
AI and machine learning (ML) are front-of-mind topics for our clients. These days, we increasingly hear that organizations have created their own data science and AI workload. Millions of dollars are spent developing and implementing new models to help drive business cases.
Until now, most of that effort focused on building the model. However, where clients fail is in taking the next step: Putting the model into production and treating it as a core operational asset within their business processes.
Traditional IT teams worked in silos. Later, some companies began implementing DevOps teams, which work closely with IT and Operations. Now, Data Science teams work with these other teams to serve the business, whether building applications to run day-to-day operations or providing insights through AI models. Organizations struggle to scale artificial intelligence (AI) and machine learning (ML) initiatives because of data, security, privacy, and infrastructure concerns.
So, how do we bring AI models and traditional software development teams together, and what are some things to consider when discussing integrating AI or machine learning models into an application?
The Red Hat OpenShift Data Science (RHODS) offering is specifically designed for data scientists, helping them leverage the capabilities of OpenShift and deploy their ML models without worrying about maintaining the infrastructure. It simplifies the end-to-end data science process from model development and deployment. It also provides a collaborative environment where data scientists, analysts, and developers can work together seamlessly.
Build with collaboration in mind

The workflow begins with gathering and preparing data. Data often must be federated from a range of sources. Exploring and understanding data plays a key role in the success of a data science project.
Developers want to reduce the time needed to get to production while taking advantage of best-in-breed services regardless of where they are (on-prem or public cloud). Their apps must work on-prem, in private and public clouds, and increasingly at the edge.
Operations teams want consistency, which means abstracting away operational complexity, increasing security, decreasing costs, and ensuring cross-environment compatibility. They look for tooling that provides visibility into the entirety of a company's IT footprint and enables those outcomes.
Businesses want to deliver applications on any footprint, anywhere, without building out a location-specific infrastructure.
RHODS is an easy-to-manage platform with hardware acceleration and an ecosystem of ML tools. It allows data science teams to package their workloads and deploy them in a scalable and reproducible manner. Teams can deploy workloads on-prem, in the cloud, or in a hybrid environment. RHODS eliminates the challenges of environment inconsistencies and versioning conflicts. Models perform consistently across different stages of pipelines.
Flexibility and scalability
Lifecycle stages include data exploration and preparation, model development and deployment, and optimization and monitoring with a feedback loop. Data scientists, business analysts, data engineers, and subject matter experts are crucial players in this lifecycle.
Data science projects often require substantial computational resources to handle large datasets, train complex models, and perform extensive experimentation. Red Hat OpenShift Data Science addresses these requirements by enabling organizations to scale their compute resources up or down based on demand. RHODS relieves customers of configuring AI/ML technologies together and managing separate lifecycles on their own. It simplifies the management of the platform from an IT Operations perspective; platform engineers can create configurations for their data scientists and application developers that scale and can be administered with less effort.
For example, IT admins can create GPU workloads on demand so data scientists can continue their experiments without worrying about infrastructure. This flexibility enables teams to perform experiments more efficiently, reducing time to insight and improving productivity.
