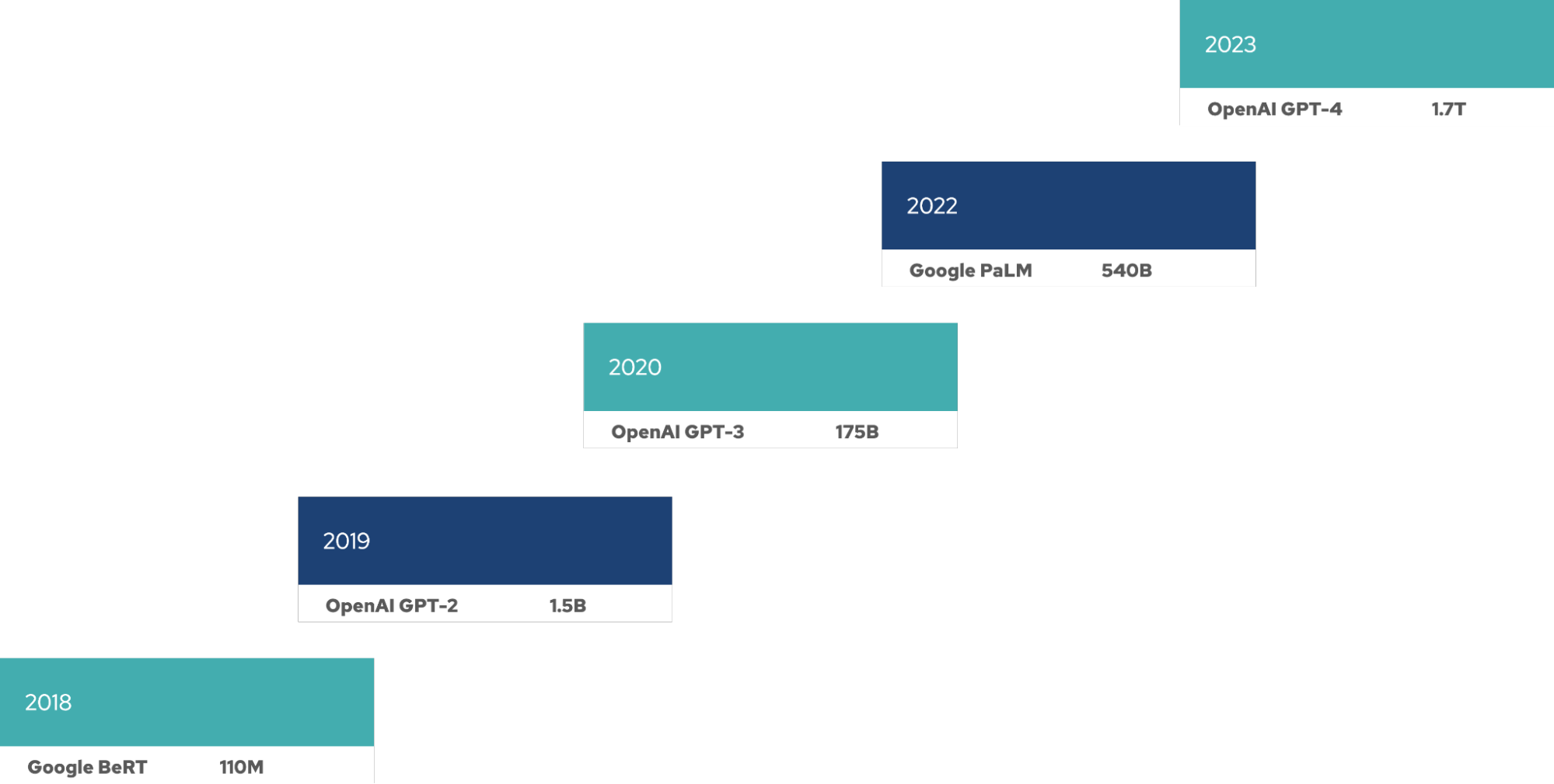
LLMs (Large Language Models) scheinen von Release zu Release immer umfassender zu werden. Für das Training dieser Modelle ist eine große Anzahl von GPUs erforderlich und während des gesamten Modell-Lifecycles werden weitere Ressourcen für Fine Tuning, Inferenzen usw. benötigt. Für diese LLM gilt ein neues Moore'sches Gesetz: Die Modellgröße (gemessen an der Anzahl der Parameter) verdoppelt sich alle 4 Monate.
