
Many teams use branching strategies within a Git repository to isolate change. If used with a degree of coordination and structure, branches can create a level of control over development that eases understanding and manages the scope of change. However, if used badly, branches can create a chaotic environment that fragments work and leads to regressed fixes and poor control.
This article will show a simple branched development model and explain how the use of merges, driven by Git pull requests, can be used to control change while giving the visibility and control that enterprise organizations need.
The article identifies the different characteristics of application source code and the Kubernetes resources used to deploy an application. The pull request process described here is focussed on changes to the Kubernetes resources, and specifically, the management of change to deploy an updated application container image identified by an image tag.
Background information on the GitOps strategy and the use of capabilities provided by Red Hat OpenShift GitOps can be found in the prior articles in this series:
- GitOps Introduction
- GitOps Deployment and Image Management
- GitOps Continuous Delivery with OpenShift GitOps and Kustomize
What assets are we changing?
Multiple types of assets exist within a microservice-based application and the approach taken will differ slightly depending on which type of asset is being updated. The GitOps Introduction article describes a number of different Git repositories for source code, deployment resources, environment configuration and continuous integration (build) assets.
Source code management
Changes to the source code of a container-based application will result in a new container image being produced by a subsequent build process. Container images are stored in a container registry, for which a simple flat list of repository tags is available. Branching is not available for images in the container registry.
As shown at the top of Figure 1, the container image acts as an intermediary, decoupling the source code from the mechanisms used to deploy it. The source code content is developed utilizing a specific branching strategy, resulting in Git tags marking significant release points. From these points, builds are performed using OpenShift Pipelines (Tekton) and preferably, container images are produced with an image tag that includes the Git tag to aid traceability. The branching strategy employed for the source code content can be different from the branching strategy used for the deployment assets, which are described beneath the dotted line in Figure 1.
Branch strategies
The source code development process will result in a new container image with a new identification tag. In order to use a new container image in a deployment, the tag of the image must be put into an asset such as a Kubernetes resource like Deployment, Statefulset, etc. This process is explained in detail in the article Continuous Delivery with OpenShift GitOps and Kustomize. Deployment YAML resources are stored in a Git repository and are subject to branch-based development.
An example branching strategy is shown at the top of Figure 1. The source code follows a release strategy that uses cities for each release. Further sub-branches can be created for fixes or specific activities from the Monaco branch if necessary. Once the release has been completed, the Monaco branch is merged to main and retired. A new branch for subsequent development work is then created from the main branch.
The branch strategy for the deployment resources is shown in the lower half of Figure 1. Content reviews and merges are used to progress the changes made to the deployment resources from the fix-001 branch to the initiative-A branch and ultimately to the main branch. The fix-001 branch is used for short-term fixes to the content as a sub activity of the work for initiative A. The branch for initiative A should be retired when that work has been completed.
Short-term branches encourage good practices of merging content to release branches frequently and reduce the possibility of divergence of content.
The main branch of the deployment assets repository is monitored by an OpenShift GitOps (Argo CD) application such that new commits to that branch are immediately deployed to the OpenShift namespace.
The pull request process and associated controlling mechanisms presented in the remainder of this article are focussed purely on the Kubernetes resources used to deploy and run the application.
