
Having OpenShift (or Kubernetes) cluster nodes able to learn routes via BGP is a popular ask.
In simple scenarios where the cluster nodes have one single interface (and default gateway), everything is straightforward because there are no exceptions to the default route.
However, when you have nodes with multiple interfaces (such as multiple VLANs or bonds) or multiple physical interfaces, you might face the following scenarios:
- Dynamic routing: The network fabric around the cluster is complex, and some services are reachable via different interfaces (for example, services of type LoadBalancer announced by other Kubernetes clusters living on different networks).
- Traffic segregation: Different external services are reachable via different node interfaces because of traffic segregation requirements. The traffic directed to a given CIDR must be sent via a specific network interface (typically, a VLAN corresponding to a VRF in the router). Setting static routes simply does not scale.
- Multiple Gateways: The users want to achieve high availability for the egress traffic, having multiple DCGWs in an active-active configuration.
- Asymmetric return path: The nodes do not have a route to reach the client, so the return traffic goes via the default gateway.
The node must know the path to the client to send the return traffic to a given request via the correct interface.
Using MetalLB to receive routes
You can resolve the problems described above by allowing external routers to push routes to the node's host networking space via BGP.
MetalLB leverages the FRR stack to advertise Kubernetes services of type LoadBalancer via BGP.
Despite having an FRR instance running on each node of the cluster, this instance can't be used for purposes beyond the very specific MetalLB use case.
Allowing the FRR instance coming with MetalLB to configure the node routes
MetalLB translates its configuration described with Kubernetes CRDs to a raw FRR configuration. MetalLB provides a raw configuration that can be appended to the one rendered by MetalLB.
The FRR instance running inside MetalLB does not allow incoming routes to be propagated because of a generated rule like:
route-map 192.168.1.5-in deny 20
The rule is named after the IP of the neighbor configured in the BGPPeer instance.
Using a custom config to remove the deny rule
To enable FRR to receive the routes via BGP, a ConfigMap must be configured with one line per configured peer, such as the one below:
apiVersion: v1
kind: ConfigMap
metadata:
namespace: metallb-system
name: bgpextras
data:
extras: |
route-map 192.168.1.5-in permit 20
route-map fc00:f853:ccd:e793::5-in permit 20
This will override the deny rule put in place by MetalLB, and the FRR instance will be able to receive the routes.
Filtering the incoming prefixes
The only extra piece of allowed FRR configuration is:
- Custom prefix-lists not overlapping with the ones generated by MetalLB (with a custom name, for example, `filtered`).
- A route map per router, under the form "route-map xxxx-in permit 20" (with the same 20 index to override the one MetalLB puts in place).
- A match rule for the route map, matching the aforementioned prefix list.
Below is an example of the configuration:
ip prefix-list filtered permit 172.16.1.0/24 le 32
ip prefix-list filtered permit 172.16.2.0/24 le 32
route-map xxxx-in permit 20
match ipv4 address prefix-list filtered
Availability
This particular configuration is available in the upstream version of MetalLB https://metallb.universe.tf/ and in OpenShift 4.12+ as Tech Preview.
Known issues
Because of this FRR bug, the configuration must be in place before MetalLB establishes a session. This means that the ConfigMap must be created before the BGPPeer CRDs are, or that the speaker pods must be restarted if the ConfigMap is created after the session was already established. The bug is not present in 4.14, where a more recent version of FRR is used.
What's next
This first implementation permits you to unblock users where dynamic route learning for the cluster's nodes is required. However, MetalLB's purpose is not really receiving routes. On the other hand, running multiple FRR instances on the same node has other challenges and wastes resources.
Because of this, we are re-architecting MetalLB so that FRR will run as a separate instance with its own API that can be contributed by MetalLB, the user, or other controllers.
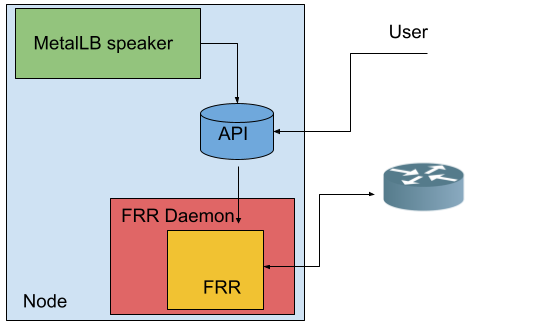
Having a single FRR instance on each node is the best way to optimize both node and router resources, as the various configurations will be able to share the same BGP/BFD session.
For more details, the upstream design proposal is available here and is currently being worked on.
저자 소개

채널별 검색

오토메이션
기술, 팀, 인프라를 위한 IT 자동화 최신 동향

인공지능
고객이 어디서나 AI 워크로드를 실행할 수 있도록 지원하는 플랫폼 업데이트

오픈 하이브리드 클라우드
하이브리드 클라우드로 더욱 유연한 미래를 구축하는 방법을 알아보세요

보안
환경과 기술 전반에 걸쳐 리스크를 감소하는 방법에 대한 최신 정보

엣지 컴퓨팅
엣지에서의 운영을 단순화하는 플랫폼 업데이트

인프라
세계적으로 인정받은 기업용 Linux 플랫폼에 대한 최신 정보

애플리케이션
복잡한 애플리케이션에 대한 솔루션 더 보기

오리지널 쇼
엔터프라이즈 기술 분야의 제작자와 리더가 전하는 흥미로운 스토리
제품
- Red Hat Enterprise Linux
- Red Hat OpenShift Enterprise
- Red Hat Ansible Automation Platform
- 클라우드 서비스
- 모든 제품 보기
툴
체험, 구매 & 영업
커뮤니케이션
Red Hat 소개
Red Hat은 Linux, 클라우드, 컨테이너, 쿠버네티스 등을 포함한 글로벌 엔터프라이즈 오픈소스 솔루션 공급업체입니다. Red Hat은 코어 데이터센터에서 네트워크 엣지에 이르기까지 다양한 플랫폼과 환경에서 기업의 업무 편의성을 높여 주는 강화된 기능의 솔루션을 제공합니다.