
如今,越来越需要大规模运行包含数十乃至数百个微服务的复杂系统。最终用户希望所依赖的服务能够全天不间断运行,因此,即便是短短几分钟停机,也可能造成用户的不满。积极主动的混沌工程师能够在生产环境中发生停机之前识别瓶颈并强化服务,以此确保用户的期望得以满足。要想避免失去最终用户的信任,实施混沌工程至关重要。
为了更好地满足对弹性 Kubernetes 平台的需求并提供更优质的用户体验,红帽积极携手开源社区与最终用户,共同构建和维护诸如 Krkn 等开源工具及混沌工程框架。要了解 Krkn 的功能并获取关于混沌测试运行的相关见解和发现,可以参考这里的一些其他资源。
随着社区和客户在大量产品中日益广泛地采用 Krkn,我们遇到了一些挑战,而人工智能(AI)被证明有助于解决这些挑战:
- 在产品获得新功能和修复时,添加和更新测试用例。
- 为多个产品添加和维护混沌测试覆盖范围,需要对产品进行密切跟踪。
- 运行数百个测试用例,而不局限于那些被认为具有高中断概率的用例。
红帽混沌工程团队和 IBM 研究团队正在开展合作,将 AI 集成到 Krkn 中,以改进测试覆盖范围并实现自动化,有助于将混沌测试工作拓展到针对具有不同架构、节点规模和流量模式的多个产品。
Krkn 用例中的 AI 集成
随着 Krkn 被广泛应用于各种产品和配置的混沌测试,为了实现良好的测试覆盖率,测试用例已经变得错综复杂。例如,假设您的一个应用堆栈中包含大量部署,并且容器集必须协同工作才能为用户请求提供服务。为了对这个应用堆栈进行混沌测试,您必须了解其架构,并根据其服务的性质来设计测试用例,需要考虑微服务之间的依赖模式、资源密集程度及各项性能指标,如 CPU、内存、每秒输入/输出操作数、网络或流量模式等。
为此,您需要运行数百次测试用例迭代,这不仅会耗费大量人力,还可能涉及高昂的云服务成本。但即便付出了这样的努力,您仍然需要持续进行监测,以发现遗漏的边缘案例,并根据应用堆栈的演进(如功能添加、架构更改等)不断调整测试用例。运行中涉及多个容器集时,由于不同场景的组合难以预测,可能导致服务级别目标(SLO)无法实现,性能下降,最终造成服务质量受到影响。
假设您需要为大量的产品和应用进行这样的操作。您可以借助 Krkn 中的 Chaos AI 集成来解决此问题。这是 AI 如何适应并协助增强功能和解决复杂问题的典型示例。
目标是让部署的 Chaos AI 和 Krkn 框架自动发现和运行可能影响服务的不同场景,并利用强化机器学习来适应产品堆栈中的各种变化。
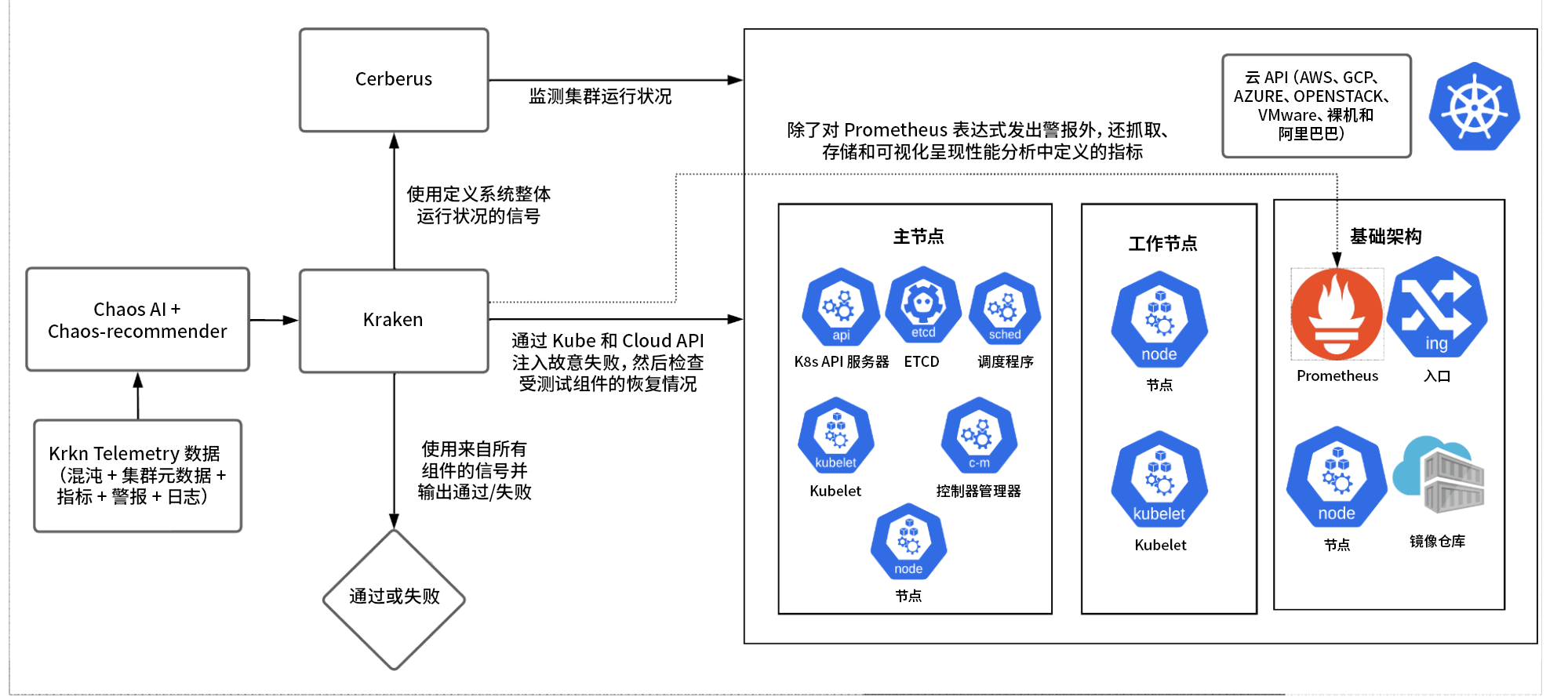
Krkn
Krkn 是一个混沌引擎,可以针对云、Kubernetes 和 OpenShift API 注入失败条件,并跟踪目标组件的恢复、集群的整体运行状况和性能 SLO。
Chaos-recommender
给定了指向服务的指针后,Chaos-recommender 可以使用 Prometheus 分析各个容器集,以了解它们是网络密集型还是与 CPU、内存或 I/O 相关,并向 Krkn 建议最有可能造成中断的场景。
Krkn Telemetry
在启用后,Krkn Telemetry 能够捕获和存储指标、警报、混沌参数、测试结果(通过/失败)和日志,以及环境详细信息,如规模(节点、容器集和路由的数量等)、架构(AMD 、ARM、X86_64)、网络插件(SDN、OVN)等。这些数据可用于训练 AI/ML 模型,以了解哪些组件频繁失败,从而对这些组件进行更多的测试。
Chaos AI 工作流
这是一个端到端框架,它将 Krkn 场景和 SLO 作为输入,并在 Chaos-recommender 和 Krkn-telemetry 的帮助下,为待测试组件分配相应的权重并针对应用堆栈运行不同的场景组合。