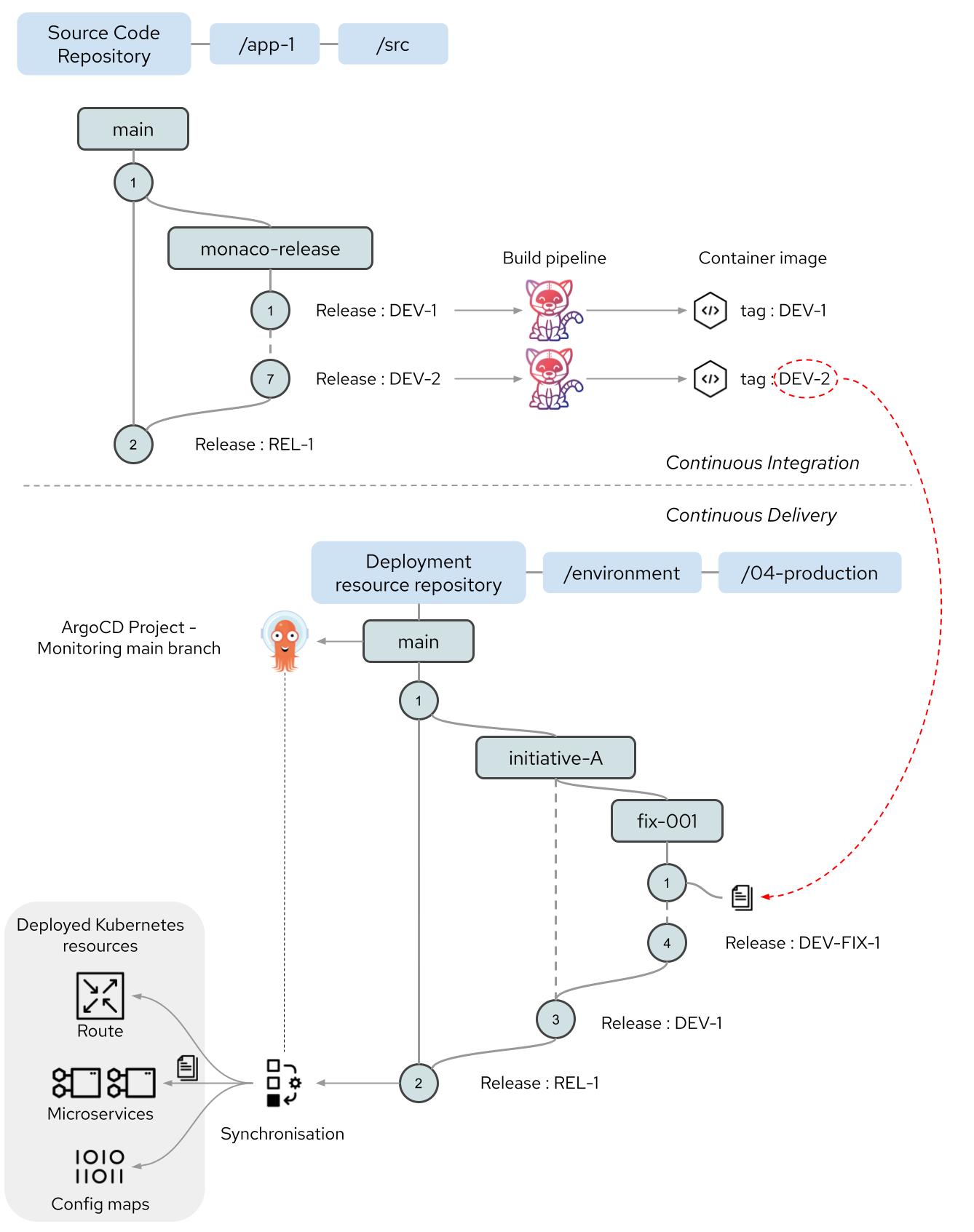
Figure 1: Branch strategies for assets under development
GitOps and branching
For any team embarking on a GitOps approach, the correct use of branches is fundamental so that changes are performed in isolation and to help make sure that change is introduced in a managed way. An example branch strategy is shown in Figure 2.
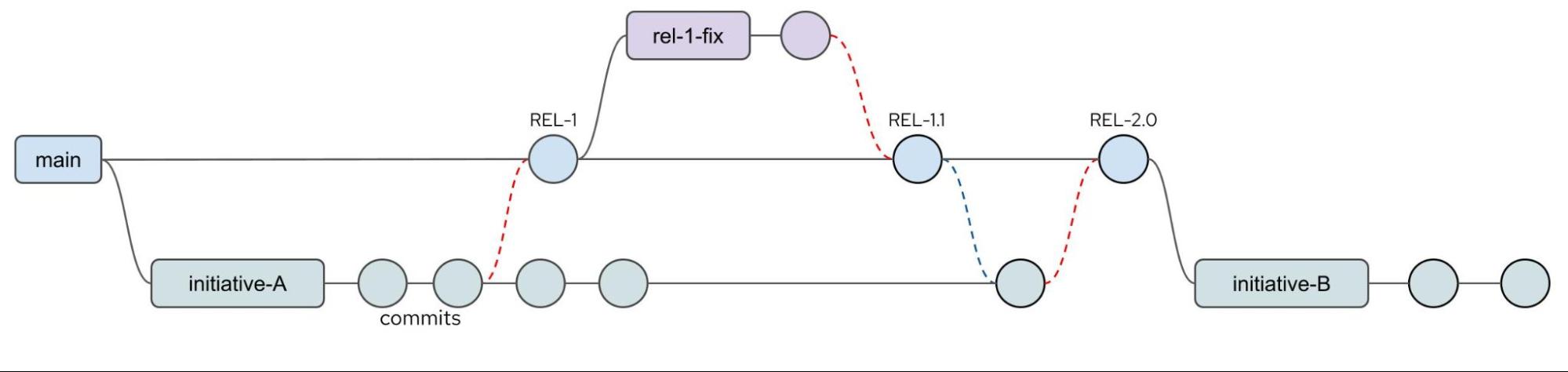
Figure 2: Example branch strategy
In Figure 2, four branches have been used. A main branch is used for the release of the content for production, and initiative branches are used to isolate development work. The red dotted line indicates a merge of work back to the main branch for a release, to which a label is attached. From the labeled release point REL-1, a short-term fix branch is created to isolate fix work from the development efforts. When the release 1 fix work has been completed, the changes are merged to the main branch for a fix release (REL-1.1) and those changes are also merged to the current development branch to help make sure the fix is not regressed later. Long-running branches are discouraged as it is often cleaner and safer to create new branches from the release branch (main) for specific activities.
