En octubre pasado, anunciamos la versión de prueba para desarrolladores de la función de supervisión de energía para Red Hat OpenShift, y presentamos Kepler como elemento integral de la iniciativa de informática sostenible de la comunidad upstream. La iniciativa permite que los primeros usuarios experimenten con esta tecnología prometedora. Desde el anuncio, nuestro equipo trabajó arduamente para diseñar canales y herramientas que cumplieran con los estándares de seguridad y pruebas de los productos de Red Hat.
Hoy nos complace anunciar un nuevo hito en el proceso: el lanzamiento de la versión de prueba de la función de supervisión de energía para Red Hat OpenShift. Agradecemos con sinceridad a todos los primeros usuarios y amantes de la tecnología revolucionaria que participaron activamente en la implementación de esta función y compartieron con generosidad sus valiosos comentarios.
Para quienes que no tuvieron la oportunidad de experimentar con la función de supervisión de energía para Red Hat OpenShift, se trata de un conjunto de herramientas que le permiten supervisar el consumo de energía de las cargas de trabajo que se ejecutan en los clústeres de OpenShift. Esta información se puede aprovechar para diversos fines, como la identificación de los espacios de nombres que consumen más energía o la formulación de un plan estratégico para disminuir su consumo.
Si le interesa experimentar con esta versión de prueba, a continuación le brindamos los detalles para que comience a usarla. Lea la declaración sobre la versión de prueba para obtener más información sobre el soporte oficial.