LLMs sind teuer
Das Trainieren und Betreiben eines LLMs ist teuer in Bezug auf Ressourcen, Zeit und Geld. Die Ressourcenanforderungen wirken sich direkt auf Unternehmen aus, die ein LLM bereitstellen – und das unabhängig davon, ob es sich um die eigene Infrastruktur oder einen Hyperscaler handelt. LLMs werden auch zunehmend größer.
Darüber hinaus erfordert der Betrieb eines LLMs viele Ressourcen. Das LLM Llama 3.1 verfügt über 405 Milliarden Parameter und benötigt 810 GB an Speicher (FP16) allein für die Inferenz. Die Llama 3.1-Modellfamilie wurde anhand von 15 Billionen Token auf einem GPU-Cluster mit 39 Millionen GPU-Stunden trainiert. Mit einem exponentiellen Wachstum der LLMs steigen auch die Computing- und Speicheranforderungen für Training und Betrieb. Für das Fine Tuning von Llama 3.1 sind 3,25 TB an Speicher erforderlich.
Letztes Jahr bestand ein gravierender Mangel an GPUs. Sobald sich das Ungleichgewicht zwischen Angebot und Nachfrage verbessert, wird als nächster Engpass die Stromversorgung erwartet. Da mehr Rechenzentren online gehen und sich der Stromverbrauch für die einzelnen Rechenzentren auf fast 150 MW verdoppelt, ist es offensichtlich, warum dies zu einem Problem für die KI-Branche wird.
Wie LLMs kostengünstiger werden
Bevor wir darüber sprechen, wie Sie die Kosten für LLMs senken können, betrachten wir ein Beispiel, mit dem wir alle vertraut sind. Kameras werden ständig verbessert, und neue Modelle nehmen Bilder mit höherer Auflösung als je zuvor auf. Die Rohbilddateien können jedoch jeweils bis zu 40 MB (oder mehr) groß sein. Sofern Sie kein Medienprofi sind, der diese Bilder bearbeiten muss, sind die meisten Nutzenden mit einer JPEG-Version des Bilds zufrieden, mit der sich die Dateigröße um 80 % reduzieren lässt. Zwar verringert die von JPEG verwendete Komprimierung die Bildqualität des RAW-Originals, aber für die meisten Zwecke ist JPEG ausreichend. Darüber hinaus sind in der Regel spezielle Anwendungen erforderlich, um ein Rohbild zu verarbeiten und anzuzeigen. Daher sind dafür im Vergleich zu einem JPEG-Bild höhere Rechenkosten erforderlich.
Kommen wir nun zurück zu den LLMs. Die Modellgröße hängt von der Anzahl der Parameter ab. Ein Ansatz ist daher, Modelle mit einer geringeren Anzahl von Parametern zu verwenden. Alle gängigen Open Source-Modelle verfügen über eine Reihe von Parametern, aus denen Sie diejenigen auswählen können, die sich am besten für eine bestimmte Anwendung eignen.
