O Kubeflow é uma plataforma de Inteligência Artificial e Machine Learning (IA/ML) que reúne diversas ferramentas que abordam os principais casos de uso de IA/ML, como exploração e pipelines de dados, treinamento e disponibilização de modelos. O Kubeflow permite aos cientistas de dados acessar esses recursos por meio de um portal com abstrações de alto nível para interagir com as ferramentas. Isso significa que cientistas de dados não precisam se preocupar em ter que aprender detalhes mínimos sobre como o Kubernetes conecta cada uma dessas ferramentas. Dito isso, o Kubeflow foi especificamente projetado para execução no Kubernetes e adota completamente muitos conceitos principais, como o modelo de operador. Na verdade, exceto pelo portal mencionado, o Kubeflow é uma coleção de operadores.
Neste artigo, examinaremos uma série de configurações que adotamos em um contrato recente com o cliente para fazer o Kubeflow (1.3 ou superior) funcionar bem em um ambiente OpenShift.
Considerações sobre o multitenancy do Kubeflow
Um dos casos de uso que o Kubeflow aborda é a capacidade de atender a vários cientistas de dados. Para fazer isso, o Kubeflow aborda o multitenancy (totalmente disponível a partir da versão 1.3) de modo que cada cientista de dados recebe um namespace do Kubernetes para operar. Há também mecanismos para compartilhar artefatos em namespaces, mas ainda não foram explorados.
É importante entender essa abordagem de multitenancy, porque uma parte significativa da operacionalização do Kubeflow foi dedicada à compatibilidade com essa funcionalidade do OpenShift. Implantar o OpenShift com um namespace por usuário, em vez de um namespace por aplicativo (o qual é o padrão mais comum), pode exigir algumas reformulações, dependendo de como a autenticação/autorização é organizada.
Para que o multitenancy do Kubeflow funcione corretamente, é preciso autenticar um usuário e adicionar um cabeçalho confiável (kubeflow-userid por padrão, mas isso é configurável) a todas as solicitações. Depois isso, o Kuberflow cria um namespace para o usuário, caso ele não exista.
O outro aspecto do multitenancy do Kubeflow é o conceito de perfil. O perfil é um recurso personalizado (CR) que representa um ambiente de um usuário. Ele é mapeado para um namespace gerenciado pelo Kubeflow. O cabeçalho kubeflow-userid precisa corresponder a um perfil existente para o Kubeflow encaminhar adequadamente as solicitações.
Após estabelecer e associar o perfil a um usuário, o Kubeflow cria um namespace onde todas as suas atividades subsequentes ocorrerão.
O Kubeflow também é fortemente integrado ao Istio. Como a segurança do Kubeflow é baseada em construções do Istio, o mais recomendado é que ele seja executado com o próprio Kubeflow, apesar de não haver requisitos rígidos para isso. Ao executar com o Istio, uma das abordagens mais simples para dar suporte ao multitenancy é criar os namespaces como resultado dos perfis do Kubeflow pertencentes à service mesh e a um único ingress-gateway por onde todo o tráfego passa.

Esse ponto de estrangulamento torna-se o candidato natural para realizar a autenticação do usuário e definir o cabeçalho kubeflow-userid mencionado.
Integração com o Red Hat OpenShift Service Mesh
O OpenShift Service Mesh é diferente do Istio, pois um cluster do OpenShift pode conter várias service meshes. Por outro lado, para o Istio upstream, está implícito que o mesh se expande para todo o cluster do Kubernetes.
Em nossa configuração, decidimos dedicar totalmente uma Service Mesh aos casos de uso de IA/ML. Com isso em mente, somente os namespaces de IA/ML do Kubeflow pertencem a essa service mesh dedicada de IA/ML.
Também precisávamos dar suporte à adição e remoção de cientistas de dados a qualquer momento. Isso levou à decisão de adotar o modelo recomendado de um perfil/namespace por usuário.
Em resumo, tivemos que encontrar soluções para os seguintes requisitos:
- Garantir que as conexões dos cientistas de dados sejam autenticadas e que o cabeçalho kubeflow-userid seja adicionado à solicitação de maneira inviolável.
- Garantir que os perfis do Kubeflow sejam criados para cada cientista de dados.
- Garantir que os namespaces criados pelo Kubeflow como resultado da criação de um perfil pertençam à service mesh de IA/ML.
Garantia de autenticação do cientista de dados
Como já foi dito, o Kubeflow usa um cabeçalho para representar o usuário conectado. Existem opções para alterar o nome de cabeçalho padrão kubeflow-userid, mas isso implica modificações em vários locais. Como resultado, decidimos que seria mais simples continuar usando o nome de cabeçalho padrão.
A inserção desse cabeçalho pode ser realizada de várias maneiras, por exemplo:

Como o Kubeflow publica seus serviços externos em um gateway de entrada do Istio (por padrão, chamado de Kubeflow), o gateway foi instrumentalizado para reforçar a autenticação usando um proxy oauth que redireciona usuários não autenticados para o fluxo de login do OpenShift. Essa abordagem de proxy oauth é usada por muitos outros componentes do OpenShift. Com ela, somente usuários autenticados do OpenShift com as permissões necessárias podem fazer solicitações. Para mais informações sobre como integrar o proxy oauth, veja este post.
O sidecar oauth-proxy no gateway de entrada cria um cabeçalho chamado x-forwarded-user com o userid do usuário autenticado (conforme as práticas recomendadas de http). Assim, só é preciso adicionar uma regra de transformação (implementada como um EnvoyFilter CR) no gateway de entrada para copiar o valor desse cabeçalho para um novo cabeçalho chamado kubeflow-userid. Além disso, o sidecar oauth-proxy é configurado para deixar passar apenas usuários com a permissão GET em pods nos namespaces do Kubeflow. Aqui, é possível configurar qualquer conjunto de permissões, que pode ser usado para distinguir entre usuários e não usuários do Kubeflow.
Com essa abordagem:
- Todos os usuários do Kubeflow também são usuários do OpenShift (observe que o inverso não é necessariamente verdadeiro). É possível aproveitar o que foi configurado no OCP em termos de integração com o sistema de autenticação empresarial. Isso torna essa abordagem muito portátil.
- Como há apenas um método de entrada no Kubeflow mesh (pela proteção do gateway de entrada do Kubeflow), garantimos que somente usuários autenticados poderão aproveitar os serviços do Kubeflow.
Garantia de criação de perfis do Kubeflow
O Kubeflow exige um objeto Profile (CR) para registrar e gerenciar corretamente um usuário. A criação do objeto Profile é chamada de "registro". É possível permitir que novos usuários se registrem, mas optamos por um processo de registro automático: quando um usuário faz login pela primeira vez, o perfil correspondente é automaticamente criado.
No OpenShift, um objeto User é criado na primeira vez que um usuário faz login. Também é possível interceptar esse evento para criar o objeto Profile.
Para automatizar a criação do objeto Profile, podemos usar o operador de configuração do namespace. O diagrama a seguir representa a sequência de eventos que criam o objeto Profile quando um usuário faz login no OpenShift pela primeira vez:

Inclusão de namespaces do Kubeflow na service mesh de IA/ML
Quando criamos um objeto Profile do Kubeflow, ele também cria o namespace do Kubernetes correspondente e adiciona vários recursos a esse novo namespace, como cotas, regras de RBAC do Istio e contas de serviço. O Kubeflow pressupõe que os namespaces pertencem à mesh, mas esse não é o caso do OpenShift Service Mesh, em que cada namespace deve ser explicitamente associado a uma determinada mesh (pode haver várias). Para resolver esse problema, use novamente o operador de configuração do namespace. Desta vez, crie uma regra acionada na criação e insira os namespaces na mesh. O fluxo de trabalho completo compreende:

Depois que esse fluxo de trabalho é configurado corretamente, o cientista de dados verá isto ao fazer login:
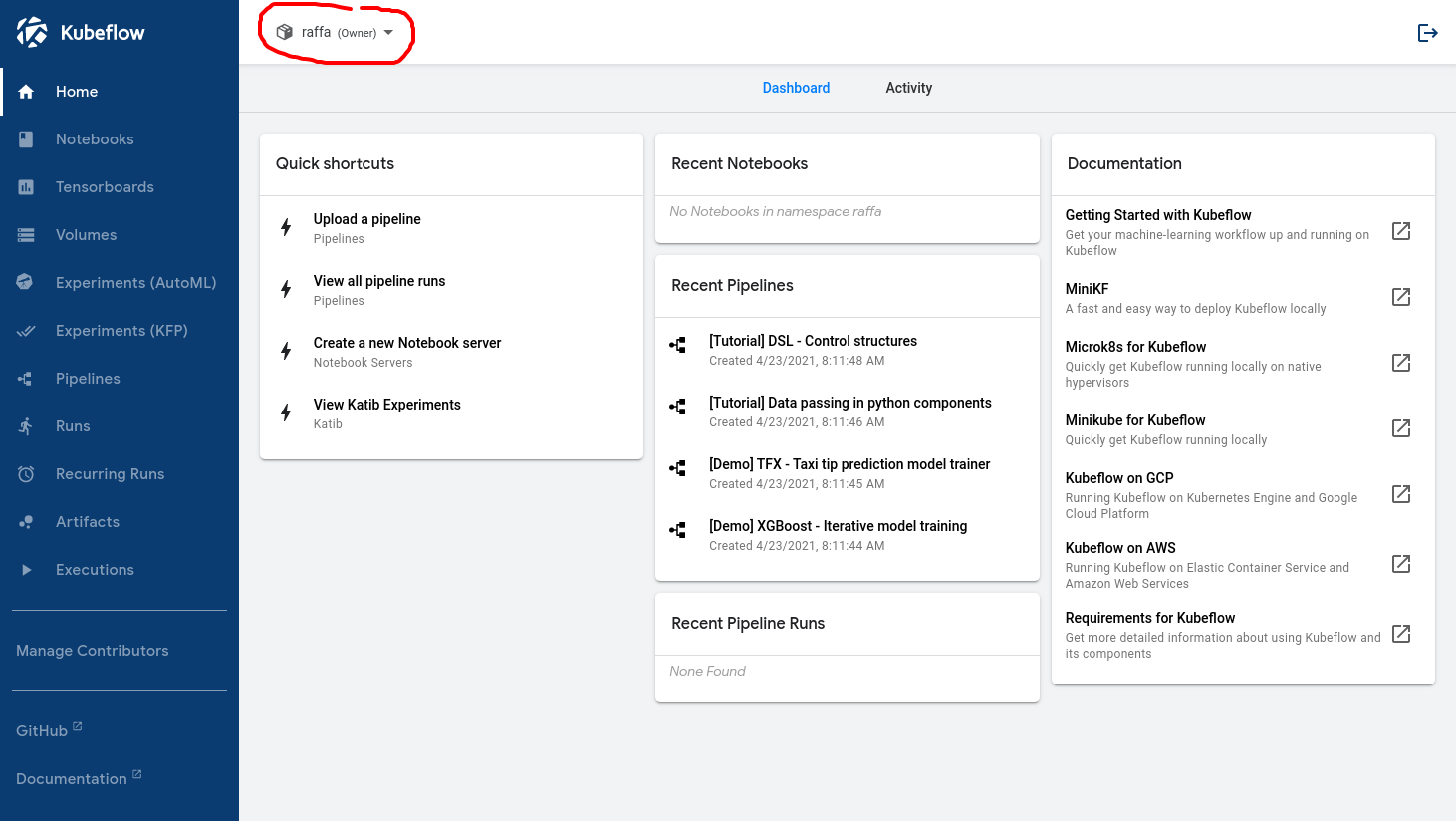
O nome no círculo vermelho confirma que o usuário foi reconhecido pelo Kubeflow.
Habilitação de nós de GPU e escalabilidade automática de nós
Aqui, os cientistas de dados podem fazer login no dashboard principal do Kubeflow e começar a usar a funcionalidade oferecida. Naturalmente, uma das funcionalidades necessárias para oferecer suporte a vários casos de uso de IA/ML é a capacidade de acessar GPUs.
A habilitação dos nós das GPUs é simples, desde que os pré-requisitos sejam atendidos. Este post detalha o processo.
Porém, os nós de GPU são recursos caros. Por isso, é preciso implementar dois requisitos para minimizar os gastos:
- Permita apenas cargas de trabalho relacionadas a IA/ML nos nós de GPU.
- Permita o escalonamento vertical automático dos nós de GPU, aumentando ou reduzindo conforme os recursos necessários.
Separação de cargas de trabalho de IA/ML das cargas de trabalho normais
Use taints e tolerância para separar as cargas de trabalho de IA/ML das outras cargas de trabalho presentes no cluster e que não exigem nós de GPU. Basta criar os nós de GPU com uma taint que impedirá as cargas de trabalho de alcançarem esses nós por padrão.
Para impedir que os contratantes do serviço que não são de IA/ML marquem as cargas de trabalho com tolerância para taint, use esta anotação de namespace:
scheduler.alpha.kubernetes.io/tolerationsWhitelist: '[]'
Para simplificar a vida do cientista de dados e adicionar automaticamente a tolerância às cargas de trabalho em execução nos namespaces de IA/ML, aplique esta anotação a todos os namespaces do Kubeflow:
scheduler.alpha.kubernetes.io/defaultTolerations: '[{"operator": "Equal", "effect": "NoSchedule", "key": "workload", "value": "ai-ml"}]'Nesse exemplo, os nós habilitados para GPU foram denominados “workload: ai-ml” .
Observe que essas são anotações Alfa e ainda não são compatíveis com a Red Hat. Porém, com base em nossos testes, elas funcionam bem.
Como já mencionado, o Kubeflow criará namespaces para os cientistas de dados no primeiro login. Já que não controlamos a criação dos namespaces, é preciso implementar um processo para as anotações corretas serem aplicadas ao namespace. Para fazer isso, use uma configuração de webhook de mutação. Esse webbook consegue interceptar a criação do namespace e adicionar as anotações necessárias. Usamos o Open Policy Agent (OPA) e o projeto Gatekeeper, que integra o OPA ao Kubernetes. Em seguida, fizemos a implantação pelo operador do Gatekeeper.

