
C'è stato un enorme aumento della domanda per l'esecuzione di sistemi complessi con decine o centinaia di microservizi su larga scala. In uno scenario in cui gli utenti finali si aspettano una disponibilità 24 ore su 24, 7 giorni su 7 dei servizi da cui dipendono, anche pochi minuti di downtime contano. L'ingegneria proattiva del caos aiuta a soddisfare le aspettative identificando gli ostacoli e rafforzando i servizi prima che si verifichino downtime in un ambiente di produzione. Si tratta di una caratteristica fondamentale anche per non perdere la fiducia degli utenti finali.
Per realizzare una piattaforma Kubernetes resiliente e offrire un'esperienza migliorata, Red Hat collabora con la community open source e con gli utenti finali per creare e gestire strumenti open source e framework di ingegneria del caos come Krkn. Per avere un'idea delle capacità di questa soluzione, ecco alcune risorse aggiuntive per approfondire e visualizzare i risultati delle operazioni di chaos testing.
Con l'adozione di Krkn per un gran numero di prodotti da parte della community e dei clienti, ci siamo trovati di fronte a sfide in cui l'intelligenza artificiale (IA) si è rivelata utile:
- Aggiunta e aggiornamento degli scenari di test, man mano che i prodotti implementano nuove funzionalità e correzioni.
- Aggiunta e mantenimento della copertura delle soluzioni di chaos testing per più prodotti, che richiede quindi un monitoraggio accurato.
- Esecuzione di centinaia di scenari di test, anziché solo di quelli con un'elevata probabilità di interruzione percepita.
I team di Red Hat Chaos Engineering e IBM Research lavorano insieme per integrare l'IA in Krkn e migliorare e automatizzare la copertura per scalare le attività di chaos testing su più prodotti che eseguono architetture, scalabilità dei nodi e modelli di traffico diversi.
Scenario di utilizzo dell'integrazione dell'IA in Krkn
Krkn viene sempre più utilizzato per attività di chaos testing su vari prodotti e configurazioni, quindi le operazioni di test sono diventate complesse. Supponiamo, ad esempio, di disporre di uno stack di applicazioni con numerosi deployment e pod che devono essere coordinati per soddisfare le richieste degli utenti. Per eseguire un'attività di chaos testing, è necessario comprendere l'architettura e progettare i test in base alla natura del servizio (modelli di dipendenza di un microservizio su uno o più altri servizi oppure CPU/CPU ad alta intensità di risorse, memoria, operazioni di input/output al secondo, rete o modelli di traffico e così via).
