
Red Hat OpenShift Virtualization は、仮想マシン (VM) のデプロイと管理をコンテナ化アプリケーションとともにクラウドネイティブな方法で統合することで、ワークロードの障壁を除去するのに役立ちます。私たちはより大規模なパフォーマンスおよびスケールチームの一員として、KubeVirt オープンソース・プロジェクトの黎明期から、OpenShift 上で実行される VM の測定と分析に深く関わり、新機能の評価、ワークロードの調整、スケールテストの実施を通じて製品の成熟度の向上を支援してきました。この記事では、私たちが注力している領域をいくつかご紹介し、OpenShift での VM ワークロードの実行とチューニングに関する追加の知見を共有します。
チューニングとスケーリングのガイド
私たちのチームは、お客様が VM デプロイメントを最大限に活用できるよう、チューニングとスケーリングのドキュメントに貢献しています。まず、全体的なチューニングガイドがあります。このナレッジベース記事で参照できます。このガイドでは、VM の「バースト」高速作成を行うための仮想化コントロールプレーン最適化と、ワークロードのパフォーマンスを向上させるためにホストレベルおよび VM レベルの両方で行えるさまざまなチューニングオプションに関する推奨事項について解説しています。
次に、詳細なリファレンスアーキテクチャを公開しました。これには、OpenShift クラスタのサンプル、Red Hat Ceph Storage (RHCS) クラスタとネットワークチューニングの詳細が含まれています。また、サンプルの VM デプロイとブートストームのタイミング、I/O レイテンシースケーリングのパフォーマンス、VM の移行と並列処理、大規模なクラスタアップグレードの実行についても解説します。
チームが注力している領域
以下のセクションでは、私たちの注力している主な領域の概要と、OpenShift で実行される VM のパフォーマンスの特性を確認し、改善するために行っているテストの詳細について説明します。以下の図 1 は私たちが注力している領域を示しています。
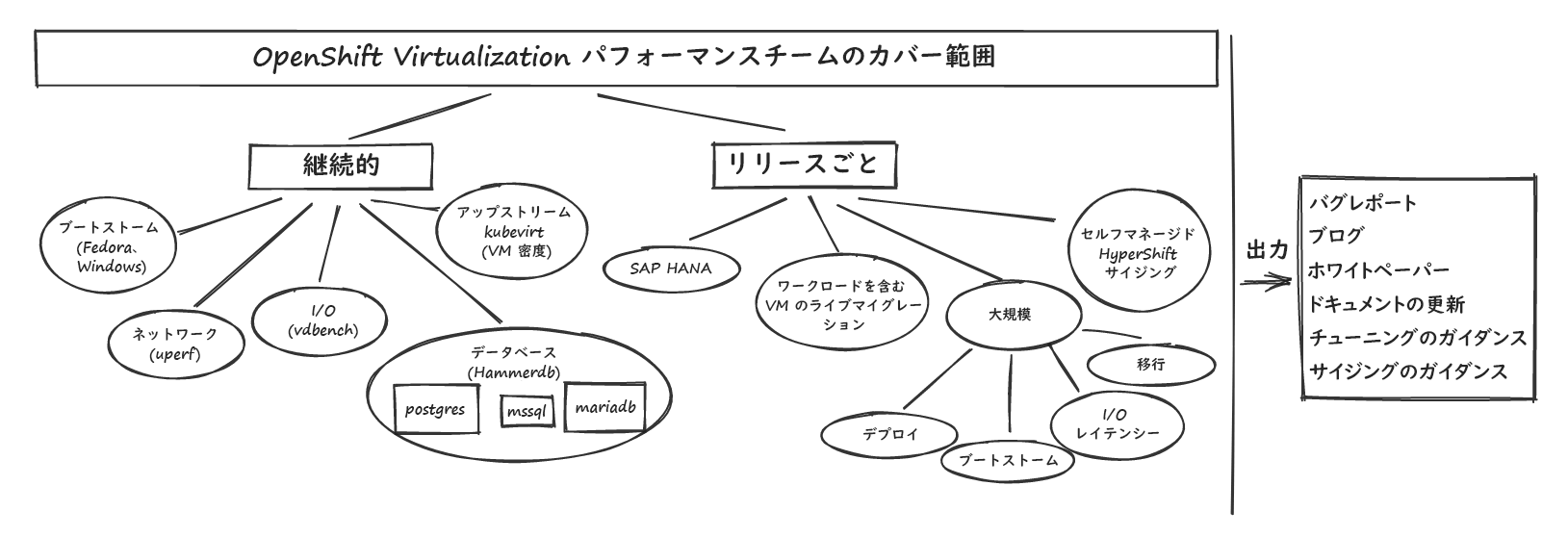
図 1:OpenShift Virtualization パフォーマンスが注力している領域
ワークロードのパフォーマンス
私たちは幅広いカバレッジを確保できるよう、コンピューティング、ネットワーキング、およびストレージの各コンポーネントをカバーする主要なワークロードに重点的に取り組み、多くの時間を費やしています。この作業には、さまざまなハードウェアモデルから継続的にベースラインを収集し、新しいリリースがリリースされたら結果を更新し、最適なパフォーマンスを実現するためにさまざまなチューニングオプションを詳細に調査することが含まれます。
特に注力しているワークロードの領域の 1 つに、データベースのパフォーマンスがあります。さまざまな特性を持つデータベースがどのようなパフォーマンスを発揮するかを理解できるよう、私たちは通常、HammerDB をワークロードドライバーとして使用し、MariaDB、PostgreSQL、MSSQL などの複数のデータベースタイプに焦点を当てています。このテンプレートは、HammerDB VM の定義のサンプルです。
注力しているもう 1 つの主なワークロードの領域は、高スループットのインメモリデータベースである SAP HANA で、ベアメタルの 10% 以内のパフォーマンスを目標としています。これを実現するには、CPUManager の使用、 systemd によって制御されるプロセスアフィニティの調整、 Hugepage による VM の補助、SRIOV ネットワーク・アタッチメントの使用など、ホストレイヤーと VM レイヤーの両方に分離スタイルのチューニングを適用します。
ストレージのパフォーマンスをさらにカバーするために、Vdbench ワークロードを使用して、IOPS (1 秒あたりの入出力操作) とレイテンシーの両方に焦点を当てたさまざまな I/O アプリケーションパターンを実行します。アプリケーションパターンでは、ブロックサイズ、I/O 操作タイプ、ファイルとディレクトリのサイズと数を変更し、読み取りと書き込みの組み合わせを調整します。これにより、さまざまな I/O 動作をカバーし、さまざまなパフォーマンス特性を理解することができます。また、別の一般的なストレージ・マイクロベンチマークである Fio を実行し、さまざまなストレージプロファイルを測定します。複数の永続ストレージプロバイダーをテストしていますが、特に注力しているのは、VM でブロック モードの RADOS ブロックデバイス (RBD) ボリュームを使用する OpenShift Data Foundation です。
