
Ha aumentado enormemente la necesidad de ejecutar sistemas complejos con decenas o cientos de microservicios a gran escala. Los usuarios finales esperan que los servicios de los que dependen estén disponibles permanentemente, por lo que incluso un tiempo de inactividad de pocos minutos puede representar un gran inconveniente. Un ingeniero de caos se anticipa a esta situación para cumplir con las expectativas de los usuarios al identificar los bloqueos y reforzar los servicios antes de que se produzca un tiempo de inactividad en un entorno de producción. La ingeniería del caos es fundamental para no perder la confianza de los usuarios finales.
Para abordar la necesidad de contar con una plataforma de Kubernetes resistente y ofrecer mejoras en la experiencia del usuario, Red Hat colabora con la comunidad open source y los usuarios finales en el diseño y mantenimiento de las herramientas open source y los marcos de ingeniería del caos, como Krkn. A continuación se mencionan algunos recursos adicionales que permiten obtener información y resultados sobre las ejecuciones de pruebas de caos, para conocer las funciones de dicho marco.
Debido al aumento en la adopción de Krkn para una gran cantidad de productos por parte de la comunidad y los clientes, nos enfrentamos a desafíos en los que se demostró que la inteligencia artificial es un recurso útil para solucionarlos:
- Agregar y actualizar casos de prueba a medida que los productos obtienen funciones y correcciones nuevas
- Ampliar y mantener el alcance de las pruebas de caos para varios productos, lo que implica realizar un seguimiento detallado de ellos
- Ejecutar cientos de casos de prueba, en lugar de solo aquellos con una alta probabilidad de interrupción
Los equipos de IBM Research e ingeniería del caos de Red Hat colaboran para integrar la inteligencia artificial en Krkn y, de esta forma, mejorar y automatizar el alcance de las pruebas, lo cual permite adaptarlas para varios productos que ejecutan diferentes arquitecturas, escalas de nodos y patrones de tráfico.
Integración de la inteligencia artificial en el caso práctico de Krkn
Debido al aumento en la adopción de Krkn para las pruebas de caos de diversos productos y configuraciones, se ha vuelto complejo lograr un buen alcance de ellas. Por ejemplo, imagine que tiene una stack de aplicaciones con muchas implementaciones y que los pods deben coordinarse para cumplir con las solicitudes de los usuarios. Para realizar una prueba de caos, debe conocer la arquitectura y diseñar casos de prueba según la naturaleza del servicio (patrones de dependencia de un microservicio en uno o más servicios, o el uso intensivo de recursos, CPU, memoria, operaciones de entrada y salida por segundo, patrones de red o de tráfico, etc.).
