This is a guest post by Ariel Assaraf, CEO of Coralogix.
Modern software development depends critically on high performance CI/CD. Increasing deployment frequency without adversely affecting stability is the hallmark of a high performing software company.
It’s important to incorporate effective monitoring into your CI/CD solution. In this article, we’ll link together Red Hat tools and Coralogix to propose a flexible, cutting edge continuous delivery solution.
The Tools We’ll be Using
For our proposed architecture, we’re going to tap into some outstanding technologies in the Red Hat arsenal.
OpenShift as our platform
The OpenShift platform was created by Red Hat as a versatile toolset to allow for effective deployment of applications. It has since become the most popular managed Kubernetes solution and has been used across many organizations and industries with continued success.
Kubernetes beneath it all
Kubernetes is the rock upon which OpenShift is built. Developed by Google engineers to enable effortless deployment of applications, Kubernetes is a container orchestration platform that has claimed a dominant position in open source tooling.
Kubernetes Operators working behind the scenes
Operators are what allow OpenShift to smoothly and effortlessly integrate with other applications. Essentially they are a way of packaging, deploying and managing applications which are Kubernetes-native. Operators are based on the Kubernetes concept of a controller – a software loop that compares the current state of an object with its desired state and tries to make the two match as much as possible.
Tekton for our Deployments
Sitting above Kubernetes is a framework called Tekton. This is an open source project which functions as a universal scaffold for CI/CD tools. It’s built according to industry standard specifications so it can integrate with a range of tools including Jenkins, Jenkins X and Knative. OpenShift uses the Tekton framework as a building material for pipelines and CI/CD tools.
Coralogix for Log Analytics
Coralogix is a SaaS log analytics and cloud security platform that provides a managed ELK stack, adorned with proprietary ML-powered anomaly detection. It allows teams to full real-time monitoring coverage without paying for the noise that their systems generate.