A tal fine, è necessario eseguire centinaia di iterazioni di test, che richiedono molte ore di lavoro e potenziali costi per il cloud. Oltre a questo, è necessario un monitoraggio costante per individuare eventuali edge case mancanti e adattare i test all'evoluzione dello stack (funzionalità aggiunte, modifiche all'architettura e così via). Quando viene eseguito su più pod, è difficile prevedere la combinazione di scenari, che può portare al non raggiungimento degli obiettivi del livello di servizio (SLO) e al degrado delle prestazioni, con ripercussioni sul servizio stesso.
Moltiplica tutto questo per tantissimi prodotti e applicazioni. Puoi risolvere questo problema con Chaos AI su Krkn. Questo è un classico esempio di come l'IA può adattarsi, aumentare le capacità e risolvere problemi complessi.
L'obiettivo è che il framework distribuito Chaos AI su Krkn rilevi ed esegua automaticamente gli scenari che influiscono sul servizio e utilizzi anche il machine learning per adattarsi ulteriormente alle modifiche allo stack.
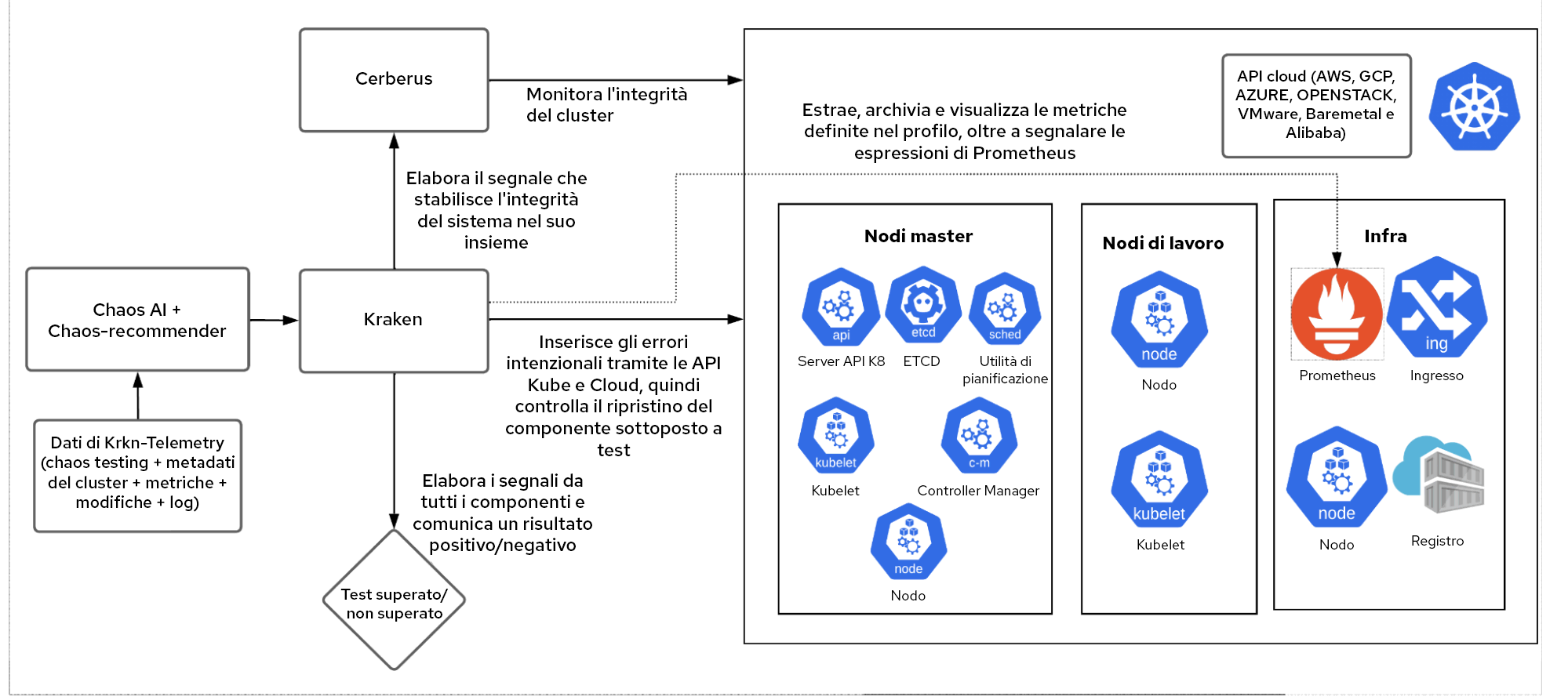
Krkn
Krkn è un motore di chaos testing in grado di indirizzare cloud, Kubernetes e API OpenShift per inserire le condizioni di errore e tenere traccia del ripristino del componente di destinazione, dell'integrità generale del cluster e degli SLO delle prestazioni.
Chaos-Recommender
Indicando un servizio, Chaos-Recommender profila ogni pod utilizzando Prometheus per capire se sta utilizzando molto la rete o se è correlato a CPU, memoria o I/O e suggerisce a Krkn gli scenari che hanno la più alta probabilità di causare interruzioni.
Krkn Telemetry
Se abilitato, Krkn Telemetry acquisisce e archivia metriche, avvisi, parametri di relativi a chaos testing, test superati o no e registri, oltre ai dettagli dell'ambiente come la scalabilità (numero di nodi, pod, percorsi e così via), l'architettura (AMD, ARM, X86_64), plugin di rete (SDN, OVN) e altro ancora. Questi dati vengono utilizzati per addestrare il modello AI/ML per capire quali componenti riportano spesso errori in modo da poterli sottoporre a più test.
Flusso di lavoro di Chaos AI
È il framework end-to-end che utilizza gli scenari Krkn e gli SLO come input e, con l'aiuto di Chaos-Recommender e Krkn-Telemetry, stabilisce quali componenti richiedono test ed esegue diverse combinazioni di scenari sullo stack.
Ecco un esempio di flusso di lavoro per Etcd e ApiServer:
Passaggio 1
Un utente fornisce gli spazi dei nomi Etcd e ApiServer come destinazione e SLO che l'IA può controllare e segnalare in caso di errori. Ad esempio:
openshift-etcdeopenshift-apiserversono gli input dello spazio dei nomi- Il server API ha una latenza del 99% inferiore a un secondo
- Lo SLO prevede che Etcd scelga nodi leader un numero di volte inferiore a 0
Passaggio 2