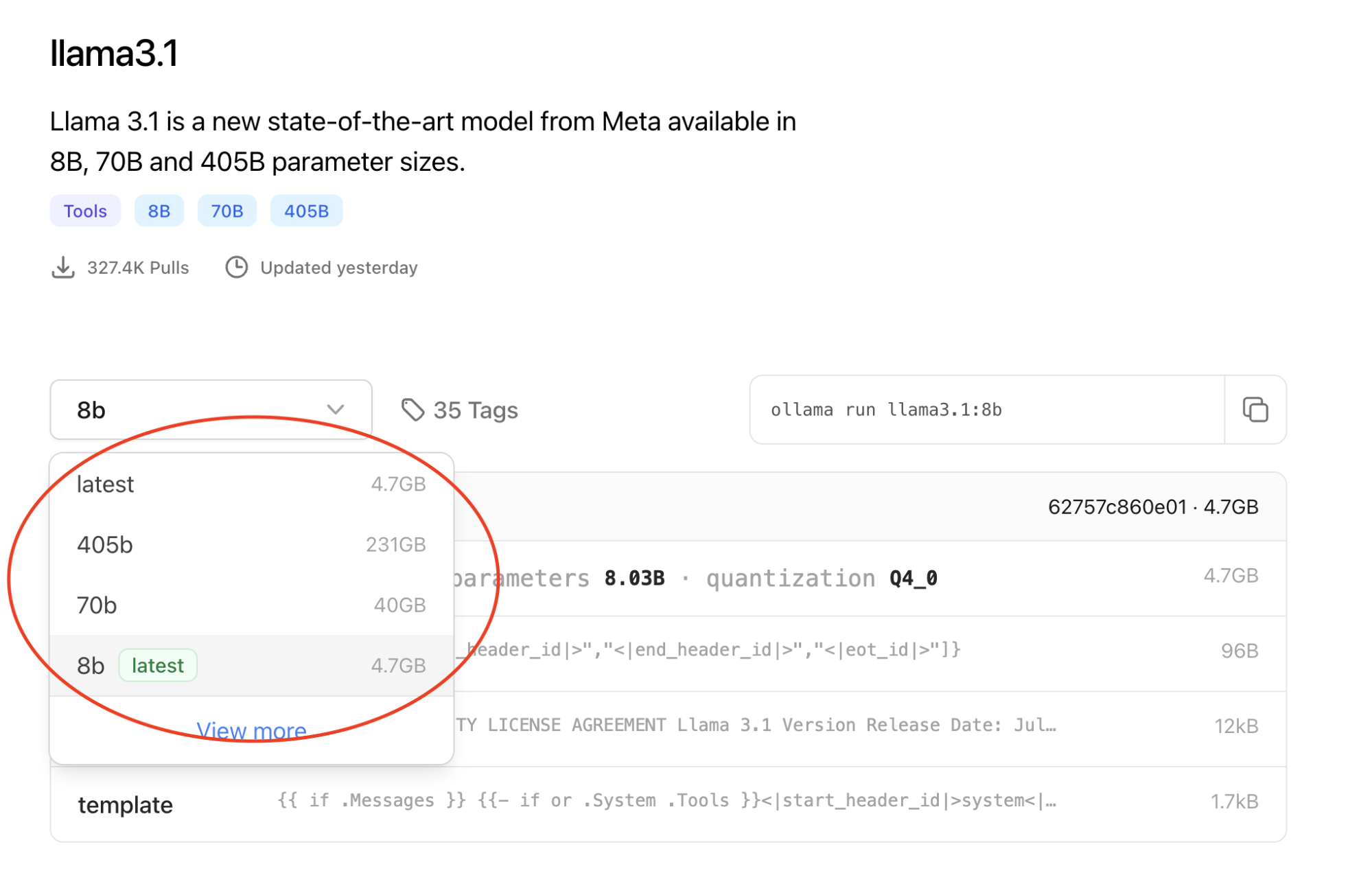
Ein LLM mit einer größeren Anzahl von Parametern zeigt jedoch bei den meisten Benchmarks im Allgemeinen eine bessere Performance als ein LLM mit weniger Parametern. Zur Senkung der Ressourcenanforderungen ist es möglicherweise besser, ein Modell mit mehr Parametern zu verwenden, es aber auf eine geringere Größe zu komprimieren. Tests haben gezeigt, dass mit GAN-Komprimierung der Rechenaufwand um fast das 20-fache reduziert werden kann.
Es gibt Dutzende von Ansätzen zur Komprimierung eines LLM, darunter Quantisierung, Pruning (Bereinigung), Wissensdestillation und Ebenenreduktion.
Quantisierung
Durch Quantisierung werden die numerischen Werte in einem Modell vom 32 Bit-Gleitkommaformat in einen Datentyp mit niedrigerer Präzision geändert: 16 Bit-Gleitkomma, 8 Bit-Ganzzahl, 4 Bit-Ganzzahl oder sogar 2 Bit-Ganzzahl. Durch Verringern des Precision-Datentyps benötigt das Modell bei Abläufen weniger Bit, was zu weniger Bedarf an Speicher und Rechenleistung führt. Die Quantisierung kann nach oder beim Training des Modells erfolgen.