The Proposed Architecture
OpenShift provides a flexible, reliable platform on which to host your applications. Supported by Tekton, this means simple and easy deployment of applications. Basic functionality, such as rollbacks, are automatically available as part of the Tekton tool.
Log Collection is a must
While Kubernetes is capable of hosting an Elasticsearch cluster, the maintenance, patching and monitoring of this cluster takes considerable time and expertise. Coralogix solves this problem with a simple Kubernetes integration and a managed ELK stack. This ELK stack is further enhanced with a great deal of additional features, such as cost optimization for your logs.
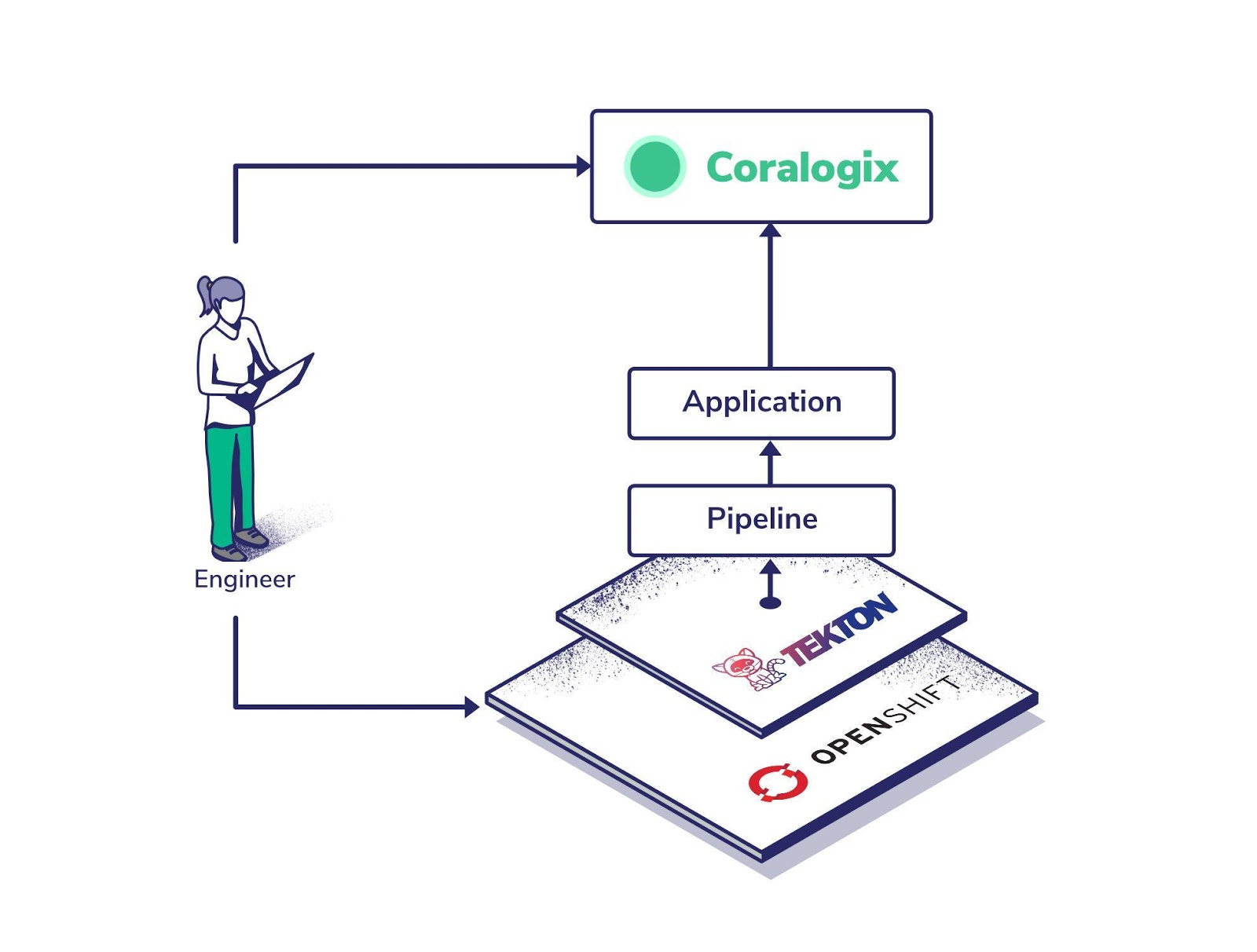
The Power of this Architecture
This architecture is simple and effective. It will deliver a quick and easy to use CI/CD solution, but it has a great deal of other hidden benefits.
Collect Crucial DevOps Metrics
Tekton’s resource model makes it trivial to collect and analyze the history of deployments, both failed and successful. Analysis of this data will provide insights into the bottlenecks in your system. The State of DevOps 2019 report indicates four key metrics that trend well with organizational success:
- Mean time to recovery
- Deployment frequency
- Deployment failure rate
- Deployment Lead Time (from commit to production)
Tekton’s stats are all available as part of the PipelineRun resource in OpenShift. The status field contains a wealth of information to dig into. This means, using the OpenShift command line tool and a bit of YAML, you can gather the essential information you need to inspect and adapt your deployment process.
Detect and Rollback Faulty Releases
Tekton comes with all the tools you need to create a self-healing CI/CD system.
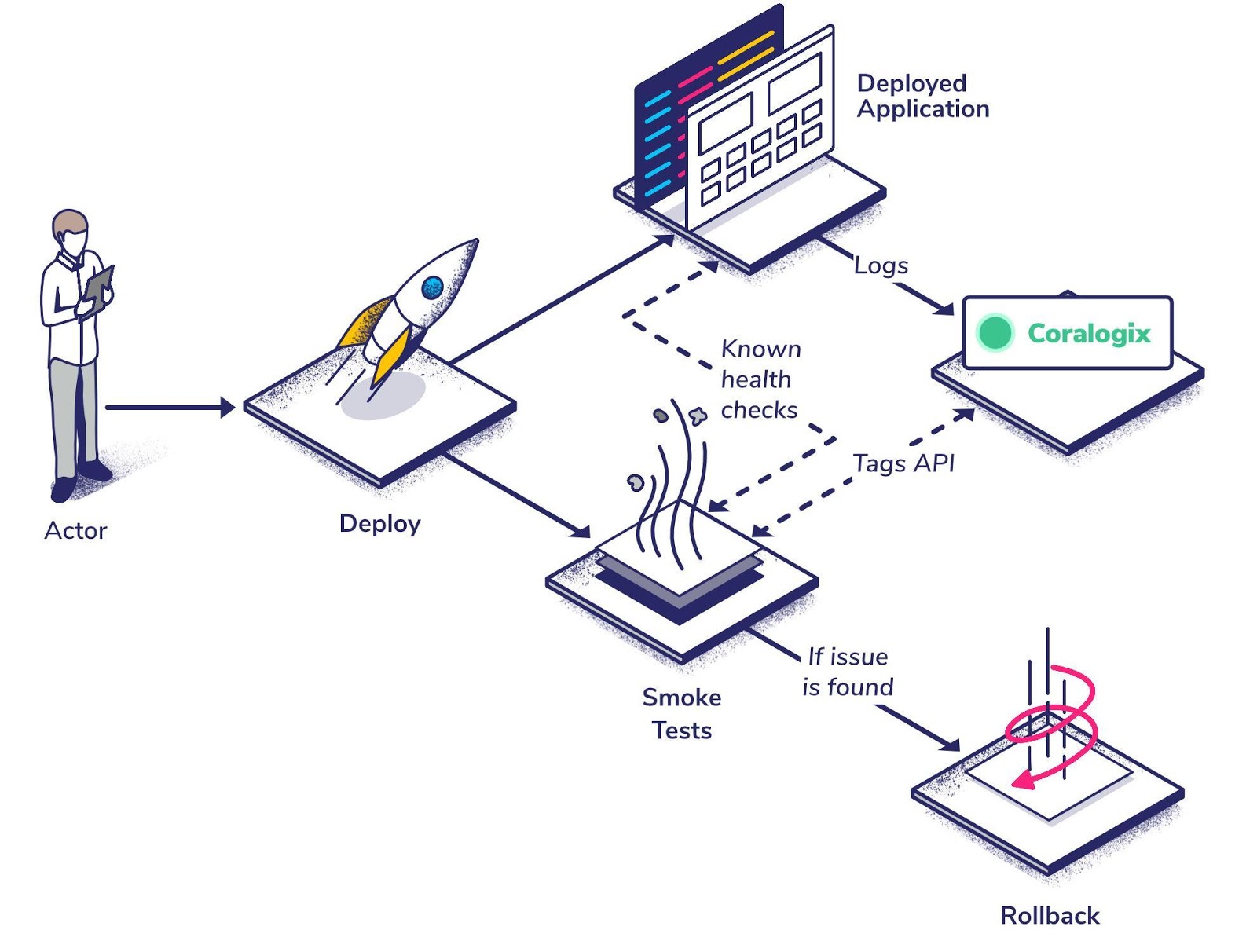
Your deployment task can make use of post-deployment checks and issue a rollback if something unexpected happens, by adding your rollback command into the except block of your task. This creates a safe, functional feedback loop that can detect known issues and automatically rollback the faulty issue.