Chaos-AI attiva Chaos-Recommender, che profila gli spazi dei nomi Etcd e ApiServer per identificare gli scenari di chaos testing che hanno una più alta probabilità di subire interruzioni in base alle metriche di utilizzo delle risorse in Prometheus.
Passaggio 3
Il modello Chaos-AI viene addestrato utilizzando il machine learning. Vengono raccolti i dati di Krkn-Telemetry sui componenti Etcd e ApiServer per determinare quali pod e container presentano errori frequenti.
Passaggio 4
Chaos-AI assegna un peso in base ai passaggi 2 e 3 ed esegue gli scenari Krkn. Il machine learning prevede un sistema in cui il framework si segnala gli SLO mancati. In questo esempio, questo si verifica quando la latenza dell'API è maggiore di un secondo e Etcd sceglie il nodo leader.
Gestisce anche altre aree che dovrebbero subire meno interruzioni, ma con meno iterazioni. Supponiamo ad esempio che un nuovo componente o una nuova combinazione non funzionino spesso. Questi dati vengono registrati in Krkn-Telemetry e inviati al modello, in modo che siano presi in considerazione per le successive iterazioni.
Passaggio 5
Gli errori vengono visualizzati per consentirti di risolverli.
Si tratta di un processo continuo che si adatta all'evoluzione del prodotto e identifica le aree di miglioramento senza l'intervento umano in presenza di potenziali edge case mancanti.
Scenari di utilizzo
Anziché identificare e aggiungere manualmente i test nel miglioramento continuo di rilascio del prodotto, è possibile utilizzare questo framework per identificare, eseguire e persino modificare automaticamente non solo i componenti di destinazione, ma anche i nuovi componenti.
Inoltre, puoi facilmente aggiungere, scalare ed espandere la copertura dei test non solo per Red Hat OpenShift, ma per l'intero portafoglio, come Red Hat OpenShift Service on AWS, Red Hat OpenShift AI e altro ancora.
Qual è la prossima mossa?
L'integrazione di Krkn e Chaos AI ti aiuta ad ampliare la copertura dei test. Aumenta la fiducia nei prodotti e nell'ambiente e consente agli utenti di scalare più rapidamente aumentando il numero di prodotti e stack di applicazioni che possono testare.
Continua a seguirci per scoprire come è andata l'integrazione nei prossimi articoli del blog. Come puoi vedere, alcuni dei componenti, tra cui Krkn, Chaos-Recommender e Krkn-Telemetry, sono già open source e possono essere utilizzati per testare e rafforzare il tuo ambiente. Stiamo lavorando attivamente per rendere open source l'intero framework Chaos AI + Krkn e siamo sempre felici di ricevere commenti e contributi. Il codice si trova su Github e, ovviamente, siamo lieti di discutere e collaborare per adattare queste soluzioni ai tuoi scenari di utilizzo.
Sugli autori

