
Red Hat OpenShift Virtualization hilft, Workload-Hindernisse zu beseitigen, indem das Deployment und Management von virtuellen Maschinen (VMs) mit containerisierten Anwendungen auf cloudnative Weise vereinheitlicht wird. Als Teil des größeren Performance- und Skalierungsteams sind wir seit den Anfängen des Open Source-Projekts KubeVirt intensiv an der Messung und Analyse von VMs beteiligt, die auf OpenShift ausgeführt werden. So haben wir dazu beigetragen, die Produktreife durch Evaluierung neuer Features, Workload-Tuning und Skalierungstests zu fördern. Dieser Artikel befasst sich mit verschiedenen unserer Schwerpunktbereiche und gewährt Ihnen zusätzliche Einblicke in die Ausführung und das Tuning von VM-Workloads auf OpenShift.
Guides für Tuning und Skalierung
Unser Team trägt zur Dokumentation von Tuning und Skalierung bei, damit Kunden ihre VM-Deployments optimal nutzen können. Zunächst gibt es einen allgemeinen Tuning Guide, den Sie in diesem Knowledgebase-Artikel finden. Dieser Guide enthält Empfehlungen zur Optimierung der Virtualization Control Plane für hohe VM-Burst-Erstellungsraten und verschiedene Tuning-Optionen auf Host- und VM-Ebene zur Verbesserung der Workload-Performance.
Weiterhin haben wir eine ausführliche Referenzarchitektur veröffentlicht, die ein Beispiel für einen OpenShift-Cluster, einen Red Hat Ceph Storage-Cluster (RHCS) und Details zum Netzwerk-Tuning enthält. Außerdem werden beispielhafte VM-Deployments und Boot Storm Timings, die Performance bei Skalierung der I/O-Latenz, die VM-Migration und -Parallelität sowie die Durchführung von Cluster-Upgrades in großem Umfang untersucht.
Team-Schwerpunktbereiche
In den folgenden Abschnitten erhalten Sie einen Überblick über einige unserer Schwerpunktbereiche und Details zu den Tests, mit denen wir die Performance von VMs auf OpenShift charakterisieren und verbessern. Abbildung 1 unten zeigt unsere Schwerpunktbereiche.
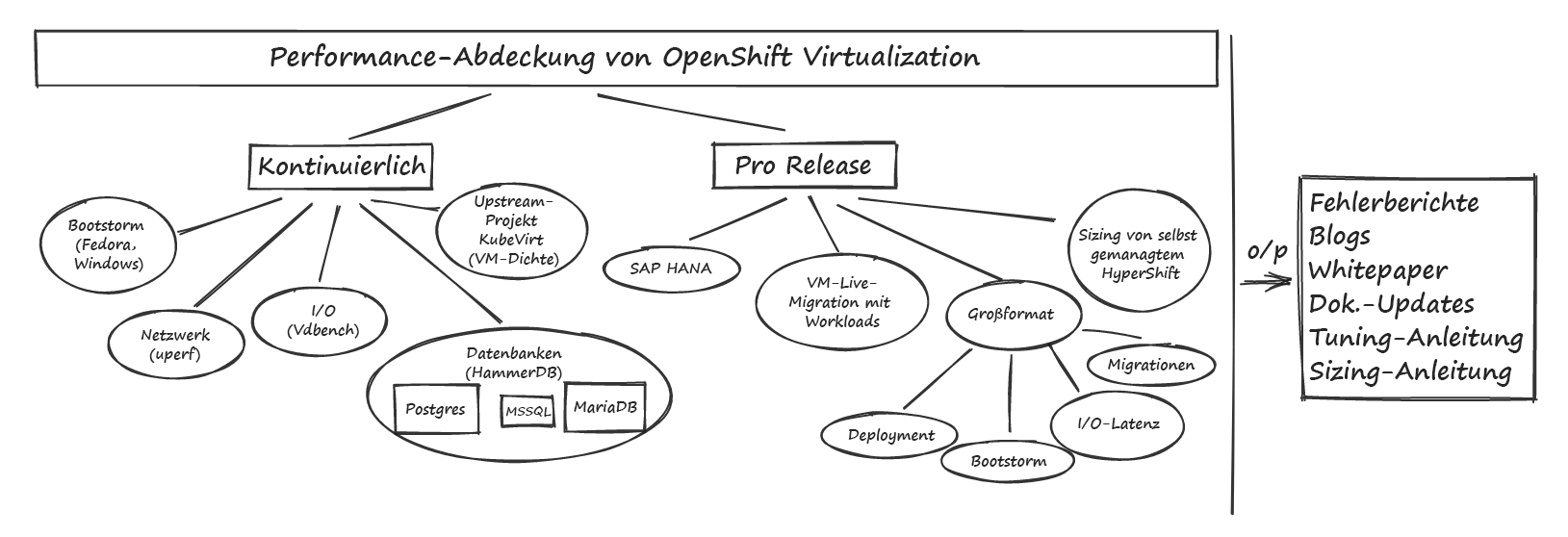
Abbildung 1: Schwerpunktbereiche der Performance von OpenShift Virtualization
Workload-Performance
Wir verbringen viel Zeit damit, uns auf wichtige Workloads zu konzentrieren, die Computing-, Netzwerk- und Storage-Komponenten umfassen, um eine breite Abdeckung zu gewährleisten. Diese Arbeit beinhaltet das Erfassen kontinuierlicher Baselines zu verschiedenen Hardwaremodellen, die Aktualisierung der Ergebnisse bei neuen Releases sowie die eingehende Prüfung verschiedener Tuning-Optionen zum Erreichen einer optimalen Performance.
Ein wichtiger Schwerpunkt bei Workloads ist die Datenbank-Performance. Wir verwenden normalerweise HammerDB als Workload-Treiber und konzentrieren uns auf mehrere Datenbanktypen, darunter MariaDB, PostgreSQL und MSSQL, um nachvollziehen zu können, wie Datenbanken mit unterschiedlichen Eigenschaften funktionieren. Diese Vorlage enthält ein Beispiel für eine HammerDB-VM-Definition.
