随着每个新版本的发布,大语言模型(LLM)的规模似乎变得越来越大。这需要使用大量 GPU 来训练模型,并且在模型的整个生命周期中,也需要更多的资源来进行微调、推理等操作。这些 LLM 呈现出新的摩尔定律:模型规模(以参数量衡量)每四个月就会翻一番。
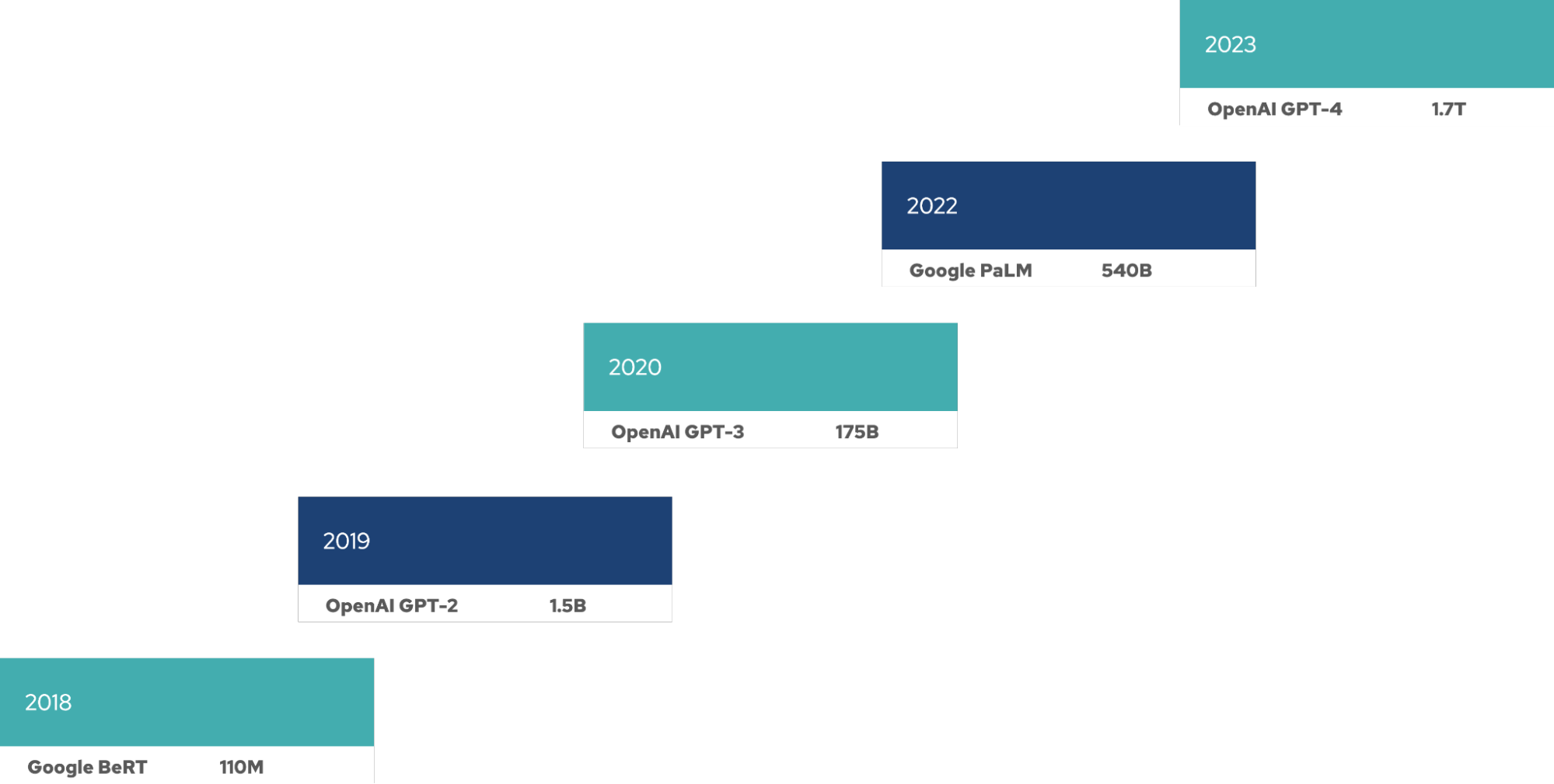
LLM 成本高昂
训练和运维 LLM 需要耗费大量资源、时间与资金成本。资源需求直接影响着部署 LLM 的公司,无论是在自己的基础架构上部署,还是使用超大规模云服务商,都是如此。眼下,LLM 的规模仍在持续扩张。
此外,运维 LLM 需要大量资源。Llama 3.1 LLM 具有 4,050 亿个参数,仅推理就需要 810GB 内存(FP16)。Llama 3.1 模型系列在 GPU 集群上基于 15 万亿个词元进行了训练,累计消耗 3,900 万 GPU 小时。随着 LLM 规模呈指数级增长,训练和运维模型所需的计算和内存资源也在同步激增。Llama 3.1 微调需要 3.25TB 内存。
去年,全球 GPU 曾出现严重短缺问题,而就在供需缺口逐渐弥合之际,下一个瓶颈预计将是电力资源。随着越来越多的数据中心上线,每个数据中心的耗电量已翻倍至近 150 兆瓦,这对 AI 行业带来的挑战不言而喻。
如何降低 LLM 成本
在我们探讨如何降低 LLM 成本之前,不妨先来看一个大家都很熟悉的例子。相机在不断改进,新型号可以拍摄比以往更高分辨率的照片,但每个原始图像文件的大小可能高达 40MB(或更大)。除非是需要处理这些图像的媒体专业人士,否则大多数人都更乐意使用 JPEG 版本的图像,这种格式可以将文件大小缩减 80%。当然,JPEG 使用的压缩技术会降低 RAW 原始文件的图像质量,但对于大多数应用场景来说,JPEG 已经足够好用。此外,处理和查看原始图像通常需要使用专门的应用。因此,与 JPEG 图像相比,处理原始图像的计算成本更高。
现在,我们回过头来讨论 LLM。模型规模取决于参数量,因此一种降低成本的方法是使用参数量较少的模型。所有主流开源模型都有一系列参数量可供选择,您可以根据具体应用场景选择最合适的配置。
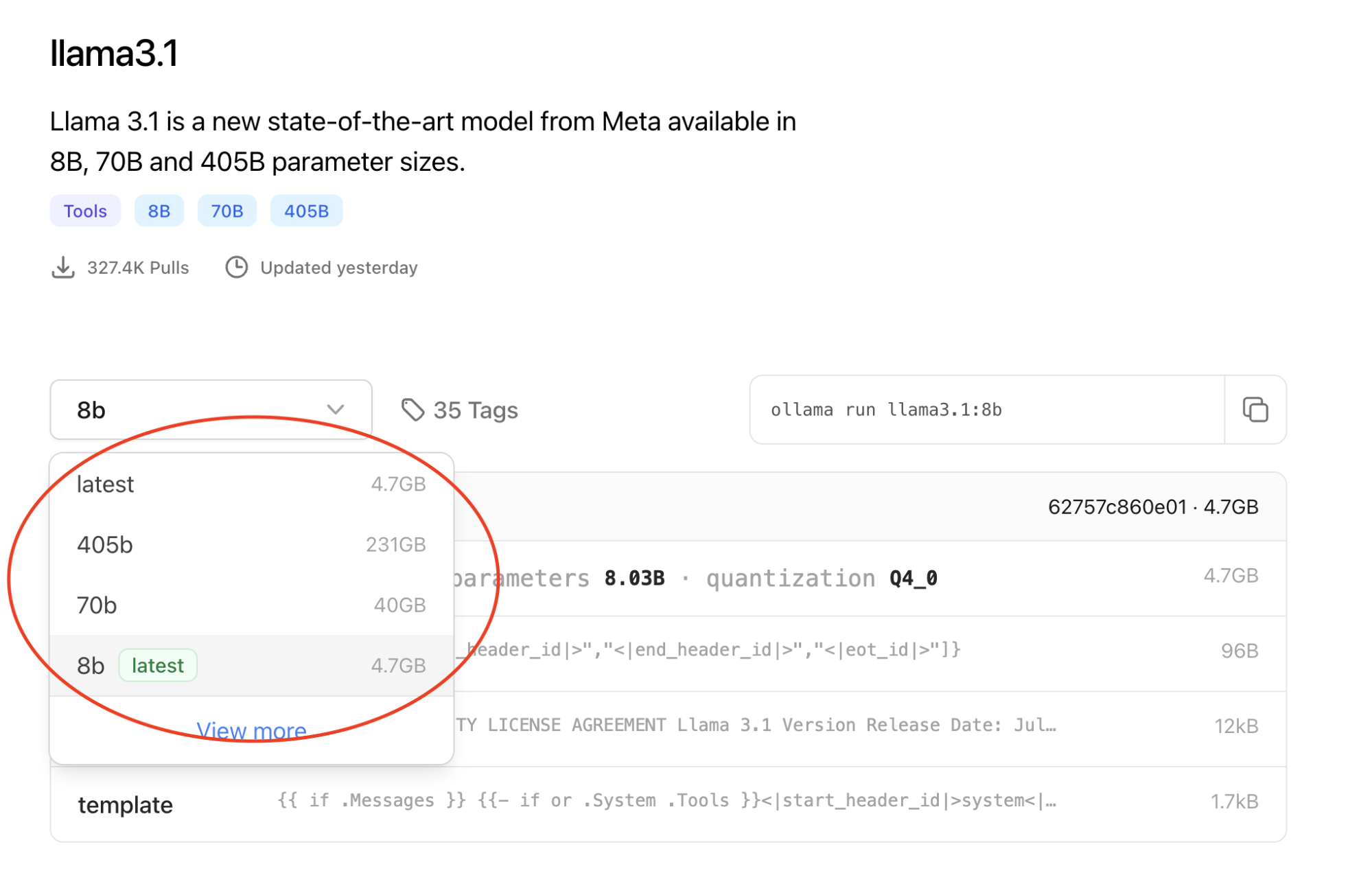
然而,在大多数基准测试中,参数量较多的 LLM 的表现通常优于参数较少的 LLM。若要降低资源要求,最好使用参数更多的模型,但将其压缩至更小的规模。测试表明,GAN 压缩可将计算量减少 近 20 倍。