Habilitação da escalabilidade automática de nós
Para minimizar o número de nós de GPU de alto custo, é preciso habilitar a escalabilidade automática nos nós de IA/ML.
A escalabilidade automática de nós é uma funcionalidade pronta do OpenShift e pode ser ativada usando as etapas da documentação oficial.
Ao utilizar a funcionalidade de escalabilidade automática de nós, ficou claro que as seguintes situações exigiam melhorias:
Primeiro, o escalador automático adicionará nós somente quando os pods estiverem em estado "pendente". Esse comportamento reativo resulta em uma experiência de usuário ruim. Ao tentar iniciar as cargas de trabalho, os usuários precisam aguardar a criação dos nós (aproximadamente 5 minutos na AWS) e a disponibilização dos drivers de GPU (mais 3 a 4 minutos). Para melhorar essa situação, usamos o proactive-node-scaling-operator, descrito neste blog.
Em segundo lugar, ao utilizar nós de GPU, o escalador automático tende a criar mais nós do que o necessário. Isso ocorre porque os nós recém-criados não podem agendar os pods pendentes imediatamente. A princípio, eles não são habilitados para GPU enquanto o operador de GPU estiver realizando as etapas de inicialização, como compilação e injeção de drivers do kernel de GPU. Para resolver esse problema, adicione um rótulo específico (cluster-api/accelerator: "true") ao template do nó, conforme explicado aqui. Esse rótulo informará o escalador automático de nós que um nó específico deve ter determinadas funcionalidades habilitadas (como suporte para GPUs), mesmo quando eles ainda não estiverem presentes.
Habilitação de acesso ao data lake
Para quase todas as tarefas que um cientista de dados precisa realizar, o acesso aos dados é fundamental. Seja a exploração de dados para entender a estrutura dos dados e suas possíveis correlações internas, o treinamento de modelos de rede neural por meio de conjuntos de dados de amostra ou a recuperação de um modelo para poder atendê-lo. Em IA/ML, o repositório de dados, que contém dados de todos os tipos (relacionais, valores-chave, documentos, árvore e outros), é chamado de data lake.
Proteger o acesso ao data lake pode ser um desafio, principalmente em um ambiente com vários contratantes do serviço. Além disso, queremos facilitar a vida dos cientistas de dados, minimizando o número de Kubernetes e conceitos de gerenciamento de credenciais que eles precisam aprender.
No nosso caso, o data lake consistia em um conjunto de buckets AWS S3. Tipos alternativos de repositório de armazenamento podem usar muitos desses mesmos conceitos.
A equipe de segurança também solicitou que as credenciais necessárias para acessar o data lake representassem uma carga de trabalho, não um indivíduo específico. Além disso, a credencial deve ser de curta duração. O objetivo era evitar que os cientistas de dados recebessem credenciais estáticas que poderiam ser perdidas ou usadas incorretamente.
Para resolver esse problema, usamos tokens de conta de serviço vinculados e a integração OpenShift - STS, reaproveitando esta última para cargas de trabalho de usuários. Vamos ver como combinar essas duas tecnologias.
Com tokens de conta de serviço vinculados, o OpenShift pode gerar um token JWT, que representa a carga de trabalho e é montado como um volume projetado, assim como os tokens de conta de serviço funcionam para qualquer outra carga de trabalho. Ao contrário dos tokens de conta de serviço, esse token é de curta duração (o Kubelet é responsável pela atualização) e pode ser personalizado pela definição da propriedade de público.
O STS é um serviço da AWS (existem serviços semelhantes para outros provedores de nuvem) que permite estabelecer a confiança da AWS em outros sistemas de autenticação, incluindo provedores de autenticação OIDC. Ao configurar o STS, é possível instruir a AWS para confiar em tokens JWT cunhados pelo OpenShift e trocá-los por tokens da AWS com um conjunto específico de permissões. Depois da troca, o aplicativo sendo executado em um pod pode começar a consumir recursos da AWS. O diagrama abaixo representa essa arquitetura:

Para configurar a integração com o STS, veja estes documentos oficiais neste blog .
Um dos requisitos dessa abordagem é que as contas de serviço usadas para executar os pods de IA/ML tenham anotações específicas anexadas indicando que essas cargas de trabalho exigem o token adicional da conta de serviço vinculado. Para fazer isso, use a OPA e insira as anotações necessárias nas contas de serviço nos namespaces dos cientistas de dados.
Com o resultado da configuração descrita anteriormente, os cientistas de dados e as cargas de trabalho de IA/ML em geral podem acessar o data lake com credenciais que representam a carga de trabalho (e não um indivíduo específico) e são de curta duração (portanto, não precisam ser persistidas). Tudo isso acontece de forma transparente para os cientistas de dados, que precisam apenas usar qualquer cliente padrão da AWS que entenda o método de autenticação STS para acessar o data lake.
Integração com o Serverless
Quando se trata de fornecer um modelo, o padrão no Kubeflow é utilizar o Kfserving . Para outras abordagens compatíveis, clique aqui.
O Kfserving é baseado no Knative, que é uma funcionalidade do OpenShift habilitada com a instalação do OpenShift Serverless.
É necessário ter cuidado ao usar o Red Hat OpenShift Service Mesh e o Serverless, pois alguns pré-requisitos devem ser atendidos para uma integração adequada.
Especificamente, é preciso criar uma regra NetworkPolicy em cada namespace da service mesh para permitir o tráfego dos namespaces serverless para os namespaces mesh.
Além disso, todos os serviços da mesh em um ecossistema Kubeflow de multitenancy são protegidos por AuthorizationPolicies do Istio e os componentes serverless são externos à mesh. Por isso, é preciso modificar as políticas de RBAC para permitir conexões dos pods de namespaces do Serverless, especificamente Kourier e Activator:

Automatizamos a criação dessas regras com o operador de configuração do namespace, instruindo-o a adicionar os recursos NetworkPolicy e AuthorizationPolicy ao criar o namespace do cientista de dados.
Instalação
Para instruções de instalação detalhadas de cada um dos tópicos descritos, além das configurações associadas, veja este repositório. Esse passo a passo também contém várias outras pequenas melhorias e alguns exemplos de cargas de trabalho de IA/ML para validar a configuração.
Conclusão
Neste artigo, abordamos várias considerações necessárias para configurar uma implantação multitenancy do Kubeflow no OpenShift. É apenas o primeiro passo em uma jornada de IA/ML, mas deve ser suficiente para começar. Depois disso, a equipe de cientistas de dados pode começar a explorar os dados com Jupyter notebooks e criar pipelines de dados, incluindo o treinamento de modelos de rede neural. Quando os modelos de rede neural estiverem prontos, o Kubeflow também poderá ajudar com o caso de uso de exibição do modelo.
É importante lembrar que a Red Hat ainda não tem suporte para a execução do Kubeflow no OpenShift. Além disso, o Kubeflow é uma solução com várias funcionalidades. Nessa implantação inicial, ainda não verificamos se todas funcionam corretamente. Para ver a lista de funcionalidades testadas, acesse o repositório. Por exemplo, todo o stack de observabilidade do Kubeflow. Essa é uma funcionalidade importante que, infelizmente, ainda não está operacionalizada, embora possa ser integrada no futuro.
A expectativa é que esse tipo de trabalho possa ser usado para impulsionar organizações que querem executar o Kubeflow no OpenShift. Além disso, esses conceitos oferecem muitos dos princípios básicos comuns que podem ser usados na operacionalização de outras plataformas de IA/ML.
Sobre o autor

Raffaele is a full-stack enterprise architect with 20+ years of experience. Raffaele started his career in Italy as a Java Architect then gradually moved to Integration Architect and then Enterprise Architect. Later he moved to the United States to eventually become an OpenShift Architect for Red Hat consulting services, acquiring, in the process, knowledge of the infrastructure side of IT.
Currently Raffaele covers a consulting position of cross-portfolio application architect with a focus on OpenShift. Most of his career Raffaele worked with large financial institutions allowing him to acquire an understanding of enterprise processes and security and compliance requirements of large enterprise customers.
Raffaele has become part of the CNCF TAG Storage and contributed to the Cloud Native Disaster Recovery whitepaper.
Recently Raffaele has been focusing on how to improve the developer experience by implementing internal development platforms (IDP).
Mais como este
Red Hat, NVIDIA, and Palo Alto Networks collaborate to deliver an integrated, security-first foundation for AI-native telecommunications
How llm-d brings critical resource optimization with SoftBank’s AI-RAN orchestrator
Technically Speaking | Build a production-ready AI toolbox
Technically Speaking | Platform engineering for AI agents
Navegue por canal

Automação
Últimas novidades em automação de TI para empresas de tecnologia, equipes e ambientes

Inteligência artificial
Descubra as atualizações nas plataformas que proporcionam aos clientes executar suas cargas de trabalho de IA em qualquer ambiente

Nuvem híbrida aberta
Veja como construímos um futuro mais flexível com a nuvem híbrida

Segurança
Veja as últimas novidades sobre como reduzimos riscos em ambientes e tecnologias

Edge computing
Saiba quais são as atualizações nas plataformas que simplificam as operações na borda

Infraestrutura
Saiba o que há de mais recente na plataforma Linux empresarial líder mundial

Aplicações
Conheça nossas soluções desenvolvidas para ajudar você a superar os desafios mais complexos de aplicações
Virtualização
O futuro da virtualização empresarial para suas cargas de trabalho on-premise ou na nuvem