Instalación de la función de supervisión de energía para Red Hat OpenShift
Nuestro objetivo es proporcionar una experiencia unificada y, por ese motivo, los pasos para la instalación se parecen mucho a los de la versión anterior de la función, que dependía del operador de la comunidad.
- Habilite user-workload-monitoring siguiendo las instrucciones provistas en la documentación de Red Hat OpenShift.
- Para evitar conflictos innecesarios, primero, desinstale toda versión anterior de kepler-operator que haya instalado a través del catálogo de operadores de la comunidad.
- Instale el operador desde la consola de OpenShift 4.14 (y versiones posteriores) dirigiéndose a "Operators -> OperatorHub". Luego, use el cuadro de búsqueda para buscar la función de supervisión de energía para Red Hat OpenShift, haga clic en ella y presione el botón "Install".
- Una vez que se instale el operador, cree una instancia de la definición de recursos personalizados de Kepler haciendo clic en "View Operator" y, luego, haga clic en "Create instance" debajo de la API de Kepler.
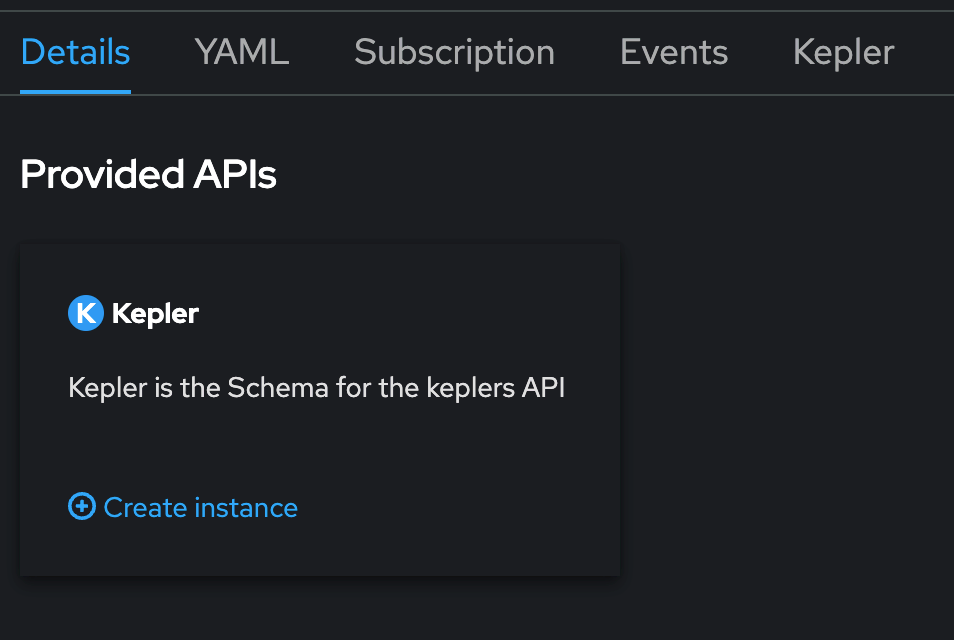
Listo. Una vez que se instale Kepler, habrá dos nuevos paneles disponibles en la pestaña "Observe>Dashboards" de la interfaz de usuario de la consola de OpenShift:
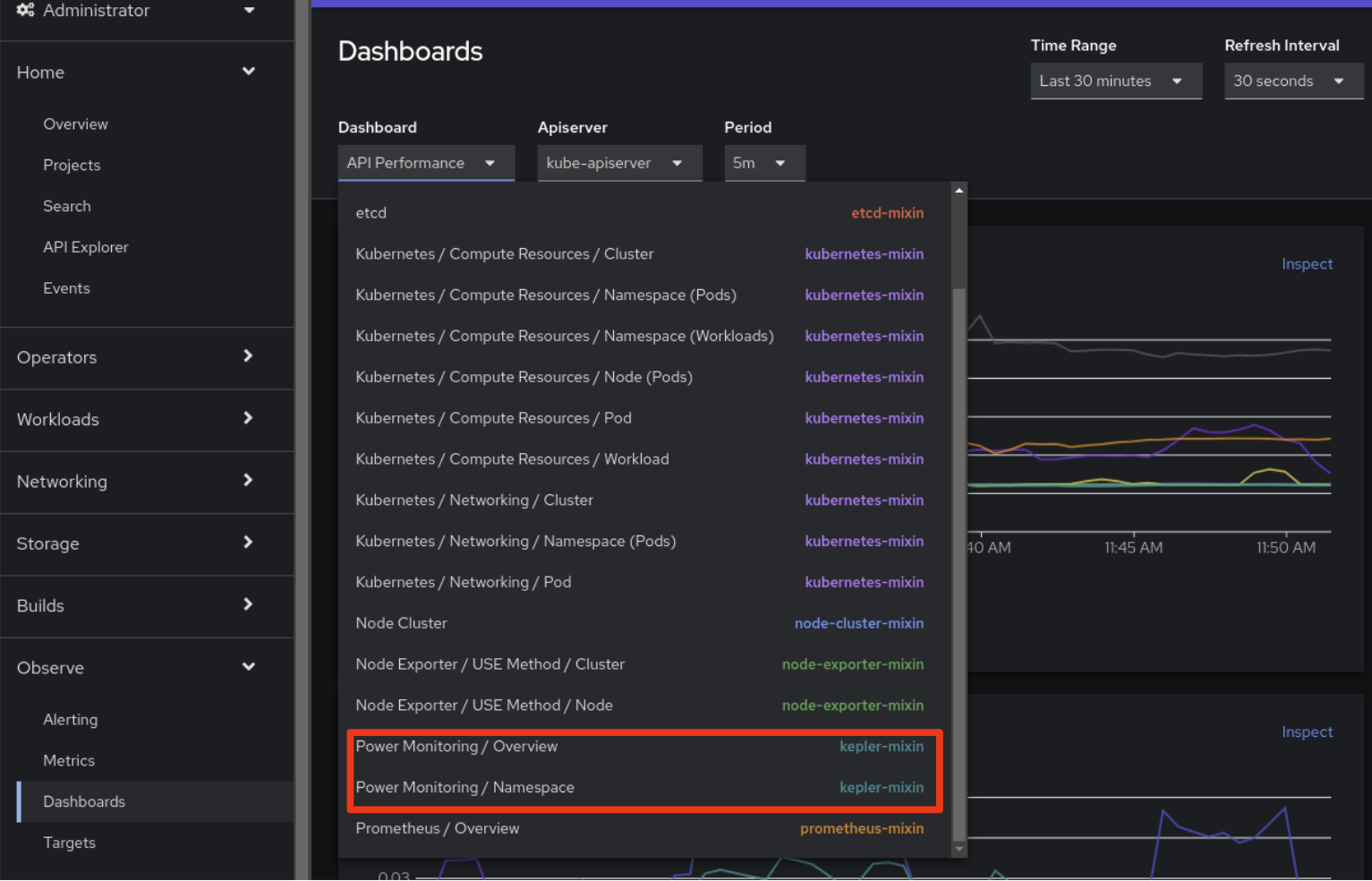
Para obtener más información sobre la supervisión de energía, se recomienda encarecidamente leer la documentación oficial sobre la función en los documentos de OpenShift.
