
Have you ever asked yourself, where should I run OpenShift? The answer is anywhere—it runs great on bare metal, on virtual machines, in a private cloud or in the public cloud. But, there are some reasons why people are moving to private and public clouds related to automation around full stack exposition and consumption of resources. A traditional operating system has always been about exposition and consumption of hardware resources—hardware provides resources, applications consume them, and the operating system has always been the traffic cop. But a traditional operating system has always been confined to a single machine[1].
Well, in the cloud-native world, this now means expanding this concept to include multiple operating system instances. That's where OpenStack and OpenShift come in. In a cloud-native world, virtual machines, storage volumes and network segments all become dynamically provisioned building blocks. We architect our applications from these building blocks. They are typically paid for by the hour or minute and deprovisioned when they are no longer needed. But you need to think of them as dynamically provisioned capacity for applications. OpenStack is really good at dynamically provisioning capacity (exposition), and OpenShift is really good at dynamically provisioning applications (consumption), but how do we glue them together to provide a dynamic, highly programmable, multi-node operating system?
To understand, let's take a look at what would happen if we installed OpenShift in a traditional environment— imagine we want to provide developers with dynamic access to create new applications or imagine we want to provide lines of business with access to provision new copies of existing applications to meet contractual obligations. Each application would need access to persistent storage. Persistent storage is not ephemeral, and in a traditional environment, this is provisioned by filing a ticket. That's OK, we could wire up OpenShift to file a ticket every time it needs storage. A storage admin could log into the enterprise storage array and carve off volumes as needed, then hand them back to OpenShift to satisfy applications. But this would be a horribly slow, manual process—and, you would probably have storage administrators quit.
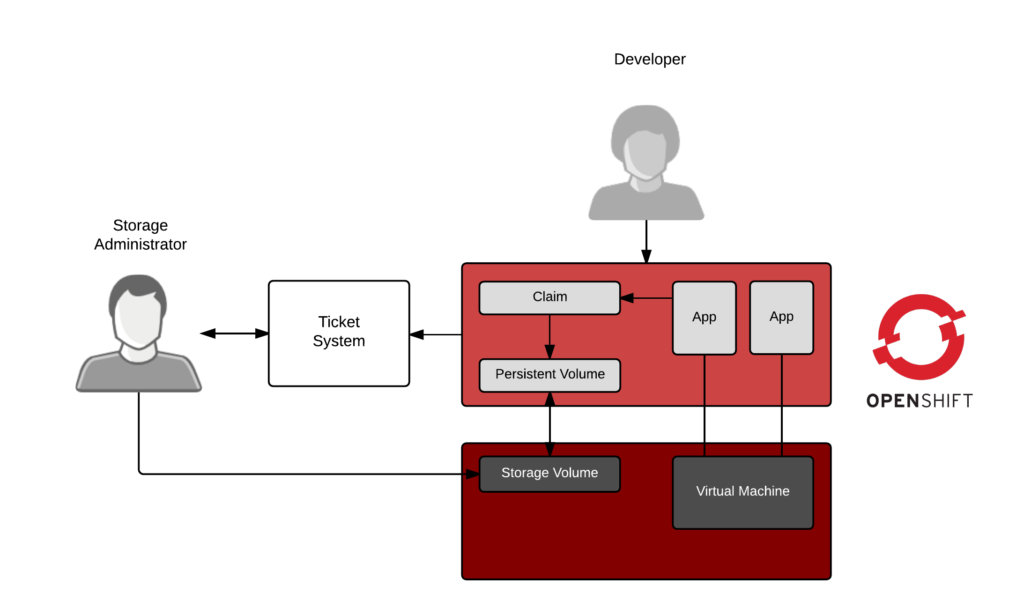
In a cloud-native world, we should think about this as a policy-driven, automated process. The storage administrator becomes more strategic, setting policies, quota, and service levels (silver, gold, etc.), but the actual provisioning becomes dynamic.
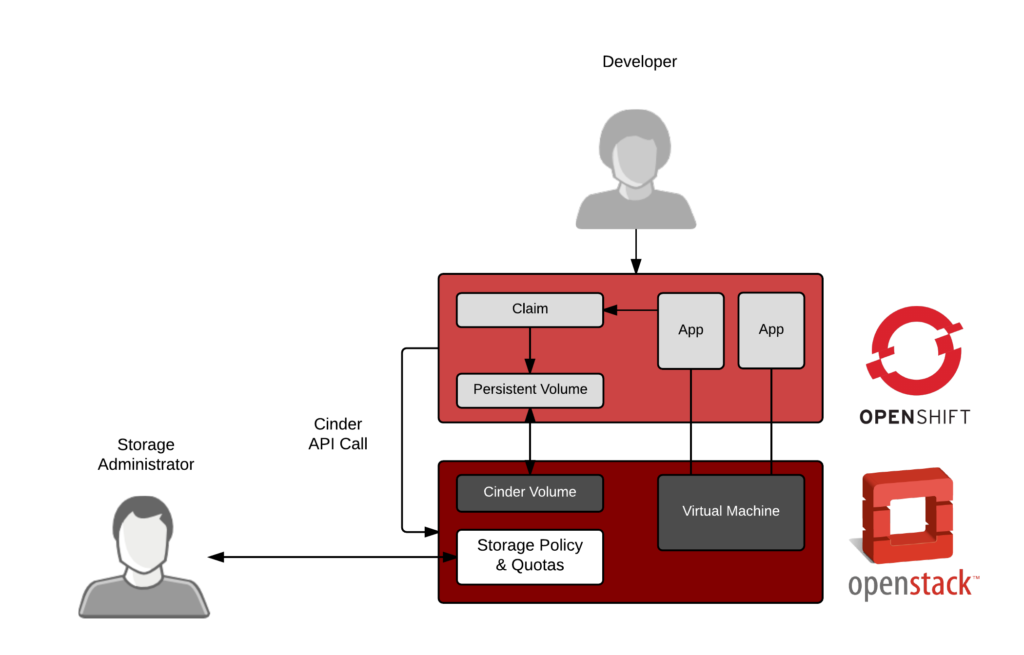
A dynamic process scales to multiple applications - this could be lines of business or even new applications being tested by developers. From 10s of applications to 1000s of applications, dynamic provisioning provides a cloud native experience.
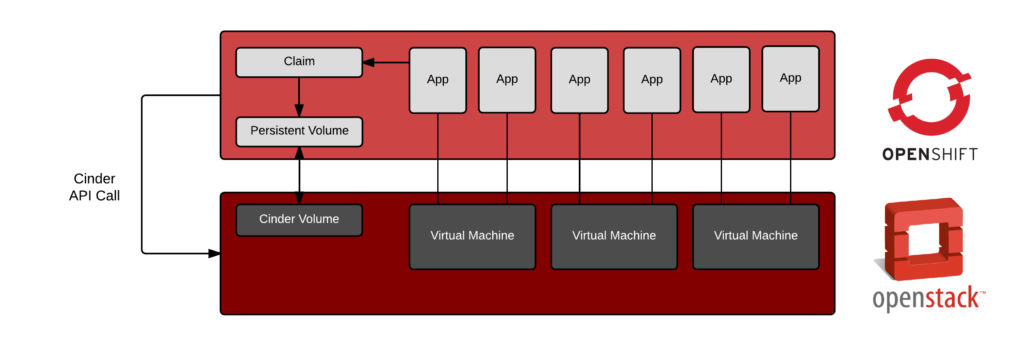
The demo video below, shows how dynamic storage provisioning works with Red Hat OpenStack Platform (Cinder volumes) and Red Hat OpenShift Container Platform - but dynamic provisioning isn't restricted to storage alone. Imagine an environment where nodes are scaled up automatically as an instance of OpenShift needs more capacity. Imagine carving off network segments for load testing a particular instance of OpenShift before pushing a particularly sensitive application change. The reasons why you need dynamic provisioning of IT building blocks goes on and on. OpenStack is really designed to do this in a programmatic, API driven way. :
[embed width="680"]https://www.youtube.com/watch?v=PfWmAS9Fc7I[/embed]
OpenShift and OpenStack deliver applications better together. OpenStack dynamically provisions resources, while OpenShift dynamically consumes them. Together, they provide a flexible cloud-native solution for all of your container and virtual machine needs.
[1] High availability clustering and some specialized operating systems bridged this gap to an extent, but was generally an edge case in computing.
Sobre o autor