In this example, the branches initiative-A and rel-1-fix are retired and no further changes are performed once the initiative is completed. Some teams choose to delete retired branches when they are no longer required.
The above example is just that – an example. There are a myriad of other ways that branching strategies can be defined and each will work fine as long as the team understands the process for creating branches, merging work from them for a release and deleting branches.
Managing and controlling merge operations
The red merge operations shown in Figure 2 are responsible for the delivery of new content to a specific branch. Since the target branch is monitored by an Argo CD project and the new commit will be deployed immediately, it is very important that the merge operation is well controlled.
Branch protection rules
GitHub has a capability called branch protection rules that can enforce certain behaviors and validations before merge operations are performed. To see the branch protection rules for a GitHub repository from the web user interface, go to the Settings menu for a repository, then select Branches. The branch protection rules will appear as in Figure 3.
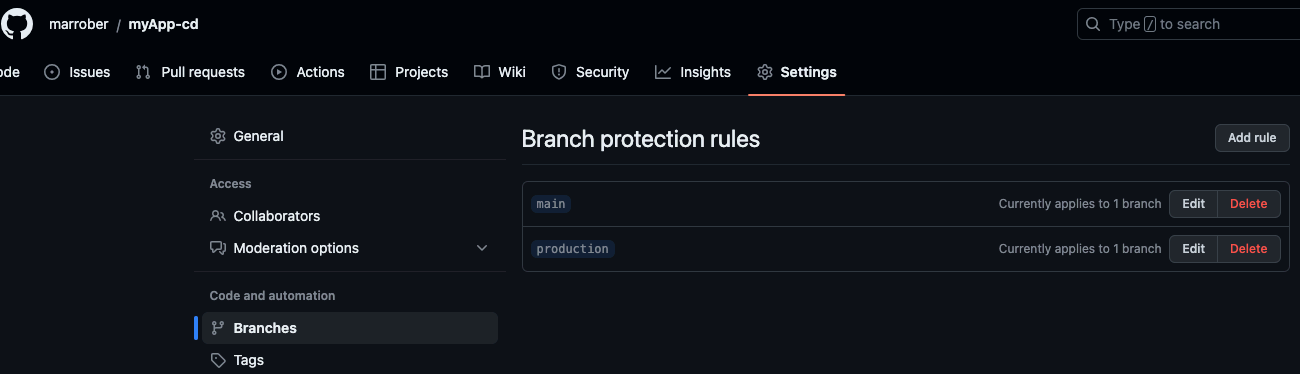
Figure 3: GitHub branch protection rules
The branch protection rules available in GitHub are summarized below. Alternative schemes may be available in other source code management solutions; consult the full documentation available on GitHub before implementing any such rules within your environment.
Require a pull request before merging
The only way to merge commits to the branch is through the use of a pull request. All changes can then be reviewed by the person processing the pull request. If you also require status checks, the person processing the pull request can be confident that the commits have passed a quality validation.
Require status checks to pass before merging
Status checks allow commits to be marked with a status of error, failure, pending or success. This enables teams to perform tests on the content of the commit during a continuous integration phase and to mark the commit with an appropriate status based on the results of such tests. Pull requests can require a status of success before the pull request can be actioned to merge content to the target branch. The use of this protection rule is explained later in this article.
Require conversation resolution before merging
Pull requests can have comments and conversations which are useful in reviewing the content. This rule makes sure that all conversations are resolved before the merge is allowed.
Require signed commits
Commits must have verified signatures.
Require linear history
A linear history preserves the order of change and can make reversing changes easier. Switching on this protection rule means that pull requests to be merged to the branch must use either a squash merge or a rebase merge. Both merge types prevent commits becoming entangled with other commits on the branch, which is why reversing changes is easier. Before enabling this rule, the repository must be configured to enable squash merging or rebase merging, and the team should be aware of which process to use.