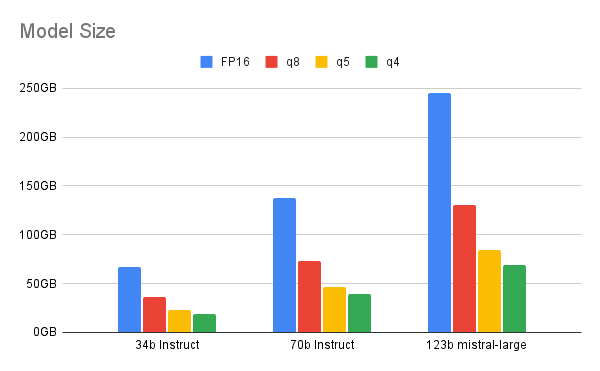
Wenn wir zu weniger Bits wechseln, müssen wir einen Kompromiss zwischen Quantisierung und Performance wählen. Dieser Artikel zeigt den idealen Bereich auf, den die 4 Bit-Quantisierung für größere Modelle (mindestens 70 Milliarden Parameter) bietet. Alles, was niedriger liegt, zeigt eine deutliche Diskrepanz bei der Performance zwischen dem LLM und seiner quantisierten Version. Für ein kleineres Modell ist die 6 Bit- oder 8 Bit-Quantisierung wahrscheinlich die bessere Wahl.
Dank der Quantisierung kann ich diese LLM RAG-Demo auf meinem Laptop ausführen.
Pruning
Durch das Bereinigen wird die Modellgröße reduziert, indem weniger wichtige Gewichtungen oder Neuronen eliminiert werden. Zwischen der Reduzierung der Modellgröße und der Beibehaltung der Genauigkeit muss ein sensibles Gleichgewicht bestehen. Das Bereinigen des Modells kann vor, während oder nach dem Modelltraining erfolgen. Das Bereinigen von Schichten führt diese Idee weiter, indem ganze Blöcke von Schichten entfernt werden. In diesem Artikel geben die Autoren an, dass bis zu 50 % der Schichten mit einem minimalen Abfall der Performance entfernt werden können.
Wissensdestillation
Hierbei wird Wissen von einem großen Modell (Lehrer) auf ein kleineres Modell (Schüler) übertragen. Das kleinere Modell wird anhand der Ausgaben des größeren Modells anstatt anhand umfangreicherer Trainingsdaten trainiert.
Dieser Bericht zeigt, wie die BERT-Modelldestillation von Google zu DistilBERT die Modellgröße um 40 % reduzierte und die Inferenzgeschwindigkeit um 60 % erhöhte. 97 % der Fähigkeiten zum Verstehen von Sprache wurden dabei beibehalten.
Hybrider Ansatz
Obwohl diese einzelnen Komprimierungstechniken jeweils hilfreich sind, eignet sich manchmal ein hybrider Ansatz, der verschiedene Komprimierungstechniken kombiniert, am besten. Dieser Artikel erläutert, wie durch 4 Bit-Quantisierung der Speicherbedarf um das Vierfache reduziert werden kann, nicht jedoch die Rechenressourcen, gemessen an FLOPS (Floating Point Operations per Second). Quantisierung in Kombination mit Layer Pruning trägt dazu bei, den Bedarf an Speicher und Rechenleistung zu reduzieren.
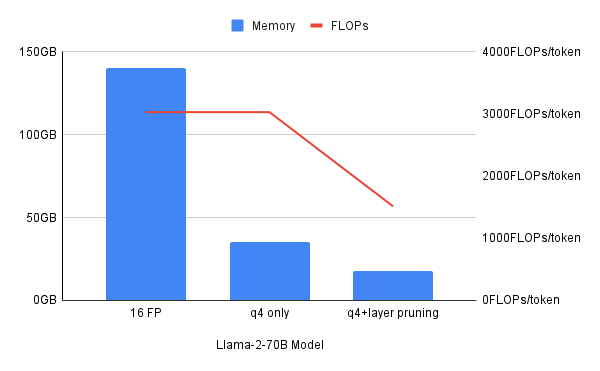
Vorteile eines kleineren Modells
Durch den Einsatz kleinerer Modelle lassen sich die Rechenanforderungen erheblich reduzieren und gleichzeitig ein hohes Maß an Performance und Genauigkeit erhalten.
