
Em outubro do ano passado, anunciamos a apresentação prévia do monitoramento de energia do Red Hat OpenShift para desenvolvedores, revelando o Kepler como componente essencial da iniciativa de computação sustentável da comunidade upstream. Essa iniciativa permite que os primeiros usuários experimentem essa tecnologia promissora. Desde o anúncio, nossa equipe tem se esforçado para criar pipelines e ferramentas que atendam aos padrões de segurança e teste das soluções Red Hat.
Hoje, temos o prazer de compartilhar um novo marco nessa jornada: o lançamento da apresentação prévia do monitoramento de energia do Red Hat OpenShift. Nossos sinceros agradecimentos aos primeiros usuários e a todos apaixonados por tecnologia disruptiva que participaram ativamente na implantação do monitoramento de energia e compartilharam feedbacks inestimáveis.
Para quem ainda não teve a chance de experimentar o monitoramento de energia do Red Hat OpenShift, ele é um conjunto de ferramentas que permite monitorar o consumo de energia das cargas de trabalho em execução em um cluster do OpenShift. Essas informações podem ser úteis para várias finalidades, como identificar os namespaces que consomem mais energia ou formular um plano estratégico para minimizar o consumo de energia.
Se você tiver interesse em testar essa versão prévia, veja abaixo como começar. Leia a declaração de apresentação prévia da tecnologia para ter mais informações sobre o suporte oficial.
Como instalar o monitoramento de energia do Red Hat OpenShift
Nosso objetivo é oferecer uma experiência unificada. Assim, essas etapas de instalação são muito semelhantes às da versão anterior do monitoramento de energia, que dependia do operador da comunidade.
- Para habilitar o monitoramento de cargas de trabalho do usuário, siga as instruções fornecidas na documentação do Red Hat OpenShift.
- Para evitar conflitos desnecessários, primeiro desinstale a versão antiga do kepler-operator instalada pelo catálogo de operadores da comunidade.
- Instale o operador do console do OpenShift 4.14 (e superior) navegando até Operators -> OperatorHub. Em seguida, use a caixa de pesquisa para localizar o monitoramento de energia do Red Hat OpenShift, clique nele e, depois, na caixa "Install".