Naga Ravi Chaitanya Elluri leads the Chaos Engineering efforts at Red Hat with a focus on improving the resilience, performance and scalability of Kubernetes and making sure the platform and the applications running on it perform well under turbulent conditions. His interest lies in the cloud and distributed computing space and he has contributed to various open source projects.

Mudit Verma is a Senior Research Engineer at Cloud Operations Dept., IBM Research. He possesses over 8 years of research experience. His areas of expertise and interest encompass Distributed Systems and Cloud. In recent years, he has been active in the area of intelligence-driven Cloud Operations and enabling self-* properties including Closed-Loop Management and assurance, AI based Chaos and effective Observability. He has also been a co-inventor of more than 20 United States patents (at various stages of filing), and been a co-author of multiple research papers accepted at top-tier conferences. Additionally, he has actively mentored multiple students and collaborated with professors of various eminent academic institutions such as Boston University, IISc, IITs, IIITs, etc. He is also an ACM Eminent Speaker. He holds bachelors and masters degree from BITS-Pilani and KTH Sweden respectively.

Sandeep Hans is working as a Research Scientist at IBM Research Lab – India. He has extensive experience in Distributed Systems and Artificial Intelligence. He is a co-inventor of multiple patents and co-author of more than 15 research papers in top tier conferences. He received his Ph.D. in Computer Science from Technion - Israel Institute of Technology under the guidance of Prof. Hagit Attiya. Prior to joining IBM Research, he was a post-doc at Virginia Tech in USA and has also worked with Mindtree Consulting Ltd. in Bangalore. He is currently working on building dependable systems using adversarial AI testing.
Altri risultati simili a questo
Ricerca per canale

Automazione
Novità sull'automazione IT di tecnologie, team e ambienti

Intelligenza artificiale
Aggiornamenti sulle piattaforme che consentono alle aziende di eseguire carichi di lavoro IA ovunque

Hybrid cloud open source
Scopri come affrontare il futuro in modo più agile grazie al cloud ibrido

Sicurezza
Le ultime novità sulle nostre soluzioni per ridurre i rischi nelle tecnologie e negli ambienti

Edge computing
Aggiornamenti sulle piattaforme che semplificano l'operatività edge

Infrastruttura
Le ultime novità sulla piattaforma Linux aziendale leader a livello mondiale

Applicazioni
Approfondimenti sulle nostre soluzioni alle sfide applicative più difficili

Serie originali
Raccontiamo le interessanti storie di leader e creatori di tecnologie pensate per le aziende
Prodotti
- Red Hat Enterprise Linux
- Red Hat OpenShift
- Red Hat Ansible Automation Platform
- Servizi cloud
- Scopri tutti i prodotti
Strumenti
- Formazione e certificazioni
- Il mio account
- Supporto clienti
- Risorse per sviluppatori
- Trova un partner
- Red Hat Ecosystem Catalog
- Calcola il valore delle soluzioni Red Hat
- Documentazione
Prova, acquista, vendi
Comunica
- Contatta l'ufficio vendite
- Contatta l'assistenza clienti
- Contatta un esperto della formazione
- Social media
Informazioni su Red Hat
Red Hat è leader mondiale nella fornitura di soluzioni open source per le aziende, tra cui Linux, Kubernetes, container e soluzioni cloud. Le nostre soluzioni open source, rese sicure per un uso aziendale, consentono di operare su più piattaforme e ambienti, dal datacenter centrale all'edge della rete.
Seleziona la tua lingua
Red Hat legal and privacy links
- Informazioni su Red Hat
- Opportunità di lavoro
- Eventi
- Sedi
- Contattaci
- Blog di Red Hat
- Diversità, equità e inclusione
- Cool Stuff Store
- Red Hat Summit