Para continuar, debe ejecutar cientos de casos de prueba una y otra vez, lo cual requiere muchas horas de trabajo y posibles costos de nube. Incluso si se implementa este método, es necesario realizar un control constante para buscar casos en el extremo de la red que no se contemplaron y adaptar las pruebas a medida que evoluciona la stack de aplicaciones (nuevas funciones, cambios en la arquitectura, etc.). Es difícil predecir la combinación de situaciones cuando se ejecutan en varios pods, lo cual puede provocar que no se cumplan los objetivos del nivel de servicio (SLO) y baje el rendimiento, y, por consiguiente, se vea afectado el servicio.
Imagine que debe llevar a cabo esta tarea para una gran cantidad de productos y aplicaciones. Puede superar este desafío con la integración de Chaos-AI en Krkn. Este es un ejemplo clásico de la manera en que la inteligencia artificial se adapta y ayuda a mejorar las funciones y resolver los problemas complejos.
El objetivo es que Chaos AI y el marco Krkn que se implementaron puedan descubrir y ejecutar automáticamente las situaciones que afectan el servicio y usen el machine learning (aprendizaje automático) como refuerzo para adaptarse a los cambios en la stack de productos.
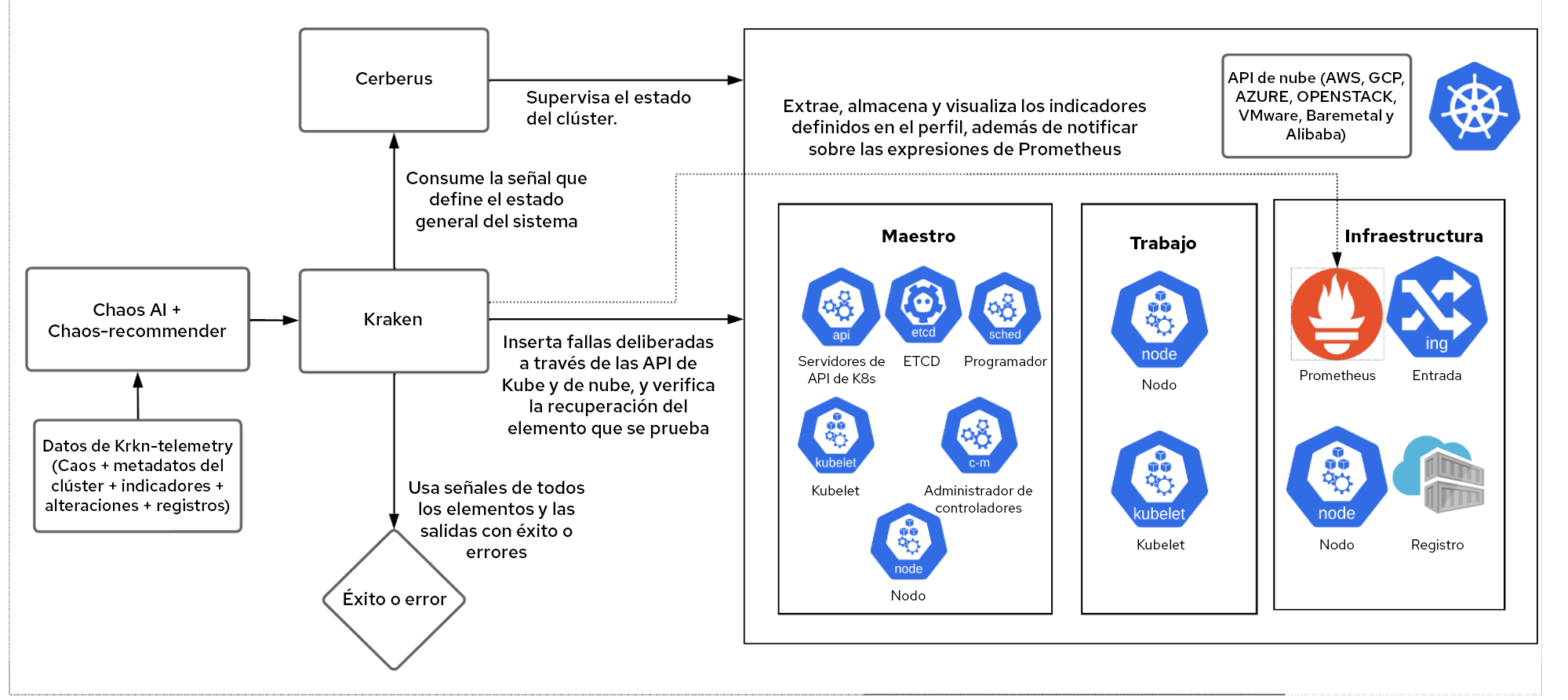
Krkn
Krkn es un motor de caos que se centra en las API de la nube, de Kubernetes y de OpenShift para insertar condiciones de errores y hacer un seguimiento de la recuperación del elemento objetivo, el estado general del clúster y los SLO de rendimiento.
Chaos-recommender
Cuando se le proporciona información a un servicio, chaos-recommender analiza cada pod usando Prometheus para saber si requieren muchos recursos de la red o si están relacionados con la CPU, la memoria o la E/S. Además, sugiere a Krkn situaciones que tienen la mayor probabilidad de causar interrupciones.
Krkn-telemetry
Cuando está habilitada, Krkn-telemetry identifica y almacena los indicadores, las notificaciones, los parámetros de caos, las pruebas de éxito o error y los registros, además de la información del entorno, como el tamaño (cantidad de nodos, pods, rutas, etc.), la arquitectura (AMD, ARM, X86_64), los plugins de la red (SDN, OVN) y mucho más. Estos datos se usan para entrenar el modelo de inteligencia artificial/machine learning y conocer los elementos que fallan con frecuencia para que se realicen más pruebas.
Flujo de trabajo de Chaos AI
Se trata del marco integral que toma las situaciones de Krkn y los objetivos de nivel de servicio como entrada y, con la ayuda de chaos-recommender y Krkn-telemetry, asigna peso a los elementos que requieren pruebas y ejecuta diferentes combinaciones de situaciones en la stack de aplicaciones.
Este es un ejemplo de flujo de trabajo para Etcd y ApiServer:
Paso 1
Un usuario proporciona espacios de nombres de Etcd y de ApiServer como objetivos y SLO para que la inteligencia artificial compruebe la existencia de errores y los solucione. Por ejemplo:
openshift-etcdyopenshift-apiserverson entradas del espacio de nombres.- El servidor de la API tiene una latencia del 99 % inferior a un segundo.