- Squash merge: This merge process creates a single commit on the target branch. This can be useful to reduce the noise of lots of changes that individually contribute little to the overall result but that collectively form a useful change.
- Rebase merge: A rebase merge applies the changes on the target branch in the same order as they were created on the source branch. As shown in Figure 4, it does this by replaying the commits from the development branch onto the head commit of the main branch. However, a commit from the development branch, such as commit 3, may not be the exact same content on the main branch because it is being merged with other changes. For this reason, the code change is packaged into a new commit, which is marked as 3’ on the main branch.
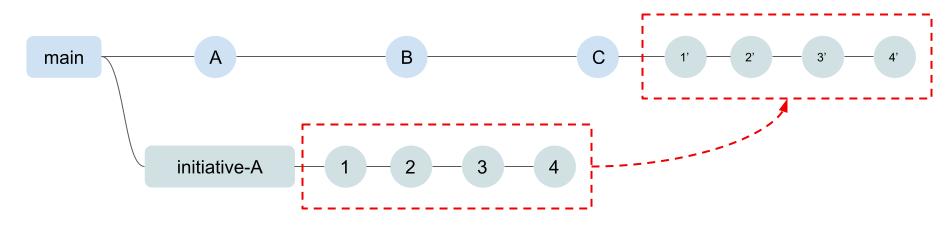
Figure 4: Rebase merge operation
Merges may result in the need to resolve conflicts in which the same lines of code or configuration are changed by a developer on both branches. For example, in the deployment resource shown in Figure 5, and with reference to the branch model in Figure 4, a user could change the number of replicas to 4 on the main branch (change C), while another user could change the number of replicas to 8 on the initiative-A branch (change 4). When the changes from Initiative-A are merged, the conflict for the number of replicas needs to be resolved.
Start main - version A initiative-A - version 1 | main - version C | initiative-A - version 4 | main - version 4’ |
| | | |
Figure 5: Merge conflict resolution
A strategy for avoiding merge conflicts is to limit the number of parallel changes as much as possible. When merge conflicts occur, it is important to understand the reason for each change and get consensus from the users involved before commiting a result.
Require deployments to succeed before merging
GitHub is able to manage a series of environments to which application deployments can be made using GitHub actions. This protection rule requires that deployments have been performed successfully to an environment before the merge can take place.
Lock branch
This makes the branch read-only, which blocks any new commits.
Do not allow bypassing the above settings
This setting blocks administrators from being able to override the above protection rules.
Additional gate processes
Branch protection rules are not the only way to control and validate content as part of a pull request process. GitHub actions can be used to perform specific analysis of code or other artifacts as part of the pull request. For example, it is possible to perform vulnerability scans of container images produced by the continuous integration process utilizing Red Hat Advanced Cluster Security for Kubernetes to help make sure that images are compliant with specific security policies. Other popular tools that can be used in this way include SonarQube for static analysis of code.
Ultimately, branch protection rules and GitHub actions are there to add value by catching issues with code and container images that may cause more expensive problems further down the software delivery pipeline. Identifying defects earlier will educate developers within the context of the changes they are committing and provide a smoother delivery of applications to production.
Creating a pull request
A pull request can be created using the web user interface for the GitHub repository, or it can be created using a command-line utility.
Creating a pull request from the GitHub web user interface
From the web user interface, select the repository and then select the pull request submenu. Hit the green button marked “New pull request” and then select the source and target branches. GitHub will then assess the merge process required for the pull request, which will either show “Able to merge”, in green text, or “Can’t automatically merge”, in red text. Either way, the pull request can be created, but there may be merge conflicts to resolve. In a GitOps approach, it is important to minimize the number of conflicts required to be resolved. Having a simple merge process helps make sure that there is no ambiguity over the resulting content on the target branch.
The middle section of Figure 6 shows the commits that are to be merged as part of the pull request. The text 7c5adf5 is a link to the commit details, and the <> symbol, to the right of 7c5adf5, is a link to enable a user to browse the code at the time of the commit.
The bottom section of Figure 6 shows the commit details. As stated previously, in a GitOps approach when the container image has changed, it is necessary to change the image tag reference in the deployment assets. This is indicated by the red dashed line in Figure 1. The person reviewing the pull request can see the scope of change within the commit very easily and it is clear, in Figure 6, that the only change is the image tag within the Kustomize file. The Kustomize process is explained in detail in a prior article in this series: GitOps Continuous Delivery with OpenShift GitOps and Kustomize.