At Red Hat, Scott McCarty is Senior Principal Product Manager for RHEL Server, arguably the largest open source software business in the world. Focus areas include cloud, containers, workload expansion, and automation. Working closely with customers, partners, engineering teams, sales, marketing, other product teams, and even in the community, he combines personal experience with customer and partner feedback to enhance and tailor strategic capabilities in Red Hat Enterprise Linux.
McCarty is a social media start-up veteran, an e-commerce old timer, and a weathered government research technologist, with experience across a variety of companies and organizations, from seven person startups to 20,000 employee technology companies. This has culminated in a unique perspective on open source software development, delivery, and maintenance.
Navegue por canal

Automação
Últimas novidades em automação de TI para empresas de tecnologia, equipes e ambientes

Inteligência artificial
Descubra as atualizações nas plataformas que proporcionam aos clientes executar suas cargas de trabalho de IA em qualquer ambiente

Nuvem híbrida aberta
Veja como construímos um futuro mais flexível com a nuvem híbrida

Segurança
Veja as últimas novidades sobre como reduzimos riscos em ambientes e tecnologias

Edge computing
Saiba quais são as atualizações nas plataformas que simplificam as operações na borda

Infraestrutura
Saiba o que há de mais recente na plataforma Linux empresarial líder mundial

Aplicações
Conheça nossas soluções desenvolvidas para ajudar você a superar os desafios mais complexos de aplicações

Programas originais
Veja as histórias divertidas de criadores e líderes em tecnologia empresarial
Produtos
- Red Hat Enterprise Linux
- Red Hat OpenShift
- Red Hat Ansible Automation Platform
- Red Hat Cloud Services
- Veja todos os produtos
Ferramentas
- Treinamento e certificação
- Minha conta
- Suporte ao cliente
- Recursos para desenvolvedores
- Encontre um parceiro
- Red Hat Ecosystem Catalog
- Calculadora de valor Red Hat
- Documentação
Experimente, compre, venda
Comunicação
- Contate o setor de vendas
- Fale com o Atendimento ao Cliente
- Contate o setor de treinamento
- Redes sociais
Sobre a Red Hat
A Red Hat é a líder mundial em soluções empresariais open source como Linux, nuvem, containers e Kubernetes. Fornecemos soluções robustas que facilitam o trabalho em diversas plataformas e ambientes, do datacenter principal até a borda da rede.
Selecione um idioma
Red Hat legal and privacy links
- Sobre a Red Hat
- Oportunidades de emprego
- Eventos
- Escritórios
- Fale com a Red Hat
- Blog da Red Hat
- Diversidade, equidade e inclusão
- Cool Stuff Store
- Red Hat Summit