压缩 LLM 的方法有数十种,包括量化、修剪、知识提炼和减少层数等。
量化
量化可将模型中的数值从 32 位浮点格式转换为精度更低的数据类型:16 位浮点、8 位整数、4 位整数甚至 2 位整数。通过降低数据类型的精度,模型在运维期间需要的位数更少,从而降低内存和计算需求。量化可以在模型训练完成后或训练过程中实施。
随着位数的降低,我们需要在量化和性能之间进行权衡。这份白皮书重点介绍了 4 位量化为大型(至少 700 亿个参数)模型提供的理想数值范围。若采用低于 4 位的量化,LLM 与其量化版本之间会出现显著的性能差异。对于较小的模型,6 位或 8 位量化可能是更好的选择。
多亏了量化技术,我才可以在笔记本电脑上运行这个 LLM RAG 演示。
修剪
修剪技术通过剔除重要性较低的权重或神经元来减小模型规模。采用这项技术时,需要在减小模型规模与保持准确性之间实现精妙平衡。修剪可以在模型训练之前、期间或之后实施。层修剪则更进一步,直接删除整个层块。在这份白皮书中,作者报告称最多可删除 50% 的层,而仅造成微小的性能下降。
知识提炼
这种技术可将知识从大型模型(教师模型)迁移至小型模型(学生模型)。小型模型根据大型模型的输出进行训练,而非基于大型模型的训练数据。
这份白皮书表明,将 Google 的 BERT 模型提炼为 DistilBERT 后,模型规模缩小 40%,推理速度提升 60%,同时保留了原模型 97% 的语言理解能力。
混合方法
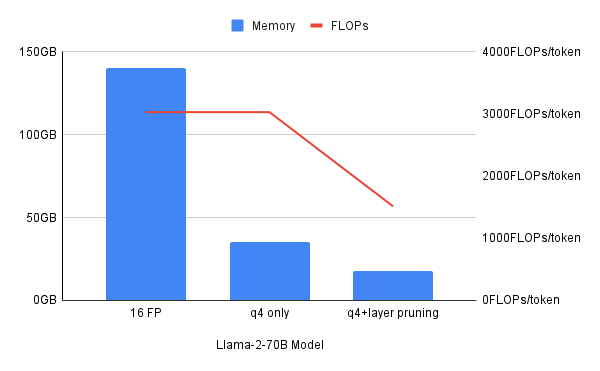
虽然每种压缩技术各具优势,但结合不同压缩技术的混合方法,有时可以实现最佳效果。这份白皮书指出,虽然 4 位量化可将内存需求减少 4 倍,但无法减少以每秒浮点运算次数(FLOPS)衡量的计算资源需求。而结合使用量化与层修剪技术,可以同时减少内存和计算资源需求。
小型模型的优势
使用小型模型可以显著降低计算需求,同时保持较高的性能和准确性。
- 降低计算成本:小型模型对 CPU 和 GPU 的要求较低,可显著节省成本。考虑到每个高端 GPU 的成本高达 30,000 美元,任何计算成本的降低都是好消息
- 减少内存使用量:与大型模型相比,小型模型需要的内存更少。这有助于将模型部署到资源受限的系统中,例如物联网设备或手机