- Quando o operador estiver instalado, crie uma instância da definição de recursos personalizados do Kepler clicando em "View Operator" e, depois disso, em "Create instance" na API do Kepler.
Concluído. Após instalar o Kepler, dois novos dashboards ficarão disponíveis na IU da aba “Observe>Dashboards” no console do OpenShift:
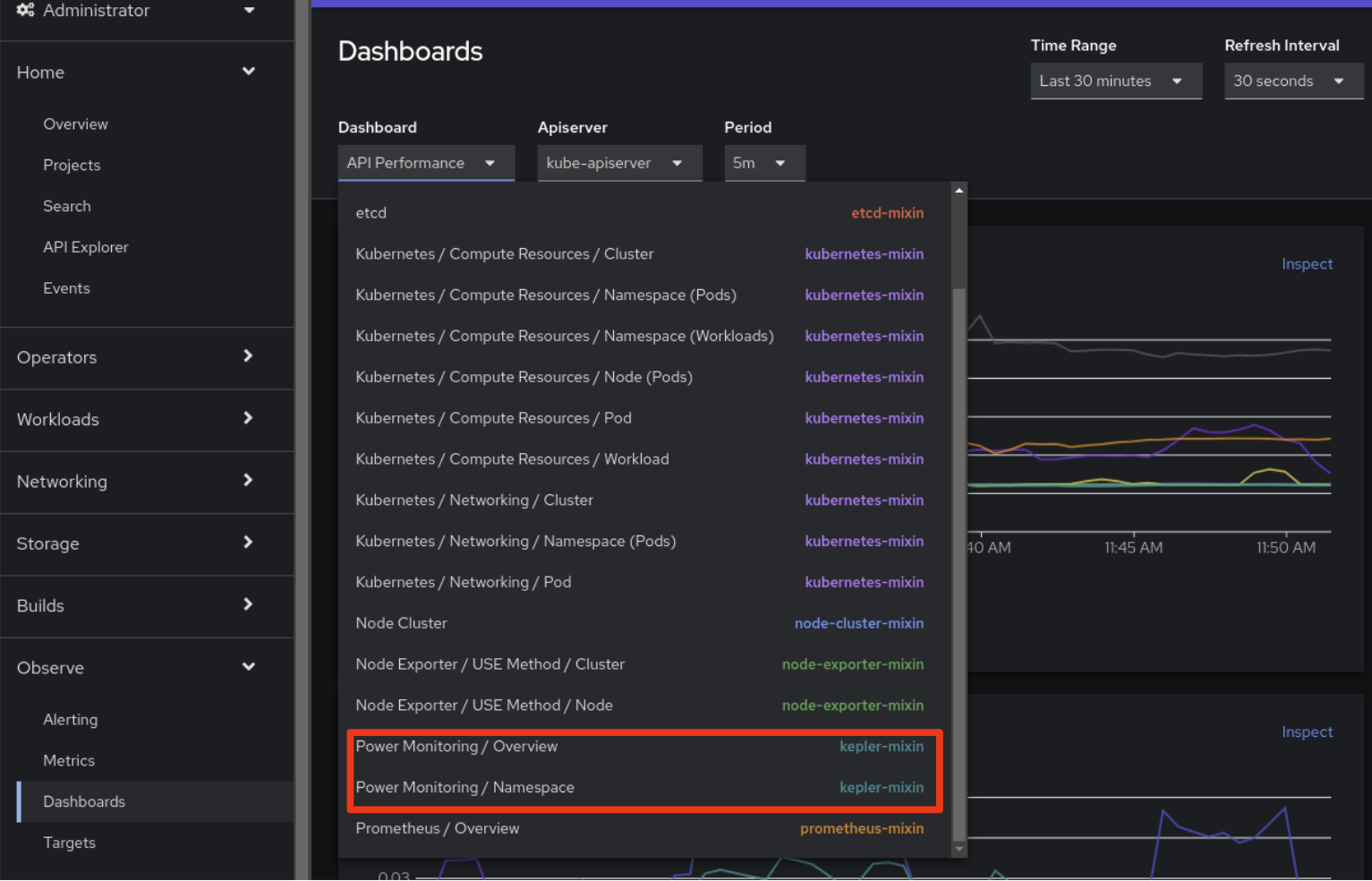
Para mais informações sobre o monitoramento de energia, leia a documentação oficial nos documentos do OpenShift.
O poder do monitoramento
Esses dashboards oferecem os seguintes insights sobre o cluster e suas cargas de trabalho:
- Monitore a energia total consumida no cluster nas últimas 24 horas, incluindo uma indicação da arquitetura de CPU selecionada e o número de nós monitorados.
- Veja um detalhamento dos principais namespaces que consomem energia.
- Entenda quais containers e pods estão consumindo a maior quantidade de energia. Para fazer isso, você pode analisar as métricas exibidas pelo Kepler na aba "Observe -> Metrics".
- Dica de especialista: para consultar todas as métricas disponíveis de monitoramento de energia, use esta expressão regular: { __name__ =~ "kepler.+"}
Como mencionado, a incorporação do Kepler no OpenShift disponibiliza essas métricas. O conjunto de métricas obtido pelo Kepler depende muito do hardware subjacente e da configuração do cluster. Atualmente, o Kepler oferece medições precisas de um conjunto específico de configurações de nuvem, em especial as baseadas em hardware Intel capaz de exibir o limite médio de energia em execução (RAPL) e a interface avançada de configuração e energia (ACPI) em implantações bare metal.
Para outras configurações, há um modelo inicial de Machine Learning, e a Red Hat está trabalhando com toda a comunidade para melhorar ainda mais a precisão dos estimadores baseados em machine learning. Hoje, essas estimativas são consistentes e confiáveis, mostrando variações entre as execuções da mesma carga de trabalho. No entanto, é importante observar que elas são aproximações do consumo real de energia.