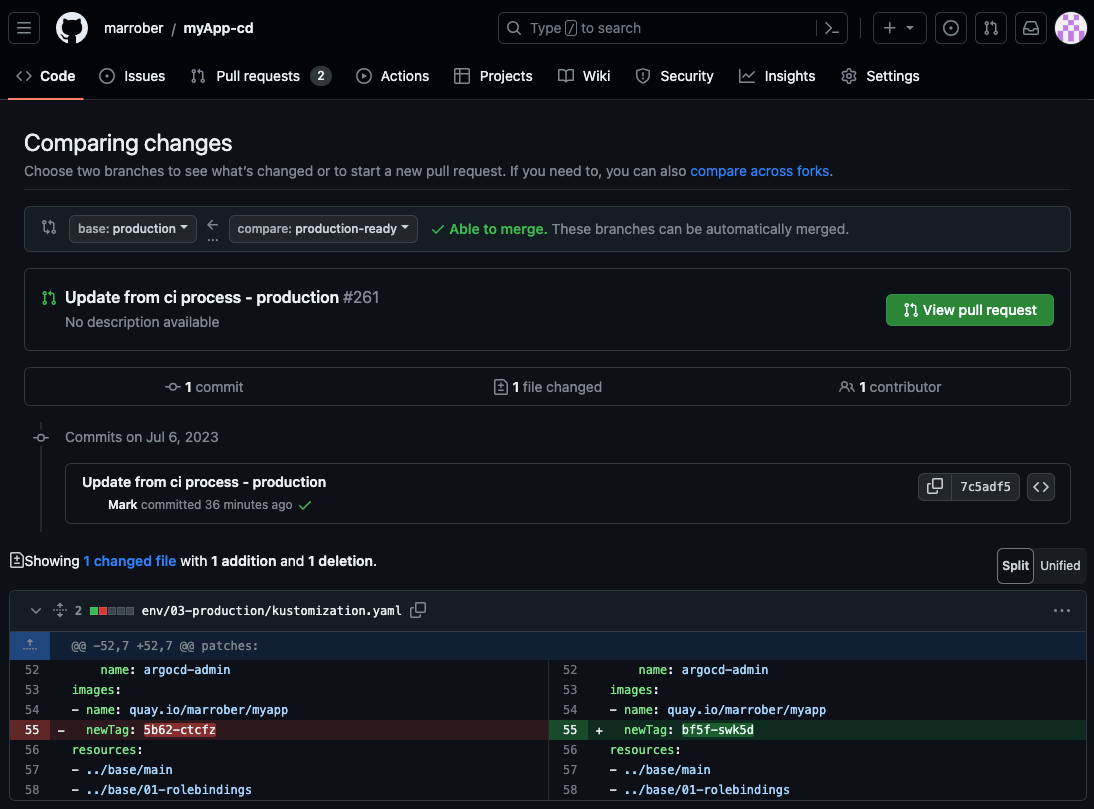
Figure 6: Pull request creation
After clicking the green “View pull request” button, the pull request is created and the user is presented with the summary of the pull request shown in Figure 7. The green circles with ticks indicate that the various branch protection rules have been satisfied and the merge is allowed to take place. As shown on the right side of Figure 7, it is possible to add reviewers, labels and assigned users to augment the pull request.
To process the merge of the pull request, a user with appropriate permissions can simply press the green “Merge pull request” button. This will cause a new commit to appear on the target branch, which can cause OpenShift GitOps (Argo CD) to deploy the changes to an OpenShift platform.
