
Red Hat OpenShift Virtualization aiuta a eliminare gli ostacoli ai carichi di lavoro unificando il deployment e la gestione delle macchine virtuali (VM) in associazione alle applicazioni containerizzate con un approccio cloud native. Facendo parte del più ampio team Performance and Scale, siamo stati profondamente coinvolti nella misurazione e nell'analisi delle VM in esecuzione su OpenShift sin dall'inizio del progetto open source KubeVirt e abbiamo contribuito a promuovere la maturità dei prodotti attraverso la valutazione delle nuove funzionalità, l'ottimizzazione dei carichi di lavoro e i test di scalabilità. Questo articolo approfondisce alcune delle nostre aree di interesse e fornisce informazioni aggiuntive sull'esecuzione e ottimizzazione dei carichi di lavoro delle macchine virtuali su OpenShift.
Guide all'ottimizzazione e alla scalabilità
Il nostro team contribuisce all'ottimizzazione e alla scalabilità della documentazione per aiutare i clienti a ottenere il massimo dai deployment delle macchine virtuali. In primo luogo, abbiamo una guida generale all'ottimizzazione, consultabile in questo articolo della knowledge base. Questa guida fornisce suggerimenti per l'ottimizzazione del piano di controllo della virtualizzazione per aumentare le velocità di creazione "burst" delle VM e varie opzioni di ottimizzazione a livello di host e VM per migliorare le prestazioni dei carichi di lavoro.
In secondo luogo, abbiamo pubblicato un'architettura di riferimento approfondita che include un cluster OpenShift di esempio, un cluster Red Hat Ceph Storage (RHCS) e dettagli sull'ottimizzazione della rete. Inoltre, questa architettura esamina le tempistiche di deployment e boot storm delle VM, le prestazioni di scalabilità della latenza I/O, la migrazione e il parallelismo delle VM e l'esecuzione di upgrade dei cluster su larga scala.
Aree di interesse del team
Le sezioni seguenti forniscono una panoramica di alcune delle nostre principali aree di interesse e dettagli sui test che eseguiamo per caratterizzare e migliorare le prestazioni delle macchine virtuali eseguite su OpenShift. La Figura 1 illustra le nostre aree di interesse.
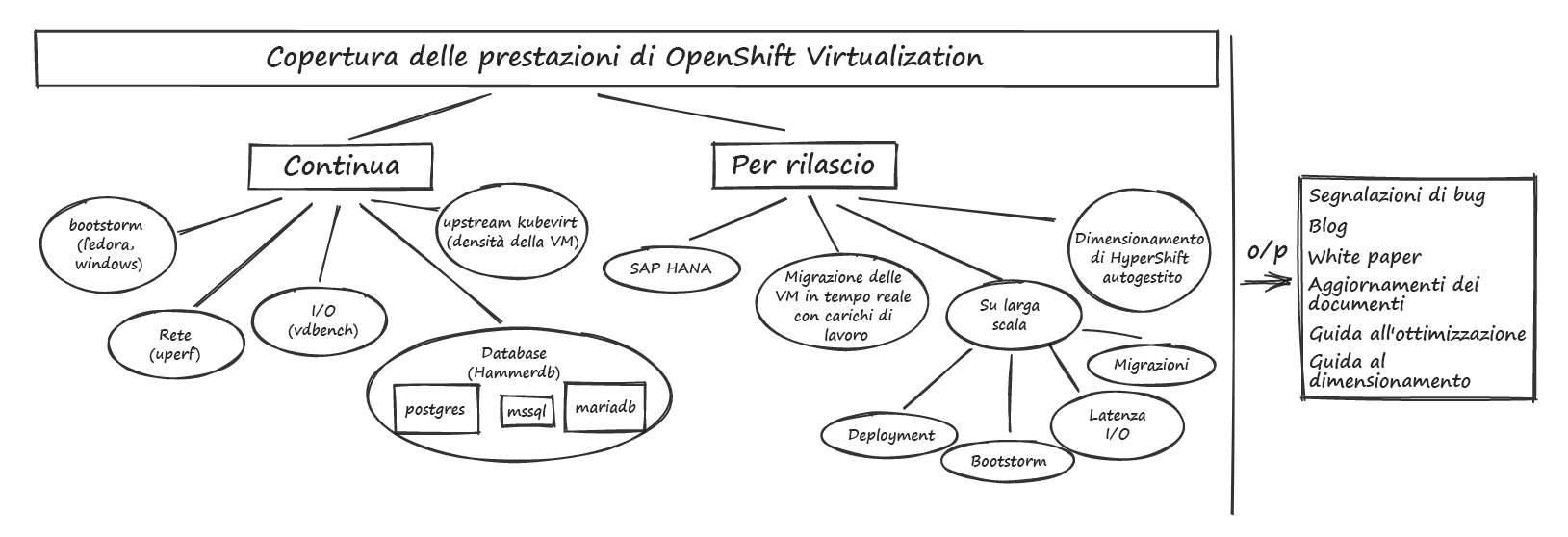
Figura 1: aree di interesse per OpenShift Virtualization Performance
Prestazioni dei carichi di lavoro
Dedichiamo molto tempo ai carichi di lavoro principali che riguardano i componenti di elaborazione, rete e storage per assicurarci di avere un'ampia copertura. Questo lavoro include la raccolta di baseline continue su diversi modelli hardware, l'aggiornamento dei risultati man mano che escono nuove versioni e l'approfondimento delle varie opzioni di ottimizzazione per ottenere prestazioni eccellenti.
Una delle principali aree di interesse dei carichi di lavoro sono le prestazioni del database. In genere utilizziamo HammerDB come driver del carico di lavoro e ci concentriamo su più tipi di database, tra cui MariaDB, PostgreSQL e MSSQL, in modo da poter comprendere le prestazioni di database con caratteristiche diverse. Questo modello fornisce un esempio di definizione di VM HammerDB.
Un'altra importante area di interesse per i carichi di lavoro è SAP HANA, un database in memory a produttività elevata, con l'obiettivo di ottenere prestazioni inferiori al 10% per il bare metal. Per ottenere questo risultato, abbiamo applicato alcune ottimizzazioni dello stile di isolamento sia a livello dell'host che della VM, tra cui l'uso di CPUManager, la regolazione dell'affinità di processo controllata da systemd, il supporto della VM con grandi pagine e l'uso di collegamenti di rete SRIOV.
Per andare più a fondo sulle prestazioni dello storage, eseguiamo una serie di modelli applicativi di I/O diversi incentrati sia sulle operazioni di input/output al secondo (IOPS) sia sulla latenza utilizzando il carico di lavoro Vdbench. I modelli applicativi variano in base alla dimensione del blocco, al tipo di operazione di I/O, alla dimensione e al numero di file e directory e regolano la combinazione di lettura e scrittura. Questo ci consente di coprire vari comportamenti di I/O per comprendere le diverse caratteristiche delle prestazioni. Eseguiamo anche un altro microbenchmark di storage comune, Fio, per misurare vari profili di storage. Testiamo diversi provider di storage permanente, ma ci concentriamo soprattutto su OpenShift Data Foundation, utilizzando volumi di dispositivi a blocchi RADOS (RBD) in modalità blocco nelle VM.
Ci dedichiamo anche a diversi tipi di microbenchmark per valutare le prestazioni di altri componenti con lo scopo di arricchire alcuni di questi carichi di lavoro più complessi. Per le reti, in genere utilizziamo il carico di lavoro uperf per misurare le configurazioni di test Stream e RequestResponse per varie dimensioni dei messaggi e conteggi di thread, concentrandoci sia sul podnetwork predefinito che su altri tipi di container network interface (CNI), come Linux Bridge e reti aggiuntive OVN Kubernetes. Per i test di elaborazione utilizziamo diversi benchmark, come stress-ng, blackscholes, SPECjbb2005 e altri, a seconda dell'area di interesse.