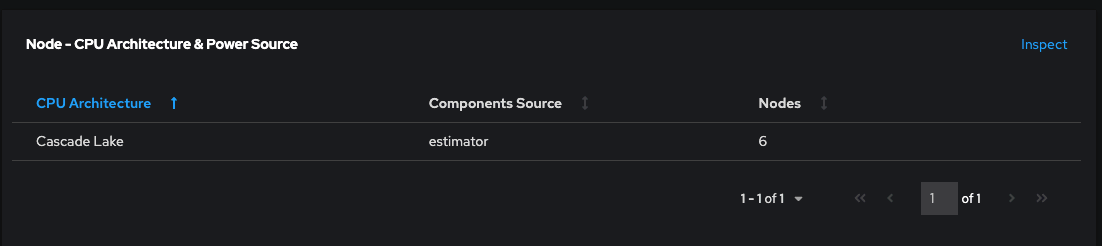
Para os usuários entenderem com mais facilidade se o Kepler está fornecendo como padrão valores baseados em métricas ou valores baseados em modelos, adicionamos uma coluna extra chamada "Components Source" no painel Node - CPU Architecture, na página Overview.
Essa melhoria oferece transparência, permitindo que os usuários vejam a origem dessas métricas, como rapl-sysfs ou rapl-msr. Se o Kepler não puder obter métricas de consumo de energia de hardware, ele exibirá "estimator" como a fonte. Nesses casos, o Kepler recorre ao modelo de Machine Learning e aos estimadores resultantes mencionados. As iniciativas de desenvolvimento contínuo estão focadas em refinar esses modelos para melhorar a precisão e abrangência das áreas de ocupação que eles podem analisar.
Como explorar as métricas
Então, como são as métricas? Vamos nos aprofundar com um exemplo. Depois de instalar o Kepler seguindo a documentação oficial, instalamos um gerador de tráfego HTTP/2 e um simulado e colocamos um pouco de carga no sistema.