- 加快推理速度:小型模型可以快速加载并执行,从而减少推理延迟。对于自动驾驶汽车等实时应用场景,更快的推理速度可以带来质的提升
- 减少碳足迹:小型模型通过降低计算需求来提升能效,从而减少对环境的影响
- 提高部署灵活性:小型模型的计算需求较低,可以更灵活地部署在所需位置。可以部署这些模型来适应不断变化的用户需求或系统限制,包括网络边缘场景
规模更小、成本更低的模型越来越受欢迎,最近发布的 ChatGPT-4o mini(比 GPT-3.5 Turbo 便宜 60%)以及 SmolLM 和 Mistral NeMo 等开源创新都证明了这一点:
- Hugging Face SmolLM:一个小型模型系列,其中的模型分别拥有 1.35 亿、3.6 亿和 17 亿参数量
- Mistral NeMo:与 Nvidia 合作构建的拥有 120 亿参数量的小型模型
这种小语言模型(SLM)的发展趋势正是由我们前文讨论的优势所驱动。小型模型领域提供丰富的选择:可以使用预构建的模型,也可以使用压缩技术来精简现有 LLM。具体采用哪种方法来选择小型模型,取决于您的用例需求,因此请仔细考虑您的选择。
关于作者

Ishu Verma is Technical Evangelist at Red Hat focused on emerging technologies like edge computing, IoT and AI/ML. He and fellow open source hackers work on building solutions with next-gen open source technologies. Before joining Red Hat in 2015, Verma worked at Intel on IoT Gateways and building end-to-end IoT solutions with partners. He has been a speaker and panelist at IoT World Congress, DevConf, Embedded Linux Forum, Red Hat Summit and other on-site and virtual forums. He lives in the valley of sun, Arizona.