下面介绍了 Etcd 和 ApiServer 的一个工作流示例:
第 1 步
用户提供 Etcd 和 ApiServer 命名空间作为目标和 SLO,以便 AI 进行检查并奖励未命中结果。例如:
openshift-etcd和openshift-apiserver是命名空间输入- API 服务器的 99% 延迟应小于 1 秒
- SLO 要求 Etcd 的 leader 选举数小于 0
第 2 步
Chaos-AI 触发 Chaos-recommender。它对 Etcd 和 ApiServer 命名空间进行性能分析,以根据 Prometheus 中的资源使用量指标,识别中断概率较高的混沌场景。
第 3 步
Chaos-AI 模型使用强化学习进行训练。收集 Etcd 和 ApiServer 组件上的 Krkn-telemetry 数据,以确定哪些容器集和容器频繁失败。
第 4 步
Chaos-AI 根据第 2 和第 3 步分配权重,并运行 Krkn 场景。此强化学习所基于的系统会让框架在未达到 SLO 时奖励自身。在本例中,如果 API 延迟大于 1 秒并且 Etcd 进行 leader 选举,就会出现这种情况。
它也运行其他不太可能中断的区域,但迭代次数较少。假设它发现了一个频繁失败的新组件或组合。这将记录在 Krkn-telemetry 中并反馈给模型,以便考虑进后续迭代中。
第 5 步
输出各种失败情况,以便您解决问题。
这是一个持续性的过程,能够伴随产品的演进而灵活调整,当发现可能遗漏的边缘案例时,会识别出有待改进的方面,全程无需人工干预。
用例
您无需在产品发布 CI 中手动识别和添加测试用例,而是可以使用此框架自动识别和运行测试用例,甚至还能自动调整目标组件和新引入的组件。
更好的消息是,您可以轻松地添加、缩放和扩充测试覆盖范围,而且这不仅适用于红帽 OpenShift,也适用于整个产品组合,包括 AWS 上的红帽 OpenShift 服务和红帽 OpenShift AI 等。
后续进展
Krkn 和 Chaos AI 集成可以帮助您改进测试覆盖率。这可以增强用户对产品和环境的信心,并让用户能够通过增加可测试的产品和应用堆栈的数量来加快扩展速度。
后续博客文章将会揭晓集成结果和调查发现,敬请关注。如您所见,包括 Krkn、chaos-recommender 和 Krkn-telemetry 在内的一些组件已经开源,可用于测试和强化您的环境。我们正在积极开展工作,以实现整个 Chaos AI + Krkn 框架的开源。
欢迎您提供意见反馈和内容贡献。相关代码可在 Github 上找到。当然,我们也非常乐意就您的用例进行讨论和协作。
关于作者

Naga Ravi Chaitanya Elluri leads the Chaos Engineering efforts at Red Hat with a focus on improving the resilience, performance and scalability of Kubernetes and making sure the platform and the applications running on it perform well under turbulent conditions. His interest lies in the cloud and distributed computing space and he has contributed to various open source projects.