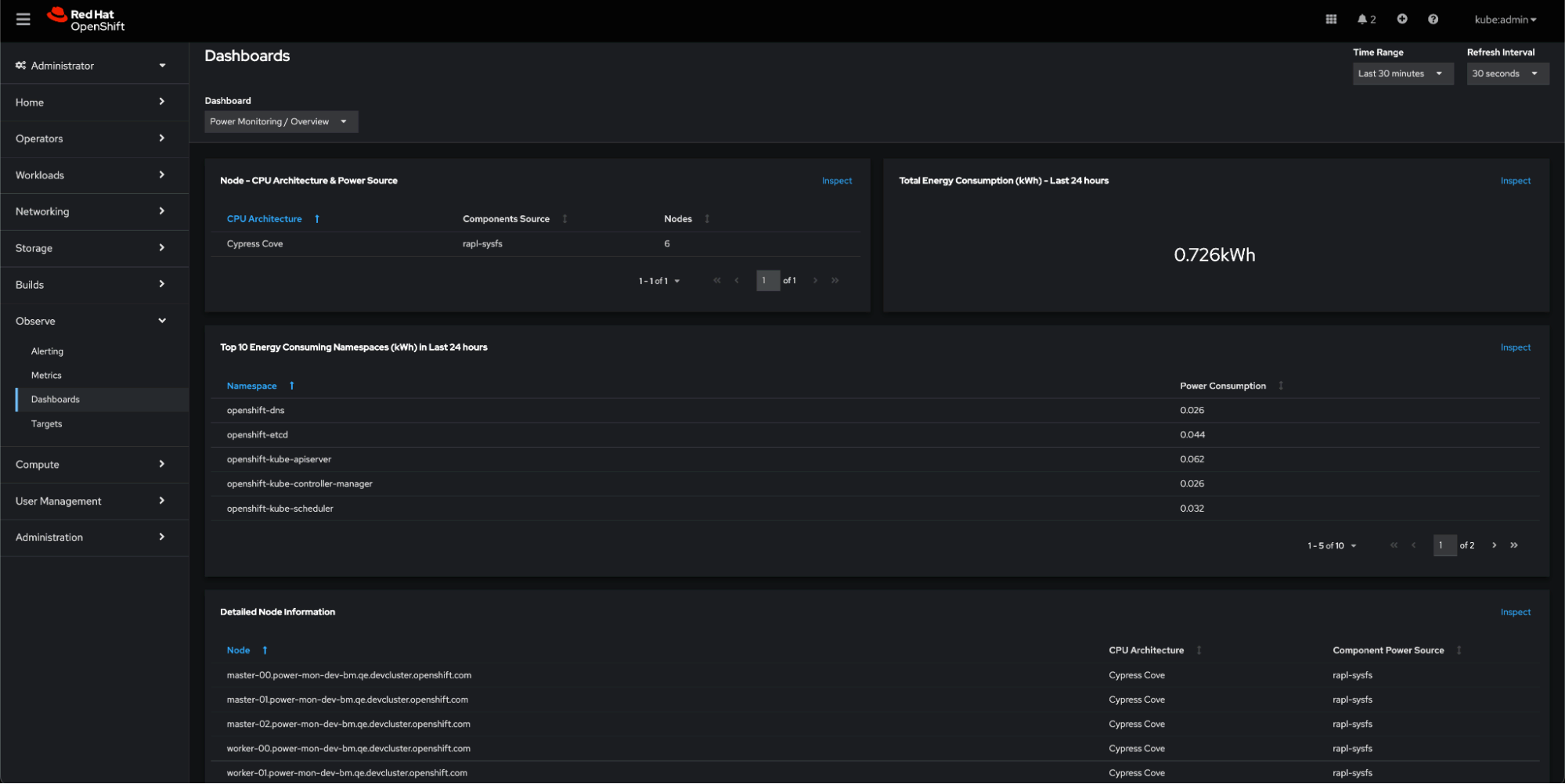
Agora, veremos o impacto do consumo de energia no cluster do OpenShift. Se formos até o dashboard Observe -> Dashboards -> Power Monitoring Overview, poderemos ver que agora:
- Os nós mostrados no painel Architecture estão relatando resultados baseados em métrica, como mostrado em rapl-sysfs na coluna Components Source.
- O cluster está operando há um tempo, mas sem atividade, então o consumo de kWh foi baixo.
- Também é exibida uma lista dos namespaces que mais contribuem para a conta de energia.
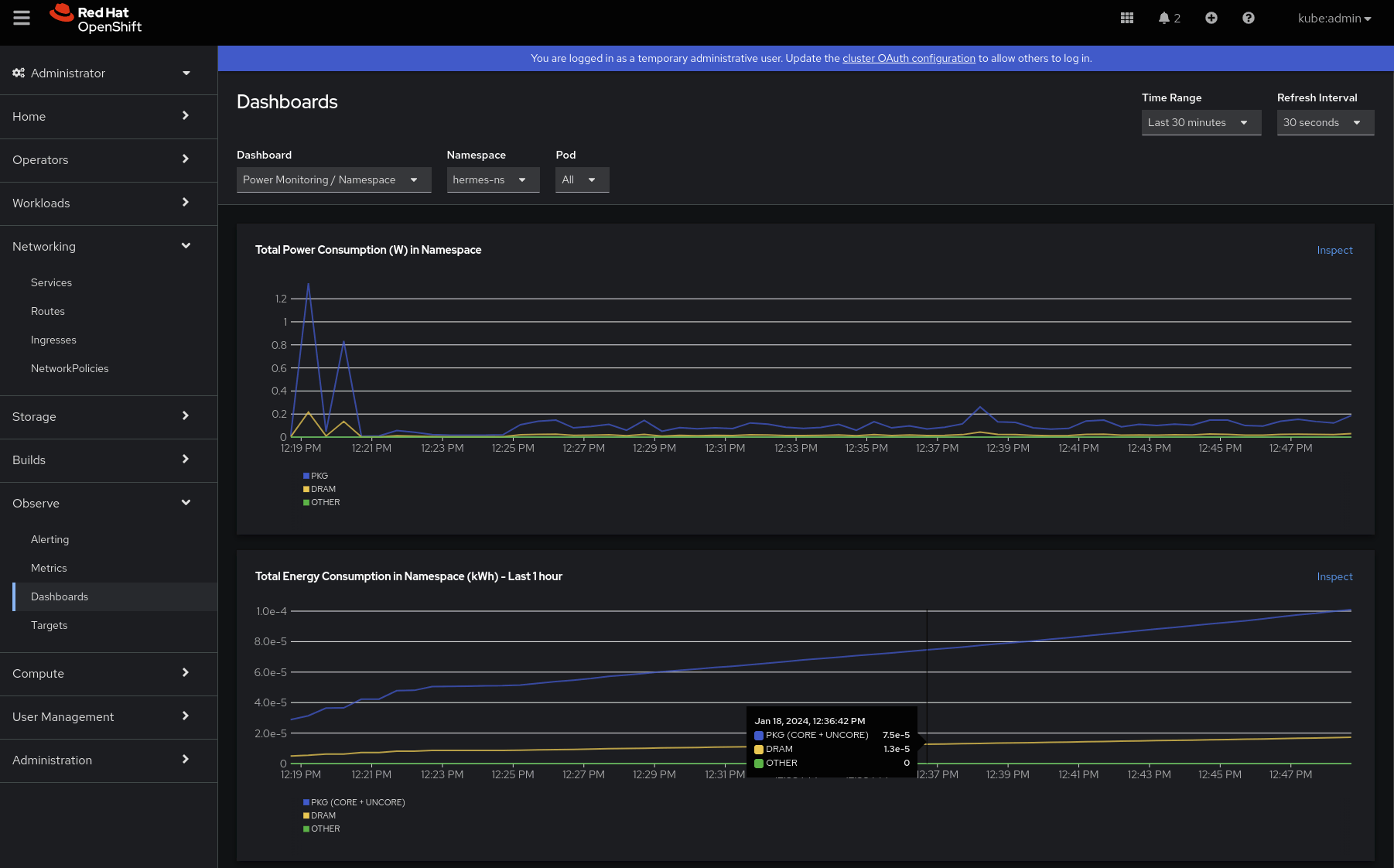
O que mais? Queremos entender os perfis de consumo de energia. Por isso, vamos nos aprofundar no segundo dashboard: "Power Monitoring / Namespace". Após selecionar o namespace que queremos (hermes-ns):
- A primeira coisa que pode ser observada é que, após alguns picos, o consumo de energia em watts se estabiliza, e o principal motivo é o componente PKG. Package (PKG) mede o consumo de energia de todo o soquete. Ele inclui o consumo de todos os núcleos, dos gráficos integrados e dos componentes não essenciais (caches de último nível, controlador de memória). Os dados parecem corretos e não vemos nenhum acúmulo, já que o consumo de energia é a taxa da energia.
- Também é possível ver que o consumo de energia está aumentando com o tempo. Nesse caso, é pequena a contribuição de energia da DRAM (que mede o consumo de energia da RAM conectada ao controlador de memória integrado).
Descendo um pouco a página, podemos analisar melhor as contribuições do PKG e da DRAM por container. O que logo chama a atenção são os primeiros picos, que parecem ser causados por uma carga de trabalho anterior. Isso é interessante, e talvez seja necessário depurá-lo na aplicação/simulação.
Após concluir a segunda implantação, observamos que os dois containers contribuem igualmente para o consumo de energia.