Ein weiterer Schwerpunkt im Bereich Workloads ist SAP HANA, eine In-Memory-Datenbank mit hohem Durchsatz, deren Performance innerhalb von 10 % von Bare Metal liegen soll. Dies erreichen wir durch Isolations-Tuning sowohl auf Host- als auch auf VM-Ebene, darunter die Verwendung von CPUManager, die Anpassung der von systemd gesteuerten Prozessaffinität, die Unterstützung der VM mit Huge Pages und die Verwendung von SRIOV-Netzwerkanhängen.
Um die Storage-Performance weiter zu betrachten, führen wir eine Reihe verschiedener I/O-Anwendungsmuster aus, die sich sowohl auf IOPs (Input/Output-Vorgänge pro Sekunde) als auch auf die Latenz konzentrieren, indem wir die Vdbench-Workload verwenden. Die Anwendungsmuster variieren die Blockgröße, den I/O-Vorgangstyp, die Größe und die Anzahl der Dateien und Verzeichnisse und passen die Mischung von Lese- und Schreibvorgängen an. So können wir verschiedene I/O-Verhaltensweisen betrachten, um unterschiedliche Performance-Merkmale nachzuvollziehen. Wir führen einen weiteren gängigen Storage-Microbenchmark, Fio, zur Messung verschiedener Storage-Profile aus. Wir testen mehrere Anbieter für persistenten Storage, aber unser Hauptaugenmerk liegt auf OpenShift Data Foundation unter Verwendung von RADOS Block Device-Volumes (RBD) im Block-Modus in VMs.
Wir konzentrieren uns auch auf verschiedene Arten von Microbenchmarks, um die Performance anderer Komponenten zu bewerten und so einige dieser komplexeren Workloads abzurunden. Für Netzwerke verwenden wir in der Regel die Workload uperf, um sowohl Stream- als auch RequestResponse-Testkonfigurationen für verschiedene Nachrichtengrößen und Thread-Zählungen zu messen und uns sowohl auf das Standard-Podnetwork als auch auf andere CNI-Typen (Container Network Interface) wie Linux Bridge und zusätzliche OVN-Kubernetes-Netzwerke zu konzentrieren. Für Compute-Tests verwenden wir je nach Schwerpunktbereich verschiedene Benchmarks, darunter stress-ng, blackscholes, SPECjbb2005 und andere.
Regressionstests
Mithilfe eines Automatisierungs-Frameworks namens benchmark-runner führen wir kontinuierlich Workload-Konfigurationen aus und vergleichen die Ergebnisse mit bekannten Baselines, um Regressionen in Pre-Release-Versionen von OpenShift Virtualization zu erkennen und zu korrigieren. Da uns die Performance der Virtualisierung wichtig ist, führen wir dieses Framework für kontinuierliche Tests auf Bare Metal-Systemen aus. Wir vergleichen Workloads mit ähnlichen Konfigurationen in Pods, VMs und Sandbox-Containern, um die relative Performance zu verstehen. Diese Automatisierung ermöglicht es uns, neue Pre-Release-Versionen von OpenShift und der Operatoren, auf die wir uns konzentrieren, schnell zu installieren. Dazu zählen OpenShift Virtualization, OpenShift Data Foundation, Local Storage Operator und OpenShift Sandbox-Container. Indem wir die Performance von Pre-Release-Versionen mehrmals pro Woche charakterisieren, können wir Regressionen rechtzeitig erkennen, bevor sie für Kunden freigegeben werden. Außerdem können wir Performance-Verbesserungen im Zeitverlauf vergleichen, wenn wir auf neuere Releases mit verbesserten Funktionen aktualisieren.
