
Have you ever asked yourself, where should I run OpenShift? The answer is anywhere—it runs great on bare metal, on virtual machines, in a private cloud or in the public cloud. But, there are some reasons why people are moving to private and public clouds related to automation around full stack exposition and consumption of resources. A traditional operating system has always been about exposition and consumption of hardware resources—hardware provides resources, applications consume them, and the operating system has always been the traffic cop. But a traditional operating system has always been confined to a single machine[1].
Well, in the cloud-native world, this now means expanding this concept to include multiple operating system instances. That's where OpenStack and OpenShift come in. In a cloud-native world, virtual machines, storage volumes and network segments all become dynamically provisioned building blocks. We architect our applications from these building blocks. They are typically paid for by the hour or minute and deprovisioned when they are no longer needed. But you need to think of them as dynamically provisioned capacity for applications. OpenStack is really good at dynamically provisioning capacity (exposition), and OpenShift is really good at dynamically provisioning applications (consumption), but how do we glue them together to provide a dynamic, highly programmable, multi-node operating system?
To understand, let's take a look at what would happen if we installed OpenShift in a traditional environment— imagine we want to provide developers with dynamic access to create new applications or imagine we want to provide lines of business with access to provision new copies of existing applications to meet contractual obligations. Each application would need access to persistent storage. Persistent storage is not ephemeral, and in a traditional environment, this is provisioned by filing a ticket. That's OK, we could wire up OpenShift to file a ticket every time it needs storage. A storage admin could log into the enterprise storage array and carve off volumes as needed, then hand them back to OpenShift to satisfy applications. But this would be a horribly slow, manual process—and, you would probably have storage administrators quit.
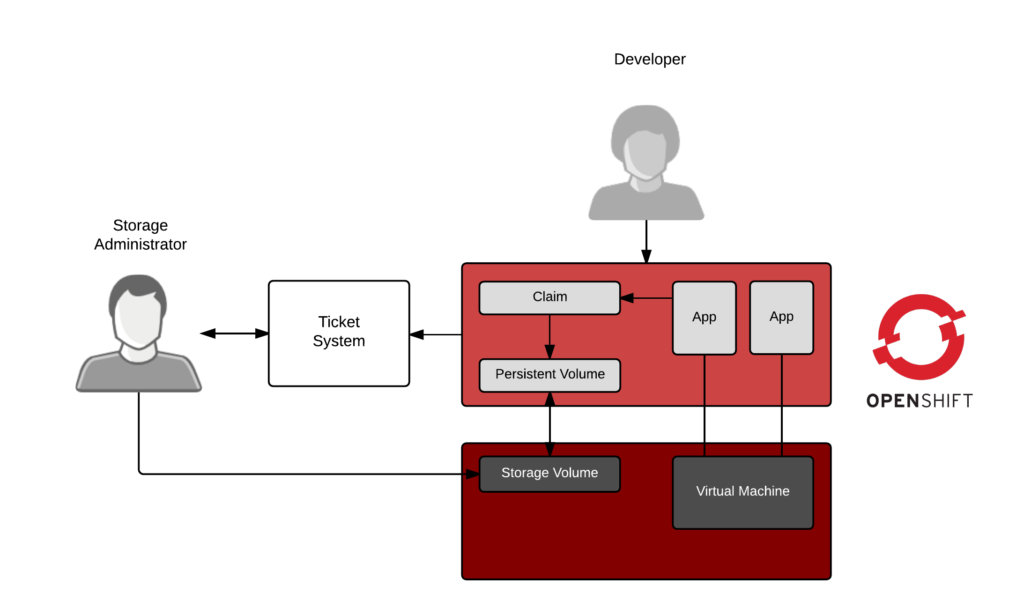
In a cloud-native world, we should think about this as a policy-driven, automated process. The storage administrator becomes more strategic, setting policies, quota, and service levels (silver, gold, etc.), but the actual provisioning becomes dynamic.
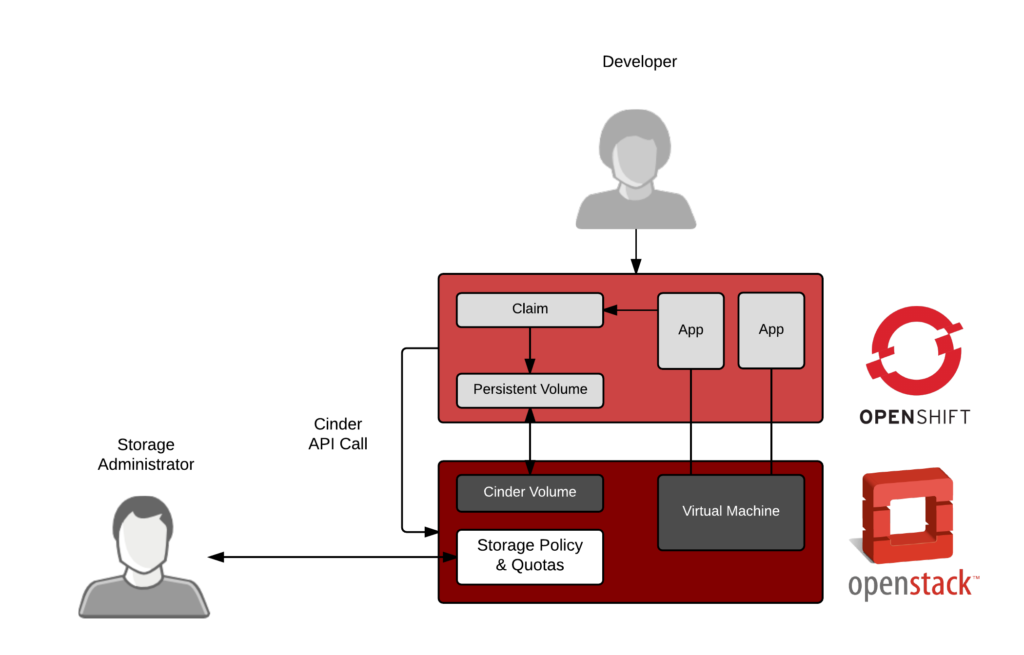
A dynamic process scales to multiple applications - this could be lines of business or even new applications being tested by developers. From 10s of applications to 1000s of applications, dynamic provisioning provides a cloud native experience.
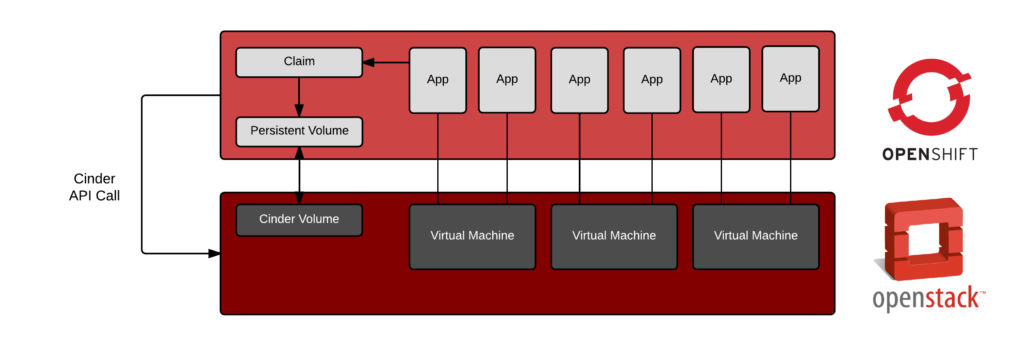
The demo video below, shows how dynamic storage provisioning works with Red Hat OpenStack Platform (Cinder volumes) and Red Hat OpenShift Container Platform - but dynamic provisioning isn't restricted to storage alone. Imagine an environment where nodes are scaled up automatically as an instance of OpenShift needs more capacity. Imagine carving off network segments for load testing a particular instance of OpenShift before pushing a particularly sensitive application change. The reasons why you need dynamic provisioning of IT building blocks goes on and on. OpenStack is really designed to do this in a programmatic, API driven way. :
[embed width="680"]https://www.youtube.com/watch?v=PfWmAS9Fc7I[/embed]
OpenShift and OpenStack deliver applications better together. OpenStack dynamically provisions resources, while OpenShift dynamically consumes them. Together, they provide a flexible cloud-native solution for all of your container and virtual machine needs.
[1] High availability clustering and some specialized operating systems bridged this gap to an extent, but was generally an edge case in computing.
저자 소개