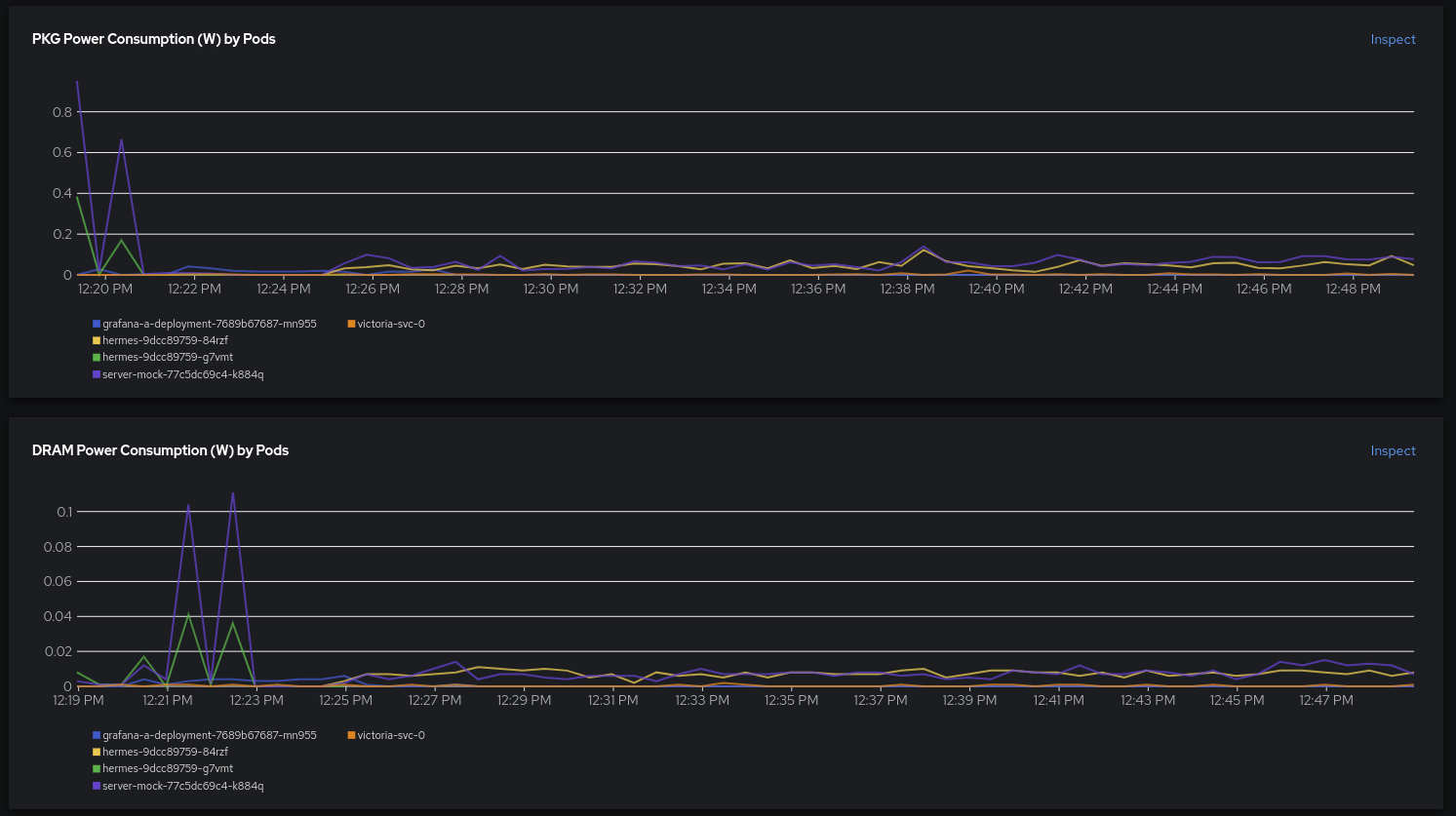
O que isso quer dizer? Isso significa que um gerador de tráfego com lógica complexa e instrumentalização com OpenTelemetry, métricas e rastreamentos está consumindo a mesma quantidade de energia que uma simulação simples que só diz "200 OK" e o imprime no console? Adoramos a observabilidade moderna, mas ainda é preciso fazer uma impressão na saída padrão de vez em quando.
func exampleHandler(w http.ResponseWriter, r *http.Request) {
time.Sleep(2 * time.Millisecond)
fmt.Println("Request received. URI:", r.RequestURI, "Method:", r.Method)
w.WriteHeader(200)
}O gerador de tráfego é escrito em C++, e a simulação em Go. Estudos recentes mostraram que, nas condições certas, o C++ é mais eficiente no consumo de energia do que o Go por um fator de 2,5, mas não pretendemos debater isso aqui. Adoramos todas as linguagens, e cada uma delas tem seu valor. Mal podemos esperar para ver como você vai usar o monitoramento de energia. Talvez você consiga até participar das discussões sobre linguagens de programação e consumo de energia com seus próprios dados em mãos.