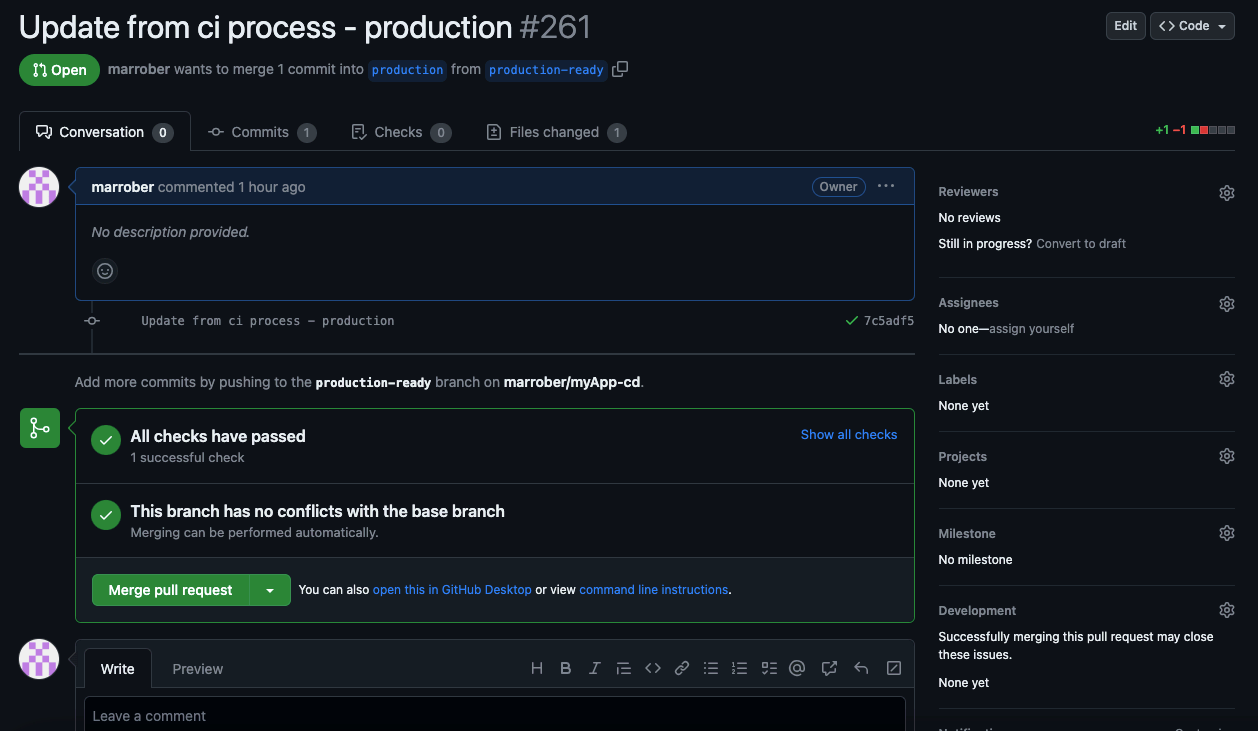
Figure 7: Pull request summary
Creating a pull request from the command line
Creating a pull request from the command line interface requires the use of the gh command-line utility. This is not the git user interface with which many users are familiar; instead it is a command-line utility specific to the GitHub system. Users are also able to create their own API integration to GitHub, or GitLab, to achieve a similar capability.
The use of the gh executable to create a pull request is a very simple two-step process:
Step 1: Authentication
A user access token is required to authenticate a user who has permission to create the pull request. The token should be stored securely as part of the continuous integration process, but care must be taken to make sure that it is not committed to the GitHub repository. Storing the token in a secret within the OpenShift continuous integration project is generally acceptable, provided that access to the project, and access to secrets within the project, is managed using appropriate role-based access control (RBAC).
Assuming that a continuous integration process has the ability to read the secret and write it to a temporary text file within the build workspace, the authentication process can proceed with a command similar to this:
gh auth login --with-token < gh-token.txtIt is important to make sure that any temporary files containing tokens are not accessible after the continuous integration process has completed. Additionally, the permissions associated with the token should be limited to the creation of a pull request only.
Step 2: Pull request creation
To create the pull request, use a command similar to the one below, with placeholders for the ‘from’ and ‘to’ branches.
gh pr create --fill --head <from-branch> --base <to-branch>Many additional options are available, documented here, to add additional information to the pull request if required.
Managing the pull request with commit status checks
The pull request process can be managed using the status check branch protection rule. This can be used to block the merge of the pull request until tests have been completed successfully on the content that will be merged to the target branch. This is particularly useful when a continuous integration process is updating files and committing changes automatically, as described in Figure 8. The directory structures referred to in the following steps for each environment are clearly explained in this article: GitOps Continuous Delivery with OpenShift GitOps and Kustomize.
The status check in this example, performed as part of a continuous integration process, is a vulnerability scan of the container image for which the tag is being updated in a Kustomize file. The pull request can only be processed to merge content to a monitored branch so that OpenShift GitOps deploys a container image if the container image does not contravene vulnerability policies.
- The source code for the application is cloned to a local workspace within the context of the continuous integration process and the application is compiled. A new container image is created with a unique tag. The tag of the image is added to the Kustomize file for the development environment so that the new application is quickly deployed for development testing.
- Before any activity takes place to deploy the application to a quality assurance environment, a vulnerability scan takes place of the image to check that it meets the policy requirements. This is a gate point in the continuous integration process, at which point the process will stop if vulnerabilities are found.