- El objetivo del nivel de servicio es que Etcd tenga elecciones de líder superiores a cero.
Paso 2
La inteligencia artificial del caos activa chaos-recommender. Analiza los espacios de nombres Etcd y ApiServer para identificar las situaciones de caos que tienen una alta probabilidad de sufrir interrupciones en función de los indicadores de uso de recursos en Prometheus.
Paso 3
El modelo de inteligencia artificial del caos se entrena mediante el aprendizaje por refuerzo. Los datos de Krkn-telemetry en los elementos de Etcd y de ApiServer se recopilan para identificar los pods y los contenedores que fallan con frecuencia.
Paso 4
La inteligencia artificial del caos asigna peso en función de los pasos 2 y 3 y ejecuta situaciones de Krkn. El aprendizaje por refuerzo se basa en un sistema en el que el marco se corrige a sí mismo según los objetivos del nivel de servicio que no se cumplen. En este ejemplo, eso sucede cuando la latencia de la API es mayor a un segundo y Etcd se somete a las elecciones de líder.
También ejecuta otras áreas que no se espera que se interrumpan, pero con menos repeticiones. Imagine que encuentra un elemento nuevo o una combinación que falla con frecuencia. Esto se registraría en Krkn-telemetry y se transmitiría al modelo para que se tenga en cuenta en las próximas repeticiones.
Paso 5
Las fallas están a su alcance para que pueda solucionarlas.
Este es un proceso permanente que se adapta a medida que el producto evoluciona e identifica áreas para mejorar sin intervención humana cuando existen posibles casos del extremo de la red que no se tuvieron en cuenta.
Casos prácticos
En lugar de identificar y agregar manualmente los casos de prueba en la integración continua de la versión del producto, este marco se usa para identificarlos y ejecutarlos, y para ajustar no solo los elementos en los que debe enfocarse, sino también los que se introdujeron recientemente, todo esto de manera automática.
Asimismo, puede agregar, ajustar y ampliar con facilidad el alcance de las pruebas para Red Hat OpenShift y para toda la cartera de productos, lo que incluye Red Hat OpenShift Service on AWS, Red Hat OpenShift AI y mucho más.
Próximos pasos
La integración de Krkn y Chaos AI le permite mejorar el alcance de las pruebas. No solo aumenta la confianza en los productos y el entorno, sino que también permite que los usuarios amplíen su capacidad con mayor rapidez al aumentar la cantidad de stacks de productos y aplicaciones que pueden probar.
Encontrará los resultados de la integración y más información en los próximos blogs. Como se puede ver, algunos recursos como Krkn, chaos-recommender y Krkn-telemetry ya son open source y están disponibles para probar y reforzar su entorno. Trabajamos activamente para implementar el open source en todo el entorno de Chaos AI y el marco de Krkn.
Se reciben comentarios y contribuciones. El código se encuentra en GitHub y, por supuesto, nos encanta analizar sus casos prácticos y colaborar en ellos.
Sobre los autores