- Geringere Rechenkosten: Kleinere Modelle senken die CPU- und GPU-Anforderungen, was zu erheblichen Kosteneinsparungen führen kann. Angesichts der Tatsache, dass High-End-GPUs bis zu 30.000 US-Dollar pro Stück kosten können, stellen geringere Rechenkosten eine gute Nachricht dar.
- Verringerte Speichernutzung: Kleinere Modelle benötigen im Vergleich zu größeren Modellen weniger Speicher. Dies ist hilfreich für Modellbereitstellungen in Systemen mit beschränkten Ressourcen wie IoT-Geräten oder Mobiltelefonen.
- Schnellere Inferenz: Kleinere Modelle können schneller geladen und ausgeführt werden, was zu einer geringeren Inferenzlatenz führt. Schnellere Inferenz kann bei Echtzeitanwendungen wie autonomen Fahrzeugen einen großen Unterschied bewirken.
- Reduzierter CO2-Fußabdruck: Reduzierte Rechenanforderungen für kleinere Modelle tragen zur Verbesserung der Energieeffizienz bei und verringern so die Umweltbelastung.
- Flexible Deployments: Geringere Rechenanforderungen erhöhen die Flexibilität für das Deployment von Modellen an den Orten, an denen sie benötigt werden. Die Modelle können so bereitgestellt werden, dass sie sich an dynamisch ändernde Nutzeranforderungen oder Systembeschränkungen anpassen, auch am Netzwerkrand.
Kleinere und kostengünstigere Modelle werden immer beliebter, wie die jüngsten Releases von ChatGPT-4o mini (60 % günstiger als GPT-3.5 Turbo) und die Open Source-Innovationen SmolLM und Mistral NeMo zeigen:
- Hugging Face SmolLM: Eine Familie kleiner Modelle mit 135 Millionen, 360 Millionen und 1,7 Milliarden Parametern
- Mistral NeMo: Ein kleines Modell mit 12 Milliarden Parametern, das in Zusammenarbeit mit Nvidia entwickelt wurde
Dieser Trend hin zu SLMs (Small Language Models) wird von den oben diskutierten Vorteilen begünstigt. Bei kleineren Modellen stehen zahlreiche Optionen zur Verfügung: Verwenden Sie ein vorgefertigtes Modell oder nutzen Sie Komprimierungstechniken, um ein vorhandenes LLM zu verkleinern. Der Auswahl eines kleinen Modells muss Ihr Use Case zugrunde liegen, daher sollten Sie Ihre Optionen sorgfältig prüfen.
Über den Autor

Ishu Verma is Technical Evangelist at Red Hat focused on emerging technologies like edge computing, IoT and AI/ML. He and fellow open source hackers work on building solutions with next-gen open source technologies. Before joining Red Hat in 2015, Verma worked at Intel on IoT Gateways and building end-to-end IoT solutions with partners. He has been a speaker and panelist at IoT World Congress, DevConf, Embedded Linux Forum, Red Hat Summit and other on-site and virtual forums. He lives in the valley of sun, Arizona.
Ähnliche Einträge
Why the future of AI depends on a portable, open PyTorch ecosystem
Scaling Earth and space AI models with Red Hat AI Inference Server and Red Hat OpenShift AI
Technically Speaking | Build a production-ready AI toolbox
Technically Speaking | Platform engineering for AI agents
Nach Thema durchsuchen

Automatisierung
Das Neueste zum Thema IT-Automatisierung für Technologien, Teams und Umgebungen

Künstliche Intelligenz
Erfahren Sie das Neueste von den Plattformen, die es Kunden ermöglichen, KI-Workloads beliebig auszuführen

Open Hybrid Cloud
Erfahren Sie, wie wir eine flexiblere Zukunft mit Hybrid Clouds schaffen.

Sicherheit
Erfahren Sie, wie wir Risiken in verschiedenen Umgebungen und Technologien reduzieren

Edge Computing
Erfahren Sie das Neueste von den Plattformen, die die Operations am Edge vereinfachen

Infrastruktur
Erfahren Sie das Neueste von der weltweit führenden Linux-Plattform für Unternehmen

Anwendungen
Entdecken Sie unsere Lösungen für komplexe Herausforderungen bei Anwendungen
Virtualisierung
Erfahren Sie das Neueste über die Virtualisierung von Workloads in Cloud- oder On-Premise-Umgebungen