- The update of the Kustomize file for the quality assurance environment now takes place to update the image tag to be used in the deployment. This change is performed on a branch called qa-ready. After the change has been committed and pushed to the repository, a pull request is created to enable the change to be reviewed and merged from the qa-ready branch to the main branch.
- The status of the commit created in Step 3 is changed to pending. Since a branch protection rule exists to block merges of pull requests with pending commits, the pull request is now effectively on hold. This allows time for the continuous integration process to complete the automated validation steps before the pull request is released to be processed.
- The configuration assets on the qa-ready branch are cloned to a local directory in the workspace of the continuous integration process. This includes the new commit containing the change of the container image alongside any other changes that have been recently made to the configuration assets.
- As explained in detail in the article GitOps Continuous Delivery with OpenShift GitOps and Kustomize, when Kustomize is used, the files stored in the Git repository are not the exact files that will be deployed to the OpenShift cluster. To validate the files that will be used for deployment it is necessary to process the Kustomize file to apply any patches and container image tag replacements. This is done using the following command which will generate all deployment assets in a single output.yaml file. For further information consult the Kustomize documentation.
Kustomize build > output.yaml- The generated file is split into the constituent pieces and analyzed by Red Hat Advanced Cluster Securitys to validate that the resulting YAML assets do not contravene any policies. This process includes the analysis of the container image again to make sure that it does not contravene any vulnerability-related policies.
- If the resource validation step is successful, then the status of the commit is set to success and the merge of the pull request can take place.
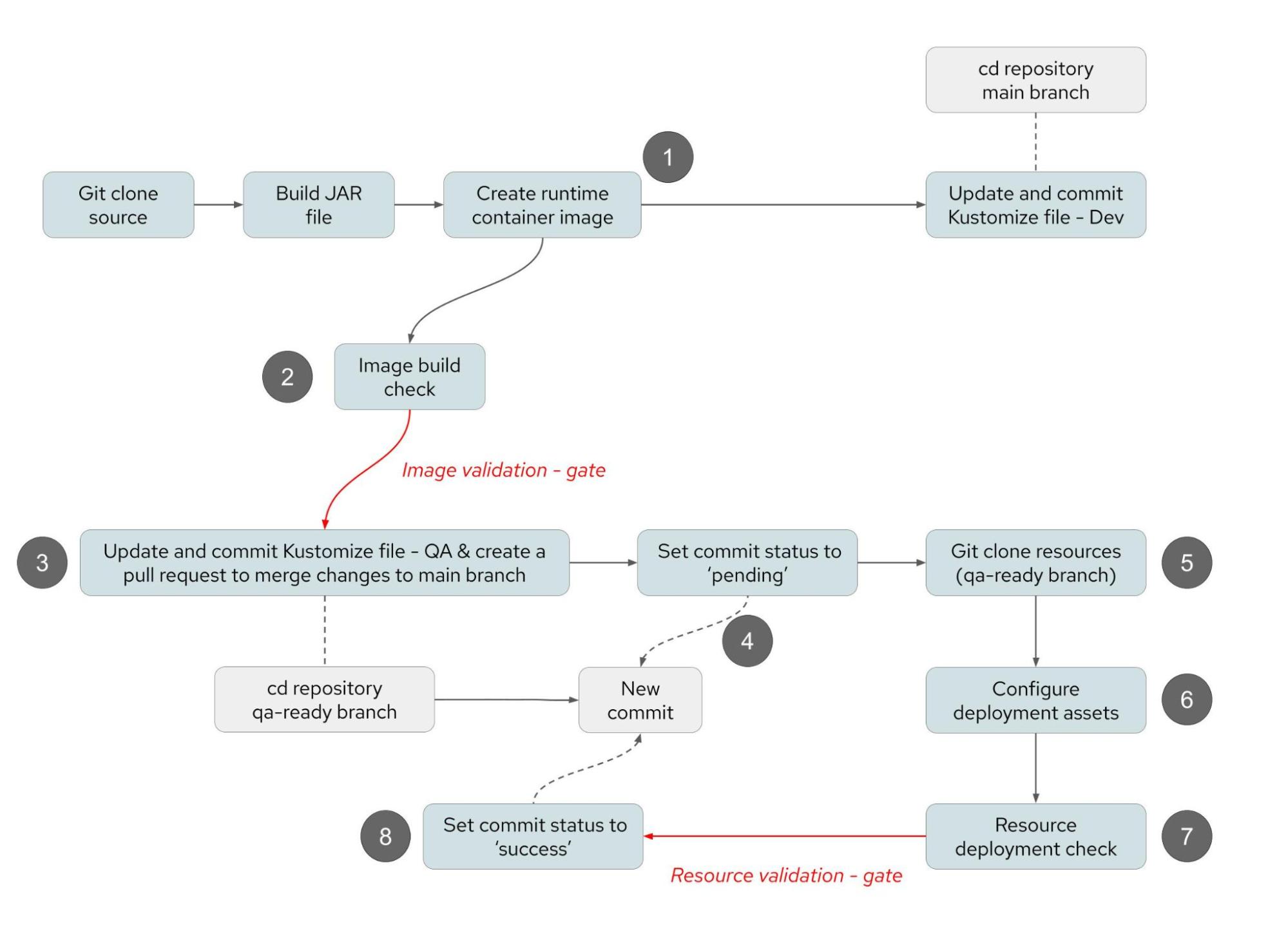
Figure 8: Continuous integration process with update of deployment resources
Further validation steps can be performed as required by each individual continuous integration process to help make sure that users are confident in the deployment assets to be used before a pull request is processed.