El poder de la supervisión
Al usar estos paneles, podrá obtener la siguiente información sobre el clúster y sus cargas de trabajo:
- Supervise la energía total que se consumió en su clúster durante las últimas 24 horas y acceda a información sobre la arquitectura de la CPU seleccionada y la cantidad de nodos supervisados.
- Consulte un desglose de los espacios de nombres que consumen más energía.
- Conozca los contenedores y los pods que consumen la mayor cantidad de energía. Esto se puede lograr analizando los indicadores expuestos por Kepler en la pestaña "Observe -> Metrics".
- Recomendación de los especialistas: puede consultar todos los indicadores disponibles en la función con esta expresión regular: { __name__ =~ "kepler.+"}.
Como se mencionó anteriormente, la incorporación de Kepler en OpenShift hace que estos indicadores estén disponibles. El conjunto de indicadores que obtiene Kepler depende en gran medida del hardware fundamental y de la configuración del clúster. En la actualidad, Kepler proporciona mediciones precisas de un conjunto determinado de configuraciones de la nube, específicamente aquellas basadas en el hardware de Intel capaz de exponer el límite de potencia promedio en funcionamiento (RAPL) y la configuración avanzada y la interfaz de energía (ACPI) en las implementaciones en servidores dedicados (bare metal).
Para otras configuraciones, se proporciona un modelo de machine learning (aprendizaje automático) inicial. Red Hat trabaja con la comunidad en general para mejorar aún más la precisión de los estimadores basados en dicha tecnología. Por el momento, las estimaciones demuestran ser uniformes, es decir que puede confiar en que le mostrarán las variaciones entre distintas ejecuciones de la misma carga de trabajo. Sin embargo, es importante tener en cuenta que son aproximaciones del consumo de energía real.
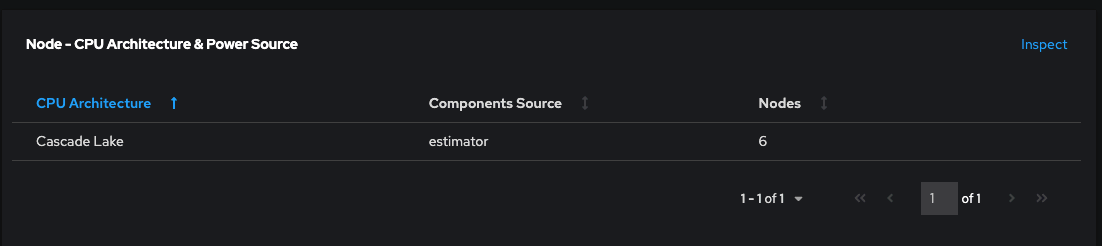
Para ayudar a nuestros usuarios a comprender si los valores que Kepler proporciona de manera predeterminada están basados en indicadores o en modelos, agregamos una columna adicional denominada "Components Source" en el panel "Node - CPU Architecture" de la página "Overview".
Esta mejora proporciona transparencia, ya que permite que los usuarios vean de dónde provienen los indicadores, como rapl-sysfs o rapl-msr. Si Kepler no puede obtener los indicadores de consumo de energía del hardware, se mostrará "estimator" como fuente. En tales casos, Kepler recurre al modelo de machine learning y a los estimadores resultantes mencionados anteriormente. Las iniciativas de desarrollo en curso se centran en perfeccionar estos modelos para mejorar tanto la precisión como el alcance de los entornos que pueden abordar.
Exploración de los indicadores
Entonces, ¿qué aspecto tiene? Profundicemos con un ejemplo. Después de instalar Kepler siguiendo la documentación oficial, instalamos un generador de tráfico HTTP/2 y una simulación, y colocamos un poco de carga en el sistema.