Wir erweitern kontinuierlich unsere Abdeckung mit automatisierten Workloads, aber die aktuellen Workloads, die wir regelmäßig ausführen, umfassen Datenbank-Benchmarks, Compute-Microbenchmarks, uperf, Vdbench, Fio sowie VM-„Boot Storm“- und Pod-Start-Latenztests, die verschiedene Bereiche des Clusters testen und bestimmen, wie schnell eine große Anzahl von Pods oder VMs gleichzeitig gestartet werden kann.
Migrations-Performance
Ein Vorteil der Verwendung eines gemeinsamen Storage-Anbieters, der den RWX-Zugriffsmodus zulässt, besteht darin, dass VM-Workloads während Cluster-Upgrades nahtloser live migriert werden können. Wir arbeiten kontinuierlich daran, die Geschwindigkeit zu erhöhen, mit der VMs ohne wesentliche Unterbrechungen der Workloads migriert werden können. Dies beinhaltet das Testen und Empfehlen von Migrationsgrenzwerten und -richtlinien, um sichere Standardwerte bereitzustellen, sowie das Testen wesentlich höherer Grenzwerte, um Engpässe bei den Migrationskomponenten aufzudecken. Wir messen außerdem die Vorteile der Schaffung eines dedizierten Migrationsnetzwerks und analysieren Netzwerke auf Knotenebene und Metriken zur Migration pro VM, um den Migrationsfortschritt im Netzwerk zu charakterisieren.
Skalierungs-Performance
Wir testen groß angelegte Umgebungen regelmäßig, um Engpässe aufzudecken und Tuning-Optionen zu bewerten. Unsere Skalierungstests umfassen Bereiche wie Skalierung der OpenShift Control Plane, Skalierung der Virtualisierungs-Control Plane, Skalierung der Workload-I/O-Latenz, Migrationsparallelität, Klonen von DataVolumes und Tuning der VM-„Burst“-Erstellung.
Dabei haben wir verschiedene skalierungsbezogene Fehler entdeckt, die letztendlich zu Verbesserungen führten. So konnten wir die nächsten Skalierungstests noch höher ansetzen. Die Best Practices für Skalierungen, die wir dabei beobachten, dokumentieren wir in unserem allgemeinen Tuning and Scaling Guide.
Performance gehosteter Cluster
Ein neuer Schwerpunktbereich für uns ist die Performance von gehosteten Control Planes und gehosteten Clustern. Dabei prüfen wir insbesondere gehostete On-Premise Bare Metal Control Planes und gehostete Cluster auf OpenShift Virtualization, das den KubeVirt-Cluster-Anbieter verwendet.
Einige unserer anfänglichen Arbeitsbereiche sind Skalierungstests mehrerer Instanzen von etcd (siehe die Storage-Empfehlung im Abschnitt Important), Skalierungstests gehosteter Control Planes mit hohen API-Workloads und Performance gehosteter Workloads bei der Verwaltung von gehosteten Control Plane-Clustern auf OpenShift Virtualization. Lesen Sie unsere Anleitung zum Sizing gehosteter Cluster, um eines der wichtigsten Ergebnisse dieser aktuellen Arbeit kennenzulernen.
Wie geht's weiter
Achten Sie auf zukünftige Beiträge, die diese Performance- und Skalierungsbereiche genauer behandeln, einschließlich eines tieferen Einblicks in die Methodik des Sizings gehosteter Cluster und detaillierter Empfehlungen zum Tuning der VM-Migration.
In der Zwischenzeit werden wir die Performance von VMs auf OpenShift weiter messen und analysieren, neue Skalierungsgrenzen verschieben und uns darauf konzentrieren, Regressionen zu erkennen und zu korrigieren, bevor Releases in die Hände unserer Kunden gelangen!
Über den Autor