Naga Ravi Chaitanya Elluri leads the Chaos Engineering efforts at Red Hat with a focus on improving the resilience, performance and scalability of Kubernetes and making sure the platform and the applications running on it perform well under turbulent conditions. His interest lies in the cloud and distributed computing space and he has contributed to various open source projects.

Mudit Verma is a Senior Research Engineer at Cloud Operations Dept., IBM Research. He possesses over 8 years of research experience. His areas of expertise and interest encompass Distributed Systems and Cloud. In recent years, he has been active in the area of intelligence-driven Cloud Operations and enabling self-* properties including Closed-Loop Management and assurance, AI based Chaos and effective Observability. He has also been a co-inventor of more than 20 United States patents (at various stages of filing), and been a co-author of multiple research papers accepted at top-tier conferences. Additionally, he has actively mentored multiple students and collaborated with professors of various eminent academic institutions such as Boston University, IISc, IITs, IIITs, etc. He is also an ACM Eminent Speaker. He holds bachelors and masters degree from BITS-Pilani and KTH Sweden respectively.

Sandeep Hans is working as a Research Scientist at IBM Research Lab – India. He has extensive experience in Distributed Systems and Artificial Intelligence. He is a co-inventor of multiple patents and co-author of more than 15 research papers in top tier conferences. He received his Ph.D. in Computer Science from Technion - Israel Institute of Technology under the guidance of Prof. Hagit Attiya. Prior to joining IBM Research, he was a post-doc at Virginia Tech in USA and has also worked with Mindtree Consulting Ltd. in Bangalore. He is currently working on building dependable systems using adversarial AI testing.
Navegar por canal

Automatización
Las últimas novedades en la automatización de la TI para los equipos, la tecnología y los entornos

Inteligencia artificial
Descubra las actualizaciones en las plataformas que permiten a los clientes ejecutar cargas de trabajo de inteligecia artificial en cualquier lugar

Nube híbrida abierta
Vea como construimos un futuro flexible con la nube híbrida

Seguridad
Vea las últimas novedades sobre cómo reducimos los riesgos en entornos y tecnologías

Edge computing
Conozca las actualizaciones en las plataformas que simplifican las operaciones en el edge

Infraestructura
Vea las últimas novedades sobre la plataforma Linux empresarial líder en el mundo

Aplicaciones
Conozca nuestras soluciones para abordar los desafíos más complejos de las aplicaciones

Programas originales
Vea historias divertidas de creadores y líderes en tecnología empresarial
Productos
- Red Hat Enterprise Linux
- Red Hat OpenShift
- Red Hat Ansible Automation Platform
- Servicios de nube
- Ver todos los productos
Herramientas
- Training y Certificación
- Mi cuenta
- Soporte al cliente
- Recursos para desarrolladores
- Busque un partner
- Red Hat Ecosystem Catalog
- Calculador de valor Red Hat
- Documentación
Realice pruebas, compras y ventas
Comunicarse
- Comuníquese con la oficina de ventas
- Comuníquese con el servicio al cliente
- Comuníquese con Red Hat Training
- Redes sociales
Acerca de Red Hat
Somos el proveedor líder a nivel mundial de soluciones empresariales de código abierto, incluyendo Linux, cloud, contenedores y Kubernetes. Ofrecemos soluciones reforzadas, las cuales permiten que las empresas trabajen en distintas plataformas y entornos con facilidad, desde el centro de datos principal hasta el extremo de la red.
Seleccionar idioma
Red Hat legal and privacy links
- Acerca de Red Hat
- Oportunidades de empleo
- Eventos
- Sedes
- Póngase en contacto con Red Hat
- Blog de Red Hat
- Diversidad, igualdad e inclusión
- Cool Stuff Store
- Red Hat Summit