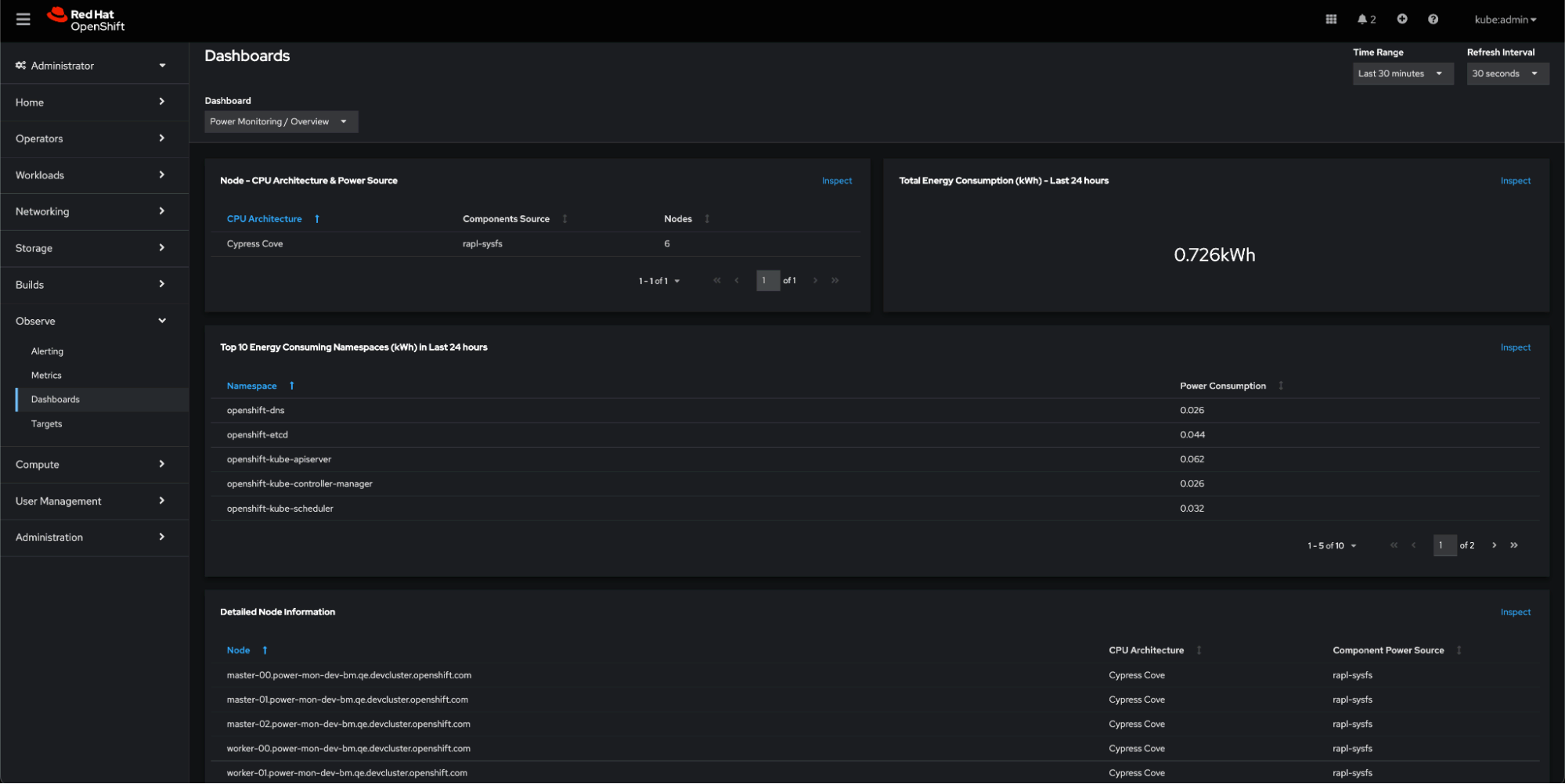
Ahora, veamos el impacto del consumo de energía en nuestro clúster de OpenShift. Si nos dirigimos al panel "Observe -> Dashboards -> Power Monitoring Overview" en la consola de OpenShift, podemos ver que ahora:
- Los nodos que se muestran en el panel "Architecture" informan los resultados basados en los indicadores, ya que dicho panel muestra rapl-sysfs en la columna "Components Source".
- El clúster estuvo en funcionamiento durante un tiempo, pero inactivo, por lo que no consumió tantos kWh.
- También se muestra una lista de los espacios de nombres que más contribuyen a la factura de energía.