Test di regressione
Utilizzando un framework di automazione chiamato benchmark-runner, eseguiamo continuamente le configurazioni dei carichi di lavoro e confrontiamo i risultati con le baseline note per rilevare e correggere eventuali regressioni nelle versioni pre-rilascio di OpenShift Virtualization. Dato che teniamo molto alle prestazioni della virtualizzazione, eseguiamo questo framework di test continui su sistemi bare metal. Confrontiamo i carichi di lavoro con configurazioni simili tra pod, VM e container sandbox per comprendere meglio le prestazioni relative. Questa automazione ci consente di installare rapidamente le nuove versioni pre-rilascio di OpenShift e degli operatori su cui ci concentriamo, tra cui OpenShift Virtualization, OpenShift Data Foundation, Local Storage Operator e i container sandbox di OpenShift. Analizzando le prestazioni delle versioni pre-rilascio più volte alla settimana riusciamo a rilevare eventuali regressioni prima che vengano rilasciate ai clienti. Questo ci consente di confrontare i miglioramenti delle prestazioni nel tempo man mano che aggiorniamo alle versioni più recenti con funzionalità migliorate.
La nostra copertura continua dei carichi di lavoro automatizzati è in costante espansione, ma l'attuale set di carichi di lavoro che eseguiamo regolarmente include benchmark di database, microbenchmark di elaborazione, uperf, Vdbench, Fio e test di latenza di avvio di pod e di "boot storm" delle VM che analizzano varie aree del cluster per misurare la velocità con cui è possibile avviare contemporaneamente un certo numero di pod o VM in blocco.
Prestazioni di migrazione
Uno dei vantaggi dell'utilizzo di un provider di storage condiviso che consente la modalità di accesso RWX è che i carichi di lavoro delle VM possono eseguire la migrazione in tempo reale più agevolmente durante gli upgrade dei cluster. Lavoriamo costantemente per migliorare la velocità di migrazione delle VM senza interruzioni significative dei carichi di lavoro, ad esempio testando e consigliando limiti e criteri di migrazione per fornire valori predefiniti sicuri e testando limiti molto più elevati per scoprire gli ostacoli per i componenti della migrazione. Inoltre, valutiamo i vantaggi della creazione di una rete di migrazione dedicata e analizziamo le metriche di rete a livello di nodo e la migrazione per VM per descrivere l'avanzamento della migrazione sulla rete.
Prestazioni di scalabilità
Testiamo regolarmente ambienti su larga scala per individuare eventuali ostacoli e valutare le opzioni di ottimizzazione. I nostri test di scalabilità riguardano aree che vanno dalla scalabilità del piano di controllo di OpenShift a quella di virtualizzazione, dalla scalabilità della latenza I/O dei carichi di lavoro al parallelismo della migrazione, dalla clonazione di DataVolume all'ottimizzazione della creazione "burst" delle VM.
Nel corso di questi test, abbiamo scoperto vari bug relativi alla scalabilità che hanno portato a miglioramenti, consentendoci di spingere ancora più in là il ciclo di test di scalabilità successivo. Tutte le procedure consigliate relative alla scalabilità sono documentate nella nostra guida all'ottimizzazione e alla scalabilità.
Prestazioni dei cluster in hosting
Un'area di interesse emergente per noi è il piano di controllo in hosting e le prestazioni dei cluster in hosting, esaminando in particolare i piani di controllo ospitati su bare metal on premise e i cluster ospitati su OpenShift Virtualization, che utilizza il provider di cluster KubeVirt.
Alcune delle nostre aree di lavoro iniziali sono il test di scalabilità di più istanze di etcd (consulta i consigli per lo storage nella sezione Important), il test di scalabilità del piano di controllo in hosting con grandi carichi di lavoro API e le prestazioni dei carichi di lavoro in hosting durante la gestione dei cluster del piano di controllo in hosting su OpenShift Virtualization. Consulta la nostra guida al dimensionamento dei cluster in hosting per scoprire uno dei principali risultati di questo recente lavoro.
Passaggi successivi
Non perderti i prossimi post che tratteranno in modo più dettagliato prestazioni e scalabilità, oltre a un'analisi più approfondita della metodologia di orientamento per il dimensionamento dei cluster in hosting e consigli approfonditi sull'ottimizzazione della migrazione delle VM.
Nel frattempo, continueremo a misurare e analizzare le prestazioni delle VM su OpenShift, spingendoci oltre i limiti di scalabilità e concentrandoci sull'individuazione e la correzione di eventuali regressioni prima che i rilasci arrivino ai nostri clienti.
Sull'autore