Próximas etapas
Continuamos empenhados em aproveitar seu feedback, fazer ajustes e introduzir melhorias. Nossa colaboração com a comunidade continuará existindo, contribuindo com a iniciativa global de monitorar o consumo de energia com mais eficácia. A perspectiva é promissora, com possíveis planos que vão da integração do monitoramento de energia a iniciativas mais amplas de sustentabilidade à ajuda aos desenvolvedores na observação do código na plataforma OpenShift ou na exportação de dados pelo OpenTelemetry.
Leia mais
- Documentação oficial do Red Hat OpenShift
- Introdução à apresentação prévia do Kepler para desenvolvedores: monitoramento de energia do Red Hat OpenShift
- https://sustainable-computing.io/
- Explorando o potencial do Kepler: como revelar o consumo de energia das aplicações em nuvem | CNCF
- Quais linguagens de programação usam menos eletricidade? - O novo stack
- Abrangência do suporte da apresentação prévia para desenvolvedores - Portal do Cliente Red Hat
- Recursos da apresentação prévia de tecnologia - abrangência do suporte - Portal do Cliente Red Hat
- Apresentações prévias de tecnologia e para desenvolvedores: como elas se comparam - Portal do Cliente Red Hat
- Como habilitar o monitoramento para projetos definidos pelo usuário | Monitoramento | Red Hat OpenShift Platform 4.14
Sobre o autor

Jose is a Senior Product Manager at Red Hat OpenShift, with a focus on Observability and Sustainability. His work is deeply related to manage the OpenTelemetry, distributed tracing and power monitoring products in Red Hat OpenShift.
His expertise has been built from previous gigs as a Software Architect, Tech Lead and Product Owner in the telecommunications industry, all the way from the software programming trenches where agile ways of working, a sound CI platform, best testing practices with observability at the center have presented themselves as the main principles that drive every modern successful project.
With a heavy scientific background on physics and a PhD in Computational Materials Engineering, curiousity, openness and a pragmatic view are always expected. Beyond the boardroom, he is a C++ enthusiast and a creative force, contributing symphonic and electronic touches as a keyboardist in metal bands, when he is not playing videogames or lowering lap times at his simracing cockpit.
Navegue por canal

Automação
Últimas novidades em automação de TI para empresas de tecnologia, equipes e ambientes

Inteligência artificial
Descubra as atualizações nas plataformas que proporcionam aos clientes executar suas cargas de trabalho de IA em qualquer ambiente

Nuvem híbrida aberta
Veja como construímos um futuro mais flexível com a nuvem híbrida

Segurança
Veja as últimas novidades sobre como reduzimos riscos em ambientes e tecnologias

Edge computing
Saiba quais são as atualizações nas plataformas que simplificam as operações na borda

Infraestrutura
Saiba o que há de mais recente na plataforma Linux empresarial líder mundial

Aplicações
Conheça nossas soluções desenvolvidas para ajudar você a superar os desafios mais complexos de aplicações

Programas originais
Veja as histórias divertidas de criadores e líderes em tecnologia empresarial
Produtos
- Red Hat Enterprise Linux
- Red Hat OpenShift
- Red Hat Ansible Automation Platform
- Red Hat Cloud Services
- Veja todos os produtos
Ferramentas
- Treinamento e certificação
- Minha conta
- Suporte ao cliente
- Recursos para desenvolvedores
- Encontre um parceiro
- Red Hat Ecosystem Catalog
- Calculadora de valor Red Hat
- Documentação
Experimente, compre, venda
Comunicação
- Contate o setor de vendas
- Fale com o Atendimento ao Cliente
- Contate o setor de treinamento
- Redes sociais
Sobre a Red Hat
A Red Hat é a líder mundial em soluções empresariais open source como Linux, nuvem, containers e Kubernetes. Fornecemos soluções robustas que facilitam o trabalho em diversas plataformas e ambientes, do datacenter principal até a borda da rede.
Selecione um idioma
Red Hat legal and privacy links
- Sobre a Red Hat
- Oportunidades de emprego
- Eventos
- Escritórios
- Fale com a Red Hat
- Blog da Red Hat
- Diversidade, equidade e inclusão
- Cool Stuff Store
- Red Hat Summit