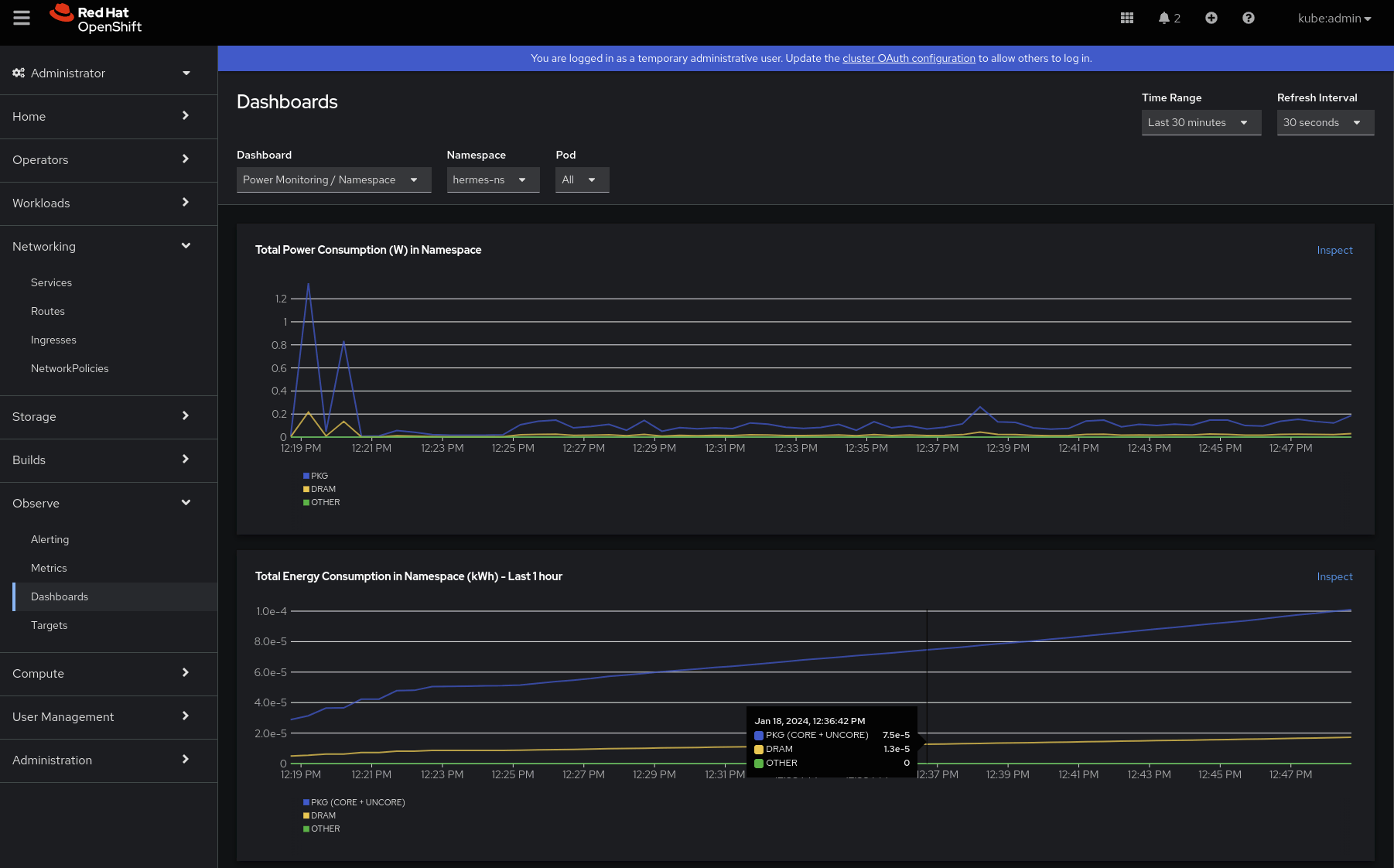
¿Qué más? Queremos comprender los perfiles de potencia y consumo de energía, así que profundicemos en el segundo panel: "Power Monitoring / Namespace". Después de seleccionar el espacio de nombres que nos interesa (hermes-ns):
- Lo primero que se puede observar es que, después de un par de picos, el consumo de energía en vatios es constante a lo largo del tiempo, y el principal consumidor es el elemento PKG. El dominio Package (PKG) mide el consumo de energía de todo el socket. Incluye el consumo de todos los núcleos, los gráficos integrados y también los elementos no centrales, como las cachés de último nivel o el controlador de memoria. Esto parece correcto, y no se encuentran acumulaciones, ya que el consumo de energía es la tasa de la energía.
