
Last year Tom Wilkie and I talked at KubeCon Barcelona about the future of Observability. One of our predictions was that correlation across signals would become more and more common. In this post I will demonstrate how we are leveraging those correlations every day within the production systems that the Red Hat Observability group operates, and how that helps us identify the right problems faster.
Our Stack
We use Prometheus, an open source monitoring for alerting on time-series. Our infrastructure runs on OpenShift, Red Hat’s distribution of Kubernetes. Kubernetes (and thus OpenShift) provides us with a simple API to read plaintext logs from our containers. To visualize and analyze latencies between and within individual parts of the infrastructure we use an open source distributed tracing tool Jaeger. And last but not least each of our processes exposes a pprof (the built-in profiles in the go runtime, but also available for rust, python, nodejs and java) endpoint for profiling, and we use Conprof to continuously collect profiles over time.
Debugging Time!
We recently rolled out a new version of Thanos in our infrastructure, and Prometheus quickly alerted us, about high latency.

Prometheus graph showing a steady increase in latency after a deployment.
We took advantage of the tooling we had at hand, to debug the problem, rather than rolling back to the previous version. This helped us pinpoint the exact problem and resolved the situation. This kind of situation could happen on any project, even in house product systems, where similar workflows could be applied.
We checked our slow query logs, of our component that first accepts the requests for queries, which immediately revealed a trace ID to us. Any query with latency higher than 5 seconds is written to the slow query log.
ts=2020-06-04T10:59:57.6170538Z component=query-reader msg="request finished" trace-id=23957fb8181c10d4
Log line from a slow query log, showing a trace ID from a slow query.
With this Trace ID, we could immediately pull up a trace in Jaeger of a problematic query.
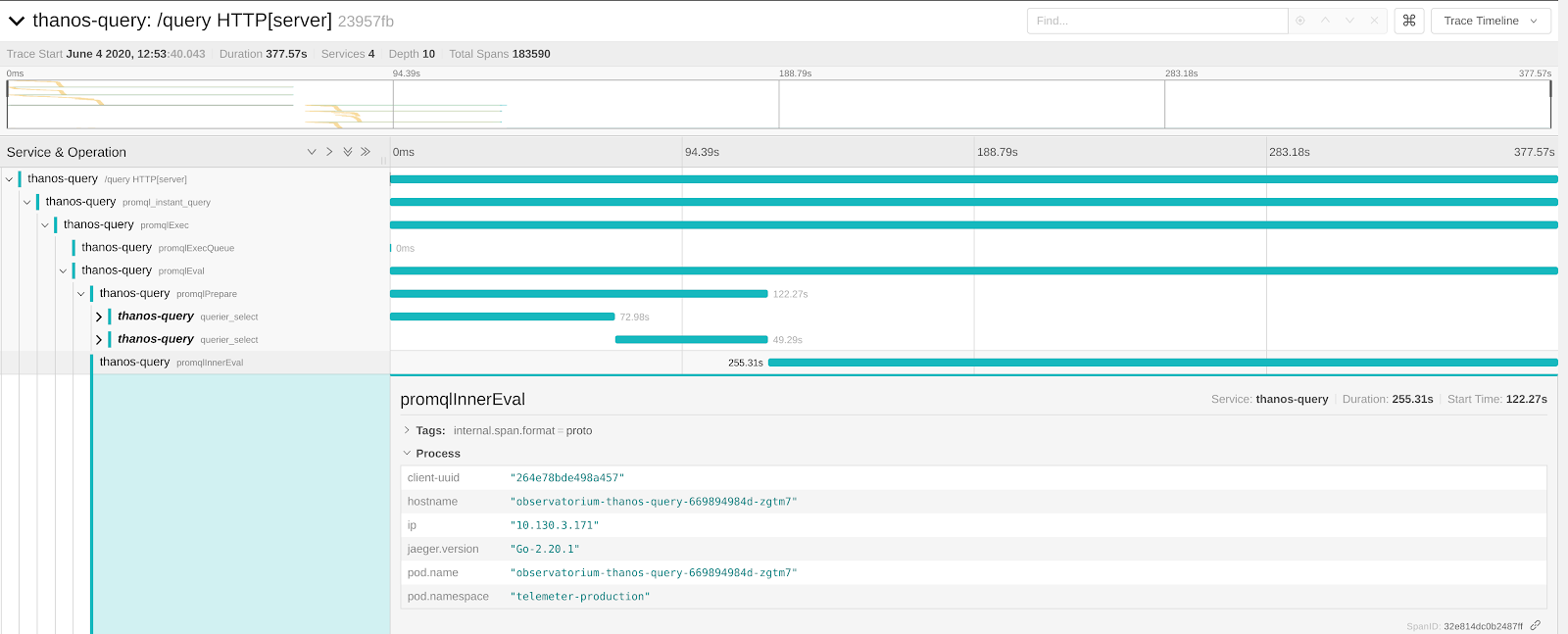
Jaeger’s Trace detail page with detailed information expanded about the process, which created the span.
This was interesting because we could clearly tell that the overwhelming majority of the query was spent in the query engine, and even more importantly, we knew exactly at what time, and which process was crunching away.
We in addition to metrics, logs, and tracing continuously profile all processes we run with Conprof. With the information available from the trace, we could immediately query Conprof.