Mudit Verma is a Senior Research Engineer at Cloud Operations Dept., IBM Research. He possesses over 8 years of research experience. His areas of expertise and interest encompass Distributed Systems and Cloud. In recent years, he has been active in the area of intelligence-driven Cloud Operations and enabling self-* properties including Closed-Loop Management and assurance, AI based Chaos and effective Observability. He has also been a co-inventor of more than 20 United States patents (at various stages of filing), and been a co-author of multiple research papers accepted at top-tier conferences. Additionally, he has actively mentored multiple students and collaborated with professors of various eminent academic institutions such as Boston University, IISc, IITs, IIITs, etc. He is also an ACM Eminent Speaker. He holds bachelors and masters degree from BITS-Pilani and KTH Sweden respectively.

Sandeep Hans is working as a Research Scientist at IBM Research Lab – India. He has extensive experience in Distributed Systems and Artificial Intelligence. He is a co-inventor of multiple patents and co-author of more than 15 research papers in top tier conferences. He received his Ph.D. in Computer Science from Technion - Israel Institute of Technology under the guidance of Prof. Hagit Attiya. Prior to joining IBM Research, he was a post-doc at Virginia Tech in USA and has also worked with Mindtree Consulting Ltd. in Bangalore. He is currently working on building dependable systems using adversarial AI testing.








产品
工具
试用购买与出售
沟通
关于红帽
我们是世界领先的企业开源解决方案供应商,提供包括 Linux、云、容器和 Kubernetes。我们致力于提供经过安全强化的解决方案,从核心数据中心到网络边缘,让企业能够更轻松地跨平台和环境运营。