Jenifer joined Red Hat in 2018 and leads the OpenShift Virtualization Performance team. Previously, she spent a decade working at IBM in the Linux Technology Center focused on Linux Performance.
Ricerca per canale

Automazione
Novità sull'automazione IT di tecnologie, team e ambienti

Intelligenza artificiale
Aggiornamenti sulle piattaforme che consentono alle aziende di eseguire carichi di lavoro IA ovunque

Hybrid cloud open source
Scopri come affrontare il futuro in modo più agile grazie al cloud ibrido

Sicurezza
Le ultime novità sulle nostre soluzioni per ridurre i rischi nelle tecnologie e negli ambienti

Edge computing
Aggiornamenti sulle piattaforme che semplificano l'operatività edge

Infrastruttura
Le ultime novità sulla piattaforma Linux aziendale leader a livello mondiale

Applicazioni
Approfondimenti sulle nostre soluzioni alle sfide applicative più difficili

Serie originali
Raccontiamo le interessanti storie di leader e creatori di tecnologie pensate per le aziende
Prodotti
- Red Hat Enterprise Linux
- Red Hat OpenShift
- Red Hat Ansible Automation Platform
- Servizi cloud
- Scopri tutti i prodotti
Strumenti
- Formazione e certificazioni
- Il mio account
- Supporto clienti
- Risorse per sviluppatori
- Trova un partner
- Red Hat Ecosystem Catalog
- Calcola il valore delle soluzioni Red Hat
- Documentazione
Prova, acquista, vendi
Comunica
- Contatta l'ufficio vendite
- Contatta l'assistenza clienti
- Contatta un esperto della formazione
- Social media
Informazioni su Red Hat
Red Hat è leader mondiale nella fornitura di soluzioni open source per le aziende, tra cui Linux, Kubernetes, container e soluzioni cloud. Le nostre soluzioni open source, rese sicure per un uso aziendale, consentono di operare su più piattaforme e ambienti, dal datacenter centrale all'edge della rete.
Seleziona la tua lingua
Red Hat legal and privacy links
- Informazioni su Red Hat
- Opportunità di lavoro
- Eventi
- Sedi
- Contattaci
- Blog di Red Hat
- Diversità, equità e inclusione
- Cool Stuff Store
- Red Hat Summit