Conprof’s query interface showing many samples over time being collected.
And pull up a CPU profile from exactly that point in time, and lo and behold, we knew where the majority of CPU time was spent.

Graph representation of a CPU profile taken from Thanos, showing a clear dominant path.
Discovering this allowed us to cut ⅓ in query latency in Thanos.
Correlations Give Superpowers!
Only the combination of tools and correlating the information made this possible. The entire troubleshooting process took 2 minutes to find, for something that used to take up to days of searching for the needle in the haystack. While it is a bit of upfront effort to instrument applications with metrics, logging, and tracing, as this post hopefully shows, this effort pays off exponentially.
Ever since we have discovered this workflow it has been a powerful tool and has helped us uncover a number of performance improvements much more quickly than we used to.
Using these tools in this way almost felt like a superpower, it felt like cheating, because it was so easy. There is still a lot of work that can be done to integrate these signals more tightly, improve the user experience and automate the correlation aspects more, but what Tom and I predicted in the Keynote, is slowly becoming reality!
저자 소개

채널별 검색

오토메이션
기술, 팀, 인프라를 위한 IT 자동화 최신 동향

인공지능
고객이 어디서나 AI 워크로드를 실행할 수 있도록 지원하는 플랫폼 업데이트

오픈 하이브리드 클라우드
하이브리드 클라우드로 더욱 유연한 미래를 구축하는 방법을 알아보세요

보안
환경과 기술 전반에 걸쳐 리스크를 감소하는 방법에 대한 최신 정보

엣지 컴퓨팅
엣지에서의 운영을 단순화하는 플랫폼 업데이트

인프라
세계적으로 인정받은 기업용 Linux 플랫폼에 대한 최신 정보

애플리케이션
복잡한 애플리케이션에 대한 솔루션 더 보기

오리지널 쇼
엔터프라이즈 기술 분야의 제작자와 리더가 전하는 흥미로운 스토리
제품
- Red Hat Enterprise Linux
- Red Hat OpenShift Enterprise
- Red Hat Ansible Automation Platform
- 클라우드 서비스
- 모든 제품 보기
툴
체험, 구매 & 영업
커뮤니케이션
Red Hat 소개
Red Hat은 Linux, 클라우드, 컨테이너, 쿠버네티스 등을 포함한 글로벌 엔터프라이즈 오픈소스 솔루션 공급업체입니다. Red Hat은 코어 데이터센터에서 네트워크 엣지에 이르기까지 다양한 플랫폼과 환경에서 기업의 업무 편의성을 높여 주는 강화된 기능의 솔루션을 제공합니다.