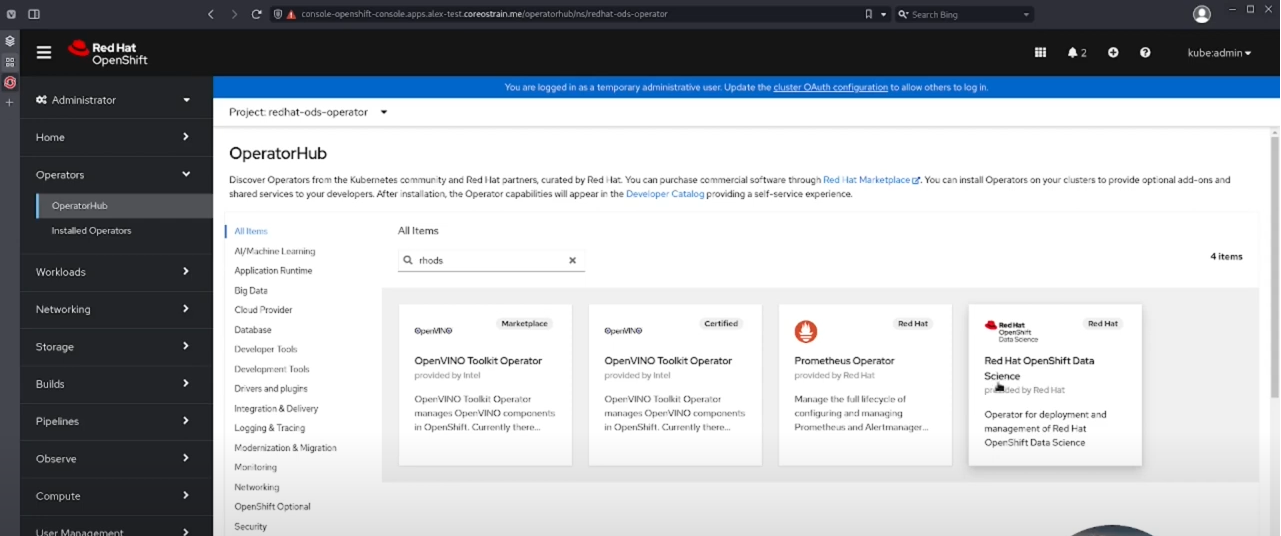
Model management and deployment
One of the key challenges in data science is managing and deploying models in production environments. Red Hat OpenShift Data Science provides a robust framework for model management, allowing teams to version, track, and organize their models effectively. The platform integrates with popular machine learning libraries and frameworks.
It leverages Open Data Hub as an example of Red Hat's investment in the upstream community. This project, which our office of the CTO has nurtured for almost five years, integrates over 20 open source AI/ML components in an OpenShift meta operator and serves as an architectural blueprint to leverage the innovation occurring in these communities.
This approach means the required tools and runtimes needed to develop and deploy models are available, making it simpler to operationalize data science projects and derive value from predictive models.
Collaboration and governance
Successful data science projects require collaboration and governance across teams. OpenShift Dev Spaces is available on top of OpenShift, which facilitates collaboration by providing shared workspaces and tools that enable data scientists, analysts, and developers to work together effectively.
The platform allows teams to create reproducible workflows, share code and data, and track the progress of projects. It also offers granular access controls to protect sensitive data and intellectual property. The platform promotes transparency, accountability, and knowledge sharing within organizations by fostering collaboration and providing governance capabilities.
Partner ecosystem
We have been building an AI/ML technology partner ecosystem around OpenShift, with over 30 AI/ML software and hardware accelerator partners who certify and run on OpenShift. The integration with OpenShift also allows organizations to leverage other services, such as monitoring, logging, and CI/CD pipelines, to enhance the operational aspects of their data science workflows.
Red Hat OpenShift Data Science helps users get insights from their data by deploying workloads on OpenShift that are related to data science, including artificial intelligence, machine learning, and analytics. RHODS makes this easier by providing developer and data science teams with an environment and experience for building data science workflows.
Using managed services like Azure Red Hat OpenShift and Red Hat OpenShift Service on AWS provides full stack management and a unified experience, allowing teams to capture the benefits of OpenShift and offering a flexible hybrid cloud environment where organizations can choose the cloud and infrastructure best for specific workloads without vendor lock-in.
Learn More about OpenShift Data Science
- Try out RHODS for free in the Developer Sandbox
- Exploring Red Hat OpenShift Data Science
- Talk to Red Hatter - Red Hat OpenShift Data Science page.
关于作者









产品
工具
试用购买与出售
沟通
关于红帽
我们是世界领先的企业开源解决方案供应商,提供包括 Linux、云、容器和 Kubernetes。我们致力于提供经过安全强化的解决方案,从核心数据中心到网络边缘,让企业能够更轻松地跨平台和环境运营。