Adding status to GitHub commits
The GitHub rest API is used to apply the status to a commit. An example is shown below to add a status of "pending." The example has been split over multiple lines to aid readability.
curl -s -H 'Content-Type: application/json'
-X POST -u <git-host-access-token>:x-oauth-basic
-d '{"state":"pending", "description":"<high-level-summary>",
"context":"<system-providing-the-status"}'
https://api.github.com/repos/<git-repo>/statuses/<commit-sha>A target_url parameter may also be included to point to the build process that is performing the testing. This aids traceability from the GitHub context to how the application was built and tested.
Summary
Pull requests are a fundamental part of a GitOps strategy. They cause merges to add new content to branches, which are monitored by Argo CD applications that automatically deploy the updated resources impacted by the commits to an OpenShift environment.
Branch protection rules enable teams to apply sensible steps that let a human interact with the process to validate the commits. It is also possible to wrap a layer of automated validation and testing around the merge process to give confidence in the scope of change and the impact of such changes by the extension of continuous integration processes.
Red Hat Advanced Cluster Security can help validate that the resulting content of a merge operation satisfies an organization's security policies, while other tools can also be used to perform additional testing as appropriate. This level of validation can give an organization the confidence to progress changes to production quickly and easily, which reduces the cost of change.
Sobre o autor

Mais como este
Navegue por canal

Automação
Últimas novidades em automação de TI para empresas de tecnologia, equipes e ambientes

Inteligência artificial
Descubra as atualizações nas plataformas que proporcionam aos clientes executar suas cargas de trabalho de IA em qualquer ambiente

Nuvem híbrida aberta
Veja como construímos um futuro mais flexível com a nuvem híbrida

Segurança
Veja as últimas novidades sobre como reduzimos riscos em ambientes e tecnologias

Edge computing
Saiba quais são as atualizações nas plataformas que simplificam as operações na borda

Infraestrutura
Saiba o que há de mais recente na plataforma Linux empresarial líder mundial

Aplicações
Conheça nossas soluções desenvolvidas para ajudar você a superar os desafios mais complexos de aplicações

Programas originais
Veja as histórias divertidas de criadores e líderes em tecnologia empresarial
Produtos
- Red Hat Enterprise Linux
- Red Hat OpenShift
- Red Hat Ansible Automation Platform
- Red Hat Cloud Services
- Veja todos os produtos
Ferramentas
- Treinamento e certificação
- Minha conta
- Suporte ao cliente
- Recursos para desenvolvedores
- Encontre um parceiro
- Red Hat Ecosystem Catalog
- Calculadora de valor Red Hat
- Documentação
Experimente, compre, venda
Comunicação
- Contate o setor de vendas
- Fale com o Atendimento ao Cliente
- Contate o setor de treinamento
- Redes sociais
Sobre a Red Hat
A Red Hat é a líder mundial em soluções empresariais open source como Linux, nuvem, containers e Kubernetes. Fornecemos soluções robustas que facilitam o trabalho em diversas plataformas e ambientes, do datacenter principal até a borda da rede.
Selecione um idioma
Red Hat legal and privacy links
- Sobre a Red Hat
- Oportunidades de emprego
- Eventos
- Escritórios
- Fale com a Red Hat
- Blog da Red Hat
- Diversidade, equidade e inclusão
- Cool Stuff Store
- Red Hat Summit