Detect Completely New Issues
Our smoke tests will tell us if one of our features isn’t performing, but it might not be able to tell us if something unknown is happening. For that, you need to be able to benchmark your data against your previous version.
The flexible resources that are declared by Tekton mean we can collect information from any source we like, including from external APIs like Coralogix.
This introduces a whole new world of observability for our CI/CD pipeline. Rather than relying solely on the efficacy of our smoke tests, we can learn the fundamentals of our system and act on unexpected anomalies.
Observability is Key to Continuous Delivery
In order to compete in the modern software market, change is our most important currency. As our rate of change increases, so too must the scope and sophistication of our monitoring system.
By combining the declarative flexibility of OpenShift with the powerful analysis of Coralogix, you can create a CI/CD pipeline that self heals on issues known and unknown and exposes metrics about performance. It can be extended in any direction you like, to ensure that your next deployment is a success.
執筆者紹介

Red Hatter since 2018, technology historian and founder of The Museum of Art and Digital Entertainment. Two decades of journalism mixed with technology expertise, storytelling and oodles of computing experience from inception to ewaste recycling. I have taught or had my work used in classes at USF, SFSU, AAU, UC Law Hastings and Harvard Law.
I have worked with the EFF, Stanford, MIT, and Archive.org to brief the US Copyright Office and change US copyright law. We won multiple exemptions to the DMCA, accepted and implemented by the Librarian of Congress. My writings have appeared in Wired, Bloomberg, Make Magazine, SD Times, The Austin American Statesman, The Atlanta Journal Constitution and many other outlets.
I have been written about by the Wall Street Journal, The Washington Post, Wired and The Atlantic. I have been called "The Gertrude Stein of Video Games," an honor I accept, as I live less than a mile from her childhood home in Oakland, CA. I was project lead on the first successful institutional preservation and rebooting of the first massively multiplayer game, Habitat, for the C64, from 1986: https://neohabitat.org . I've consulted and collaborated with the NY MOMA, the Oakland Museum of California, Cisco, Semtech, Twilio, Game Developers Conference, NGNX, the Anti-Defamation League, the Library of Congress and the Oakland Public Library System on projects, contracts, and exhibitions.
チャンネル別に見る

自動化
テクノロジー、チームおよび環境に関する IT 自動化の最新情報

AI (人工知能)
お客様が AI ワークロードをどこでも自由に実行することを可能にするプラットフォームについてのアップデート

オープン・ハイブリッドクラウド
ハイブリッドクラウドで柔軟に未来を築く方法をご確認ください。

セキュリティ
環境やテクノロジー全体に及ぶリスクを軽減する方法に関する最新情報

エッジコンピューティング
エッジでの運用を単純化するプラットフォームのアップデート

インフラストラクチャ
世界有数のエンタープライズ向け Linux プラットフォームの最新情報

アプリケーション
アプリケーションの最も困難な課題に対する Red Hat ソリューションの詳細
仮想化
オンプレミスまたは複数クラウドでのワークロードに対応するエンタープライズ仮想化の将来についてご覧ください