また、さまざまなタイプのマイクロベンチマークに焦点を当て、より複雑なワークロードの一部を実行する他のコンポーネントのパフォーマンスを評価します。ネットワーキングについては、通常 uperf ワークロードを使用して、さまざまなメッセージサイズとスレッド数に対する Stream と RequestResponse の両方のテスト構成を測定します。その際には、デフォルトの podnetwork と他のコンテナ・ネットワーク・インタフェース (CNI) タイプ (Linux Bridge や OVN-Kubernetes 追加ネットワークなど) の両方に注目します。コンピューティングに関するテストでは、注力する分野に応じて、stress-ng、blackscholes、SPECjbb2005 などのさまざまなベンチマークを使用します。
回帰テスト
私たちは、benchmark-runner と呼ばれる自動化フレームワークを使用して、ワークロード構成を継続的に実行し、その結果を既知のベースラインと比較して、OpenShift Virtualization のプレリリースバージョンでリグレッションを検出して修正しています。仮想化のパフォーマンスを重視しているので、この継続的テストフレームワークをベアメタルシステムで実行しています。Pod、VM、およびサンドボックスコンテナ で、同様の構成のワークロードを比較して、相対的なパフォーマンスを理解できるようにしています。この自動化により、OpenShift の新しいプレリリースバージョンや、OpenShift Virtualization、OpenShift Data Foundation、Local Storage Operator、OpenShift サンドボックスコンテナなどの、注力している Operator を、迅速にインストールできます。プレリリースバージョンのパフォーマンスを毎週複数回測定することで、お客様にリリースされる前の早期段階でリグレッションを把握でき、機能が改善された新しいリリースに更新した際のパフォーマンスの向上を経時的に比較できます。
自動化された継続的なワークロードのカバーする範囲は常に拡大していますが、定期的に実行する現在のワークロードセットには、データベース・ベンチマーク、コンピューティング・マイクロベンチマーク、uperf、Vdbench、Fio、および VM の「ブートストーム」テストと Pod 起動レイテンシーテストの両方が含まれており、 クラスタのさまざまな領域を対象に、大量の Pod や VM を一度に起動する速度を測定します。
移行のパフォーマンス
RWX アクセスモードを許可する共有ストレージプロバイダーを使用する利点の 1 つは、クラスタのアップグレード中に VM ワークロードをよりシームレスにライブマイグレーションできることです。私たちは、ワークロードを大幅に中断させることなく VM を移行するスピードの向上に一貫して取り組んでいます。これには、安全なデフォルト値を提供し、はるかに高い制限をテストして移行コンポーネントのボトルネックを明らかにするための、移行の制限とポリシーのテストと推奨が含まれます。また、ネットワーク経由で行う移行の進行状況の特徴を把握するため、専用の移行ネットワークを作成することのメリットを測定し、ノードレベルのネットワーキングと VM ごとの移行メトリクスを分析します。
スケーリングのパフォーマンス
私たちは、ボトルネックを明らかにし、チューニングオプションを評価するために、定期的に大規模な環境をテストしています。スケールテストの分野は、OpenShift コントロールプレーンのスケーリングから、Virtualization コントロールプレーンのスケーリング、ワークロード I/O レイテンシーのスケーリング、移行の並行処理、DataVolume のクローニング、VM の「バースト」作成の調整にまで及びます。
このテストを通じて、スケーリングに関連するさまざまなバグが発見され、最終的には改善につながり、スケールテストの次のラウンドをさらに前進させることができました。この過程で判明したスケーリング関連のベストプラクティスは、一般的なチューニングおよびスケーリングガイドに記載されています。
ホスト型クラスタのパフォーマンス
新しい注力分野となっているのが、ホスト型コントロールプレーンとホスト型クラスタのパフォーマンスです。具体的には、オンプレミスのベアメタルでホストされるコントロールプレーンと、KubeVirt クラスタプロバイダーを使用する OpenShift Virtualization でホストされるクラスタを調査しています。
最初の作業分野としては、etcd の複数インスタンスのスケールテスト (重要セクションのストレージに関する推奨事項を参照)、API の負荷が高い場合のホスト型コントロールプレーンのスケールテスト、OpenShift Virtualization 上でホスト型コントロールプレーン・クラスタを管理する際のホスト型ワークロードのパフォーマンスなどがあります。この最近の取り組みの主な成果は、ホスト型クラスタのサイジング方法に関するガイダンスをご覧ください。
次のステップ
今後の投稿では、ホスト型クラスタのサイジングに関するガイダンス方法や、VM 移行の詳細なチューニング推奨事項など、パフォーマンスとスケーリングの領域についてさらに詳しく紹介する予定です。ご期待ください。
その間も、引き続き OpenShift 上で VM のパフォーマンスの測定と分析を行って、スケールの限界を押し広げ、リリースがお客様の手に渡る前にリグレッションを把握して修正できるよう注力します。
執筆者紹介