Jenifer joined Red Hat in 2018 and leads the OpenShift Virtualization Performance team. Previously, she spent a decade working at IBM in the Linux Technology Center focused on Linux Performance.
Nach Thema durchsuchen

Automatisierung
Das Neueste zum Thema IT-Automatisierung für Technologien, Teams und Umgebungen

Künstliche Intelligenz
Erfahren Sie das Neueste von den Plattformen, die es Kunden ermöglichen, KI-Workloads beliebig auszuführen

Open Hybrid Cloud
Erfahren Sie, wie wir eine flexiblere Zukunft mit Hybrid Clouds schaffen.

Sicherheit
Erfahren Sie, wie wir Risiken in verschiedenen Umgebungen und Technologien reduzieren

Edge Computing
Erfahren Sie das Neueste von den Plattformen, die die Operations am Edge vereinfachen

Infrastruktur
Erfahren Sie das Neueste von der weltweit führenden Linux-Plattform für Unternehmen

Anwendungen
Entdecken Sie unsere Lösungen für komplexe Herausforderungen bei Anwendungen

Original Shows
Interessantes von den Experten, die die Technologien in Unternehmen mitgestalten
Produkte
- Red Hat Enterprise Linux
- Red Hat OpenShift
- Red Hat Ansible Automation Platform
- Cloud-Services
- Alle Produkte anzeigen
Tools
- Training & Zertifizierung
- Eigenes Konto
- Kundensupport
- Für Entwickler
- Partner finden
- Red Hat Ecosystem Catalog
- Mehrwert von Red Hat berechnen
- Dokumentation
Testen, kaufen und verkaufen
Kommunizieren
Über Red Hat
Als weltweit größter Anbieter von Open-Source-Software-Lösungen für Unternehmen stellen wir Linux-, Cloud-, Container- und Kubernetes-Technologien bereit. Wir bieten robuste Lösungen, die es Unternehmen erleichtern, plattform- und umgebungsübergreifend zu arbeiten – vom Rechenzentrum bis zum Netzwerkrand.
Wählen Sie eine Sprache
Red Hat legal and privacy links
- Über Red Hat
- Jobs bei Red Hat
- Veranstaltungen
- Standorte
- Red Hat kontaktieren
- Red Hat Blog
- Diversität, Gleichberechtigung und Inklusion
- Cool Stuff Store
- Red Hat Summit