- También podemos ver que el consumo de energía aumenta con el tiempo. El consumo de energía de la DRAM (que mide el consumo de energía de la RAM conectada al controlador de memoria integrado) parece insignificante en este caso.
Si nos desplazamos un poco hacia abajo, podemos analizar más a fondo, por contenedor, el consumo de PKG y la DRAM. Lo primero que llama la atención es que los primeros picos parecen ser consecuencia de una carga de trabajo anterior. Eso suena interesante, y quizás debamos depurarlo en nuestra aplicación o simulación.
Después de que la segunda implementación esté lista, podremos observar que ambos contenedores contribuyen por igual al consumo de energía.
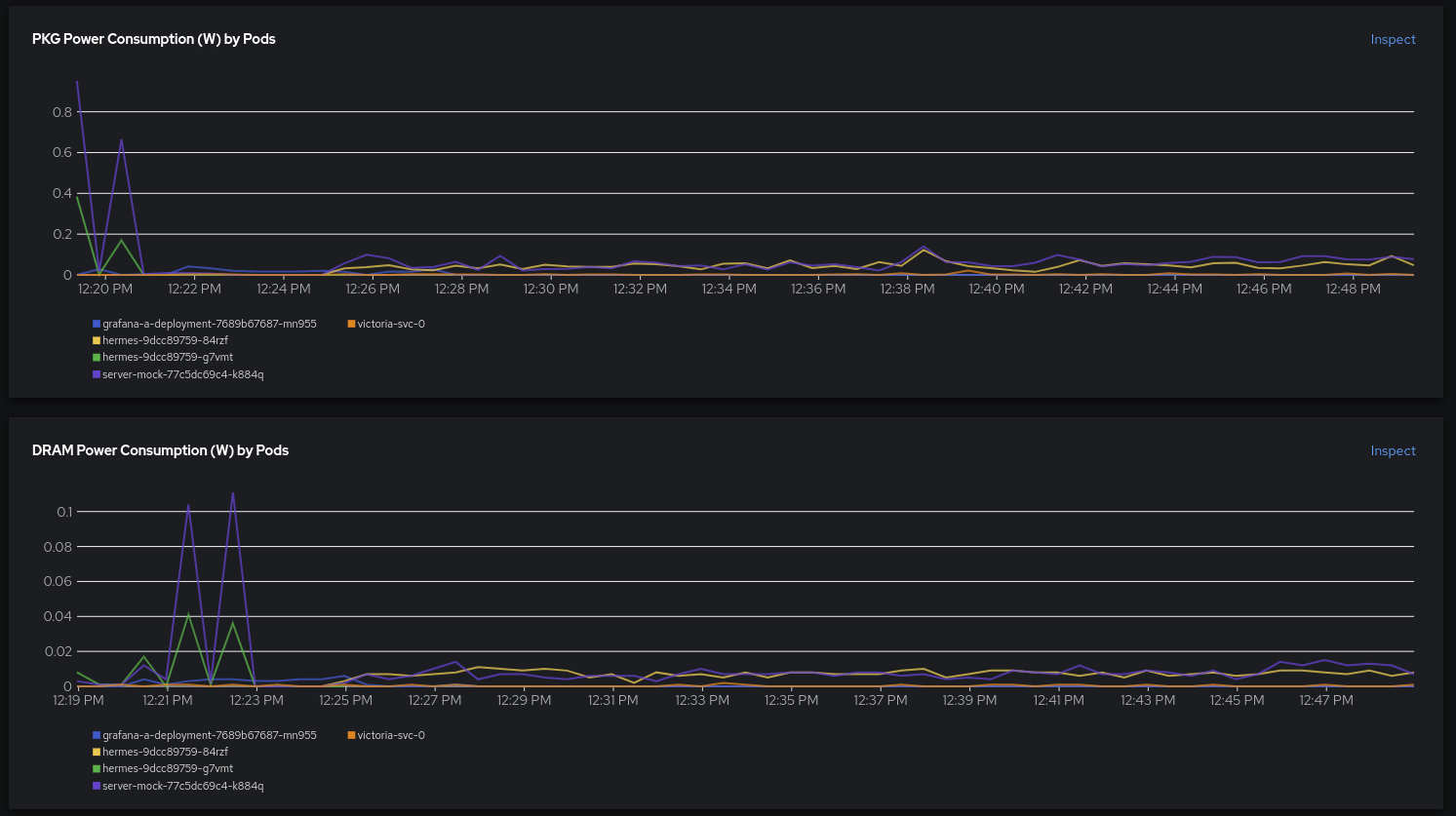
¿Qué nos dice esto? ¿Significa que un generador de tráfico con algún tipo de lógica compleja e instrumentalización con OpenTelemetry, indicadores y herramientas de seguimiento consume la misma cantidad de energía que una simulación sencilla que solo dice "200 OK" y lo imprime en la consola? Si bien nos encantan las funciones modernas de determinación del estado interno de los sistemas, aún es necesario realizar una impresión de los resultados estándares de vez en cuando.