Jenifer joined Red Hat in 2018 and leads the OpenShift Virtualization Performance team. Previously, she spent a decade working at IBM in the Linux Technology Center focused on Linux Performance.
チャンネル別に見る

自動化
テクノロジー、チームおよび環境に関する IT 自動化の最新情報

AI (人工知能)
お客様が AI ワークロードをどこでも自由に実行することを可能にするプラットフォームについてのアップデート

オープン・ハイブリッドクラウド
ハイブリッドクラウドで柔軟に未来を築く方法をご確認ください。

セキュリティ
環境やテクノロジー全体に及ぶリスクを軽減する方法に関する最新情報

エッジコンピューティング
エッジでの運用を単純化するプラットフォームのアップデート

インフラストラクチャ
世界有数のエンタープライズ向け Linux プラットフォームの最新情報

アプリケーション
アプリケーションの最も困難な課題に対する Red Hat ソリューションの詳細

オリジナル番組
エンタープライズ向けテクノロジーのメーカーやリーダーによるストーリー
製品
ツール
試用、購入、販売
コミュニケーション
Red Hat について
エンタープライズ・オープンソース・ソリューションのプロバイダーとして世界をリードする Red Hat は、Linux、クラウド、コンテナ、Kubernetes などのテクノロジーを提供しています。Red Hat は強化されたソリューションを提供し、コアデータセンターからネットワークエッジまで、企業が複数のプラットフォームおよび環境間で容易に運用できるようにしています。
言語を選択してください
Red Hat legal and privacy links
- Red Hat について
- 採用情報
- イベント
- 各国のオフィス
- Red Hat へのお問い合わせ
- Red Hat ブログ
- ダイバーシティ、エクイティ、およびインクルージョン
- Cool Stuff Store
- Red Hat Summit