At Red Hat, Scott McCarty is Senior Principal Product Manager for RHEL Server, arguably the largest open source software business in the world. Focus areas include cloud, containers, workload expansion, and automation. Working closely with customers, partners, engineering teams, sales, marketing, other product teams, and even in the community, he combines personal experience with customer and partner feedback to enhance and tailor strategic capabilities in Red Hat Enterprise Linux.
McCarty is a social media start-up veteran, an e-commerce old timer, and a weathered government research technologist, with experience across a variety of companies and organizations, from seven person startups to 20,000 employee technology companies. This has culminated in a unique perspective on open source software development, delivery, and maintenance.
채널별 검색

오토메이션
기술, 팀, 인프라를 위한 IT 자동화 최신 동향

인공지능
고객이 어디서나 AI 워크로드를 실행할 수 있도록 지원하는 플랫폼 업데이트

오픈 하이브리드 클라우드
하이브리드 클라우드로 더욱 유연한 미래를 구축하는 방법을 알아보세요

보안
환경과 기술 전반에 걸쳐 리스크를 감소하는 방법에 대한 최신 정보

엣지 컴퓨팅
엣지에서의 운영을 단순화하는 플랫폼 업데이트

인프라
세계적으로 인정받은 기업용 Linux 플랫폼에 대한 최신 정보

애플리케이션
복잡한 애플리케이션에 대한 솔루션 더 보기

오리지널 쇼
엔터프라이즈 기술 분야의 제작자와 리더가 전하는 흥미로운 스토리
제품
- Red Hat Enterprise Linux
- Red Hat OpenShift Enterprise
- Red Hat Ansible Automation Platform
- 클라우드 서비스
- 모든 제품 보기
툴
체험, 구매 & 영업
커뮤니케이션
Red Hat 소개
Red Hat은 Linux, 클라우드, 컨테이너, 쿠버네티스 등을 포함한 글로벌 엔터프라이즈 오픈소스 솔루션 공급업체입니다. Red Hat은 코어 데이터센터에서 네트워크 엣지에 이르기까지 다양한 플랫폼과 환경에서 기업의 업무 편의성을 높여 주는 강화된 기능의 솔루션을 제공합니다.