func exampleHandler(w http.ResponseWriter, r *http.Request) {
time.Sleep(2 * time.Millisecond)
fmt.Println("Request received. URI:", r.RequestURI, "Method:", r.Method)
w.WriteHeader(200)
}El generador de tráfico está escrito en C++, y la simulación en Go. Según estudios recientes, bajo ciertas condiciones, C++ puede ser más eficiente energéticamente que Go por un factor de 2,5, pero ese debate está mucho más allá del alcance de este blog. Nos encantan todos los lenguajes, y cada uno tiene sus puntos fuertes. Estamos ansiosos por ver las formas en que usará la supervisión de energía. Tal vez, incluso, pueda analizar los lenguajes de programación y el consumo de energía a partir de sus propios datos.
Próximos pasos
Seguimos comprometidos a incorporar sus comentarios, realizar ajustes e introducir mejoras. Nuestra colaboración con la comunidad continuará, lo que contribuirá a la iniciativa global para supervisar de manera más eficaz el consumo de energía. Las perspectivas son prometedoras, con posibles planes que van desde integrar la supervisión de la energía en iniciativas de sostenibilidad más amplias, hasta ayudar a los desarrolladores a supervisar su código dentro de la plataforma OpenShift o exportar datos a través de OpenTelemetry.
Recursos relacionados
- Documentación oficial de Red Hat OpenShift
- Introducing developer preview of Kepler: power monitoring for Red Hat OpenShift
- https://sustainable-computing.io/
- Exploring Kepler’s potentials: unveiling cloud application power consumption | CNCF
- Which Programming Languages Use the Least Electricity? - The New Stack
- Developer Preview Support Scope - Portal de clientes Red Hat
- Technology Preview Features - Scope of Support - Portal de clientes Red Hat
- Developer and Technology Previews: How they compare - Portal de clientes Red Hat
- Enabling monitoring for user-defined projects | Supervisión | Red Hat OpenShift Platform 4.14
Sobre el autor

Jose is a Senior Product Manager at Red Hat OpenShift, with a focus on Observability and Sustainability. His work is deeply related to manage the OpenTelemetry, distributed tracing and power monitoring products in Red Hat OpenShift.
His expertise has been built from previous gigs as a Software Architect, Tech Lead and Product Owner in the telecommunications industry, all the way from the software programming trenches where agile ways of working, a sound CI platform, best testing practices with observability at the center have presented themselves as the main principles that drive every modern successful project.
With a heavy scientific background on physics and a PhD in Computational Materials Engineering, curiousity, openness and a pragmatic view are always expected. Beyond the boardroom, he is a C++ enthusiast and a creative force, contributing symphonic and electronic touches as a keyboardist in metal bands, when he is not playing videogames or lowering lap times at his simracing cockpit.
Más similar
Navegar por canal

Automatización
Las últimas novedades en la automatización de la TI para los equipos, la tecnología y los entornos

Inteligencia artificial
Descubra las actualizaciones en las plataformas que permiten a los clientes ejecutar cargas de trabajo de inteligecia artificial en cualquier lugar

Nube híbrida abierta
Vea como construimos un futuro flexible con la nube híbrida

Seguridad
Vea las últimas novedades sobre cómo reducimos los riesgos en entornos y tecnologías

Edge computing
Conozca las actualizaciones en las plataformas que simplifican las operaciones en el edge

Infraestructura
Vea las últimas novedades sobre la plataforma Linux empresarial líder en el mundo

Aplicaciones
Conozca nuestras soluciones para abordar los desafíos más complejos de las aplicaciones

Programas originales
Vea historias divertidas de creadores y líderes en tecnología empresarial