소스 솔루션 공급업체입니다. Red Hat은 코어 데이터센터에서 네트워크 엣지에 이르기까지 다양한 플랫폼과 환경에서 기업의 업무 편의성을 높여 주는 강화된 기능의 솔루션을 제공합니다.